elasticsearch7.6.2 - rest指令
一. 前言
最近闲赋在家, 准备对以前项目中使用的一些技术, 进行一次总结. 故有了这篇小文
elasticsearch在管理类项目中, 用的少, 但是在商品类项目中, 用的还是很多的. 我们在项目中, 会将 canal 配合着elasticsearch来使用.
(canal 会将自己伪装成 mysql 的slave, 他会去读取 mysql 日志, 然后可以进行 elasticsearch 的更新操作. 这种方式是一种实时的方式, 对我们的项目没有侵入性, 还是比较好的一种方式)
(我们项目用的是es6, canal目前稳定版本也只是支持到 es6, 如果是 es7, 谨慎使用canal)
二. 工具
自己在使用elasticsearch的时候, 造数据是一件比较麻烦的事, 费事又费力. 这里推荐使用狂神写的一款爬虫.
造数据就比较轻松了.
这里还是用到了一款软件, 来对elasticsearch 进行查询和操作: kibana
狂神说java : https://space.bilibili.com/95256449?spm_id_from=333.788.b_765f7570696e666f.2
工具地址: https://gitee.com/elvinle/jd_pachong.git
es这个软件是歪果仁开发的, 所以对中文的支持并不好, 我们还需要下载一个 ik 分词器: https://github.com/medcl/elasticsearch-analysis-ik
三. 软件安装:
version: '3'
services:
elasticsearch:
image: elasticsearch:7.6.2
container_name: elasticsearch
user: root
environment:
- "cluster.name=elasticsearch" #设置集群名称为elasticsearch
- "discovery.type=single-node" #以单一节点模式启动
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" #设置使用jvm内存大小
volumes:
- /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins #插件文件挂载
- /mydata/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载
ports:
- 9200:9200
- 9300:9300
kibana:
image: kibana:7.6.2
container_name: kibana
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
environment:
- "elasticsearch.hosts=http://es:9200" #设置访问elasticsearch的地址
ports:
- 5601:5601
这里采用 docker-compose 的方式, docker 和 docker-compose 的安装, 就不在这里写了.
我们将 ik 分词器下载下来之后, 解压到 /mydata/elasticsearch/plugins/ik 目录中
四. 建索引库
建索引库, 类似于mysql建表一样. es有两种建库方式:
1). es默认建库, 无需开发人员手动指定字段信息
2). 手动建库(推荐)
1. 自动建库的方式:
PUT /索引名/_doc/文档id 文档内容 json 串
这种方式虽然方便, 但是在后面进行term索引的时候, 会有一定的问题.
因为这种默认的方式, 并不会进行ik分词
可以通过 GET /lisen 来看一下索引库结构:
{
