
Mysql - 存储过程/自定义函数
在数据库操作中, 尤其是碰到一些复杂一些的系统, 不可避免的, 会用到函数/自定义函数, 或者存储过程.
实际项目中, 自定义函数和存储过程是越少越好, 因为这个东西多了, 也是一个非常难以维护的地方.
一、自定义函数
1. 例子
mysql提供的函数, 不在这一篇讲了, 这里主要贴一下自定义函数. 前台js插件里面有一个zTree, 不知道大家知不知道, 效果是这样的:

这种结构的数据, 在数据库中, 我一般会设计到一个表中
create table ztree ( id int(11) not null PRIMARY key auto_increment, name varchar(20) not null comment '节点名称', pid int(11) not null comment '父节点id' ) comment '树形表';
然后插入数据:

如果你拿到一个节点A, 想要获取A下面的节点(不只是子节点哦), 那么通过一个自定义函数来做, 能方便许多.
delimiter $ DROP FUNCTIONIF EXISTS GetChildNodes ;
CREATE FUNCTION `GetChildNodes` (`rootId` INT) RETURNS VARCHAR (1000) BEGIN DECLARE res VARCHAR (1000) DEFAULT '-1'; DECLARE temp VARCHAR (1000) DEFAULT CAST(rootId AS CHAR); -- SET res = '' ; -- SET DECLARE = CAST(rootId AS CHAR) ; WHILE temp IS NOT NULL DO SET res = CONCAT(res, ',', temp) ; SELECT GROUP_CONCAT(id) INTO temp FROM ztree WHERE FIND_IN_SET(pid, temp) > 0 ; END WHILE ; RETURN res ; END$ delimiter ;
这里, 我将res的值默认为-1, 这样的话, 就可以在查询的时候, 将这个结果拼入sql中, 还是比较方便的.
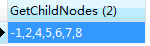
mysql中, 自定义函数的调用, 使用 select, 接下来, 就看一下之前的成果:
SELECT GetChildNodes (2);
2. 语法
自定义函数与存储过程有一个很明显的地方, 就是, 自定义函数是有返回值的, 并且需要通过return的方式返回. 而存储过程没有return返回值. 但是, 程序在执行存储过程的时候, 其实是可以得到一个结果集的.
语法:
create function 函数名 (参数名 参数类型) returns 参数类型
begin
return result;
end
1) 自定义函数传参与存储过程不同, 不需要指定 in/out.
2) 自定义函数可以用到别的sql语句中, 可以单独使用, 也可以混入别的sql中使用
二、存储过程
既然前面已经讲了自定义函数的语法, 那这里就先上存储过程的语法, 以便比较
1. 语法
CREATE PROCEDURE 存储过程名称 (IN 参数名 参数类型, OUT 参数名 参数类型)
begin
end
这里的参数都是非必须的, 可以有 IN/OUT 都是可以没有的
从语法格式上看, 与自定义函数的框架大致是一样的, 只是其中的细节不同.
1) 存储过程没有return返回值, 但是却可以通过OUT的方式, 来修改传入的参数, 可以当做是一种返回值,
2) 存储过程在end之前, 可以加上一句 select语句, 以便程序读取到结果集. 所以存储过程能返回的值其实更多
3) 并不能混入别的sql中使用, 只能通过 call 的方式, 单独使用
2. 例子
之前的项目中, 我碰到一个生成流水号的功能. 当时, 我是通过借助数据库的方式, 来生成流水号的.
我这里的流水号, 由前缀, 时间, 流水码 三部分组成
先建一张流水号表
CREATE TABLE `serialno` ( `Id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Id', `Pre` varchar(10) NOT NULL COMMENT '编号', `Description` varchar(10) DEFAULT NULL COMMENT '说明', `Res` varchar(20) DEFAULT NULL COMMENT '流水号(不加编号的)', PRIMARY KEY (`Id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COMMENT='流水号表'
有了这张表, 就可以开始存储过程了.
delimiter $ drop PROCEDURE if EXISTS p_GetSerialNo; CREATE PROCEDURE `p_GetSerialNo`(IN preValue VARCHAR(10), IN preDate VARCHAR(10),IN des varchar(20), in length int) BEGIN DECLARE t_error INT DEFAULT 0; DECLARE resValue VARCHAR(20) DEFAULT NULL; -- DECLARE -- CONTINUE HANDLER FOR SQLEXCEPTION, -- SQLWARNING, -- NOT FOUND -- SET t_error = 1; START TRANSACTION; SELECT Res INTO resValue FROM serialno WHERE Pre=preValue; IF resValue IS NULL THEN SET resValue= CONCAT(preDate, LPAD(1, length, '0')); INSERT INTO serialno (Pre, Description, Res) VALUES (preValue, des, resValue); ELSE IF preDate = (SUBSTRING(resValue,1,8) + '0') THEN SET resValue = CAST(resValue AS SIGNED) + 1; if preDate <> SUBSTRING(resValue,1,8) THEN set t_error = -1; end if; ELSE SET resValue= CONCAT(preDate, LPAD(1, length, '0')); END IF; UPDATE serialno SET Res = resValue WHERE Pre = preValue; END IF; #IF t_error = 1 then IF @@error_count <> 0 | t_error <> 0 THEN ROLLBACK; select t_error; ELSE COMMIT; SELECT CONCAT(preValue, resValue); END IF; END $ delimiter ;
这里的参数preValue为前缀, preDate为8位的日期,格式如:"20161227", 参数des为说明, 此处并不参与逻辑, 只是更新一个字段. 最后一个length字段, 表示流水号的位数. 流水号的位数不能设置的太过小, 得视业务来确定. 当流水号溢出时, 会返回-1.
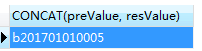
OK, 来看一下效果:
call p_GetSerialNo( 'b', '20170101', 'b', 4);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号