"lisen" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"hobby" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"work" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1603160907639",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "5Yt2WsBfQK2Iv2IAEDmN1Q",
"version" : {
"created" : "7060299"
},
"provided_name" : "lisen"
}
}
}
}
2. 手动建库(推荐)
#建表语句, img, price 都是默认的, title进行了ik分词处理, 否则在查询的时候, 对中文不是很支持
PUT /jd_goods
{
"mappings": {
"properties" : {
"img" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"price" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"analyzer": "ik_max_word"
}
}
}
}
后续的操作, 我会对 jd_goods 库和 lisen 库进行. 比较的方式看, 会比较明显.
jd_goods的数据, 是从jd爬取的, 比较方便, 所以这边不对 jd_goods 库进行增删改 操作.
五. 增删改查
1. 前置知识
es推荐使用 rest 调用接口的方式来操作. 其操作方式有以下几种:
#PUT 索引名/_doc/文档id 创建文档-指定id #POST 索引名/_doc 创建文档-随机id #POST 索引名/_update/文档id 修改文档 #DELETE 索引名/_doc/文档id 删除文档 #GET 索引名/_doc/文档id 通过id获取文档 #POST 索引名/_search 查询所有数据
常用数据类型有以下几种:
#字符串类型 text keyword #数值类型 long integer short byte double float, half float, scaled float #日期类型 data #布尔类型 boolean #二进制类型 binary
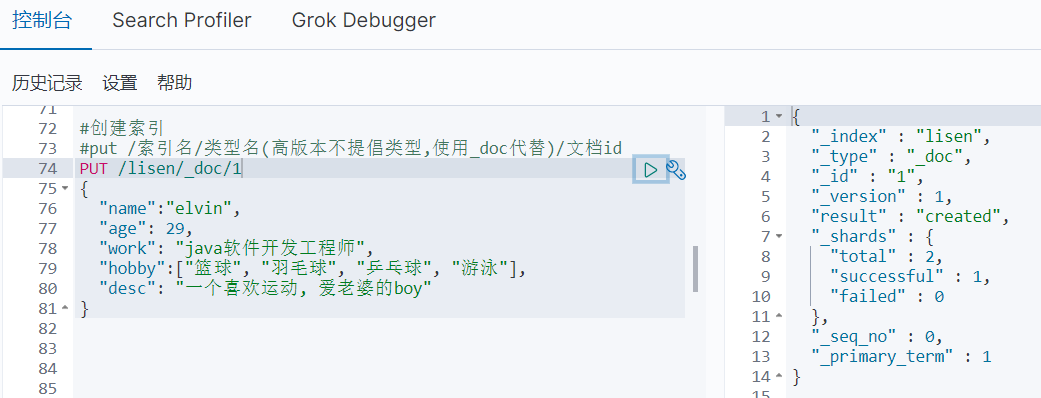
附初始数据语句:
PUT /lisen/_doc/1
{
"name":"elvin",
"age": 29,
"work": "java软件开发工程师",
"hobby":["篮球", "羽毛球", "乒乓球", "游泳"],
"desc": "一个喜欢运动, 爱老婆的boy"
}
PUT /lisen/_doc/2
{
"name":"john",
"age": 27,
"work": "前端开发工程师",
"hobby":["骑电瓶车", "羽毛球"],
"desc": "一个很刚的帅小伙"
}
PUT /lisen/_doc/3
{
"name":"sury",
"age": 35,
"work": "测试工程师",
"hobby":["带娃", "乒乓球"],
"desc": "一个很有想法的小伙"
}
PUT /lisen/_doc/4
{
"name":"主公",
"age": 35,
"work": "测试工程师",
"hobby":["带饭", "游泳"],
"desc": "一个摇摆不定的小伙"
}
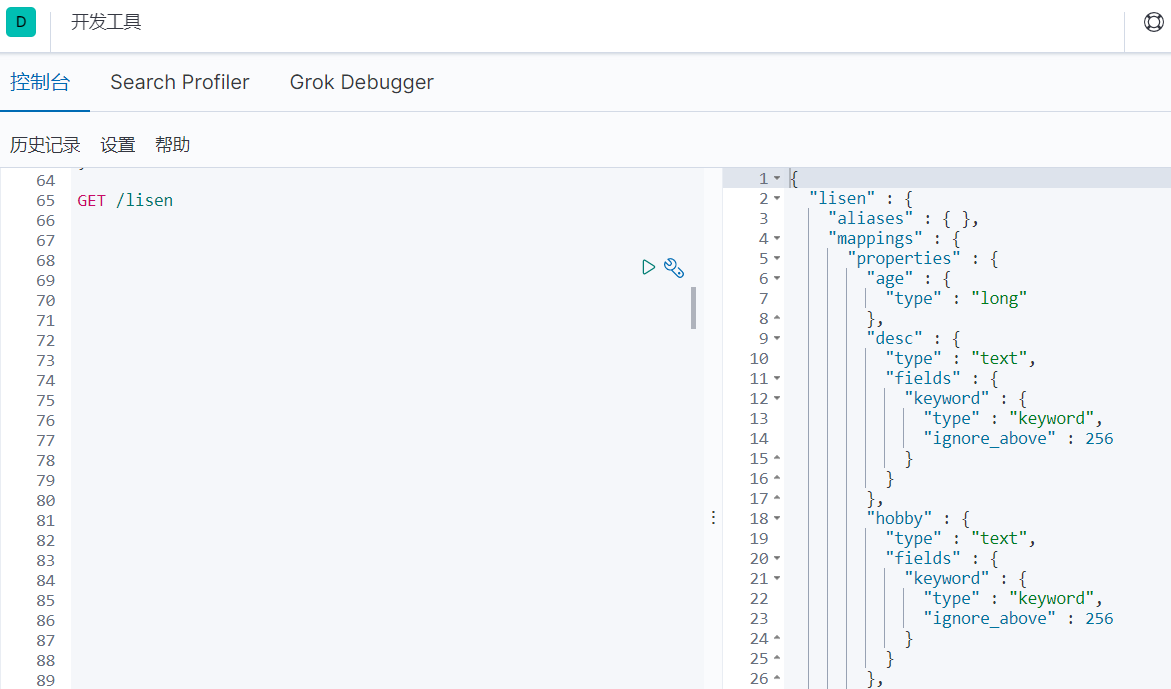
2. GET
GET /库名
可以获取建库信息
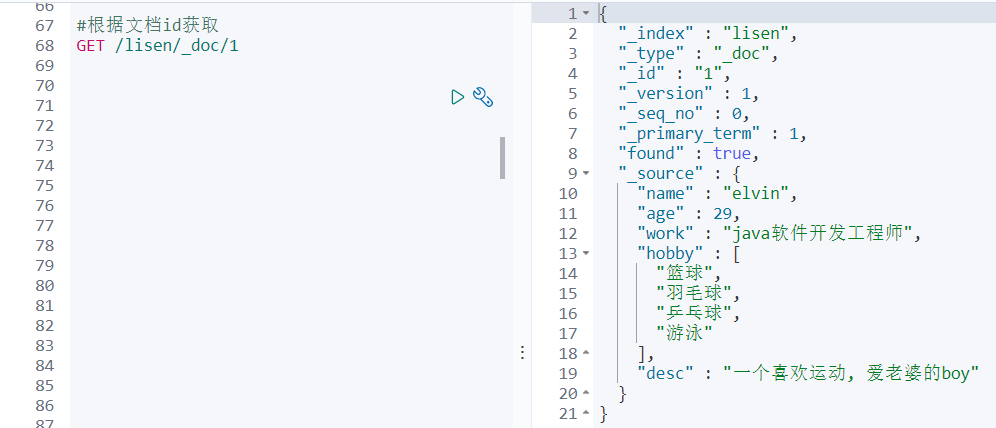
GET /库名/_doc/文档id
根据文档id获取信息, 相当于 select * from 库名 where id = #{id}
3. DELETE
DELETE /库名
直接删索引库, 删除之后, 再 get 就回报错

此时再 get 一下

es会返回 404
DELETE /库名/_doc/文档id
根据文档id进行删除
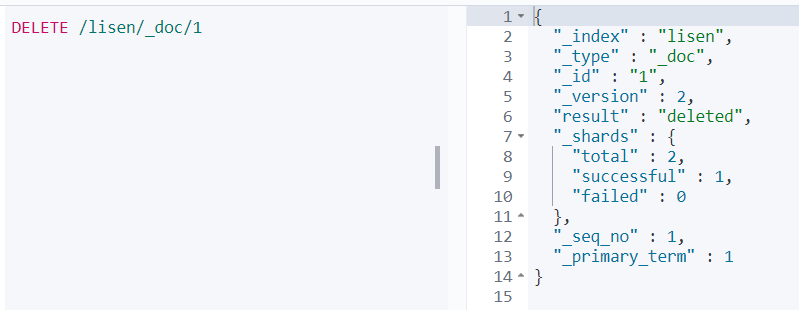
此时再 get 一下

会发现 found = false 了, 找不到了
4. UPDATE
1) PUT方式修改 - 全量修改
2) POST方式修改 - 可以全量, 也可以非全量
PUT /库名/_doc/文档id
PUT 在 restFull 里面代表两个意思: add 和 update, 当没有id时, 新增, 当有id时修改
在这里, 也是一样的. 当有指定的id时, 修改, 当没有指定的id时, 新增
这是一种全量修改方式

这里我没有写 desc 字段, 然后改了work字段和hobby字段. 此时再get, 看看结果

确实是全量修改
POST /库名/_doc/文档id
这也是一种全量方式, 结果和 PUT 是一样的. 同样的, post也可以新增数据.
POST /库名/_update/文档id
非全量方式, 他只有修改的功能, 没有新增文档的功能
如果只有全量方式, 那岂不是很不方便.
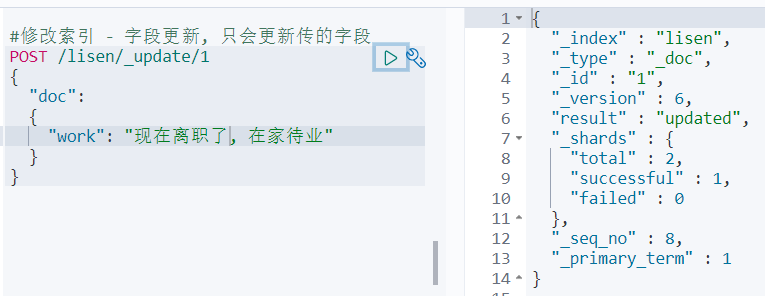
再get一下:

别的字段都在, 且没有发生任何变化
六 复杂查询
复杂查询可以实现 分页, 排序, 高亮, 模糊查询, 精确查询
查询有两种方式, 一种是拼参的方式, 另一种是 GET /库名/_search{} 的方式
拼参方式

GET /库名/_search
#_source显示那些列
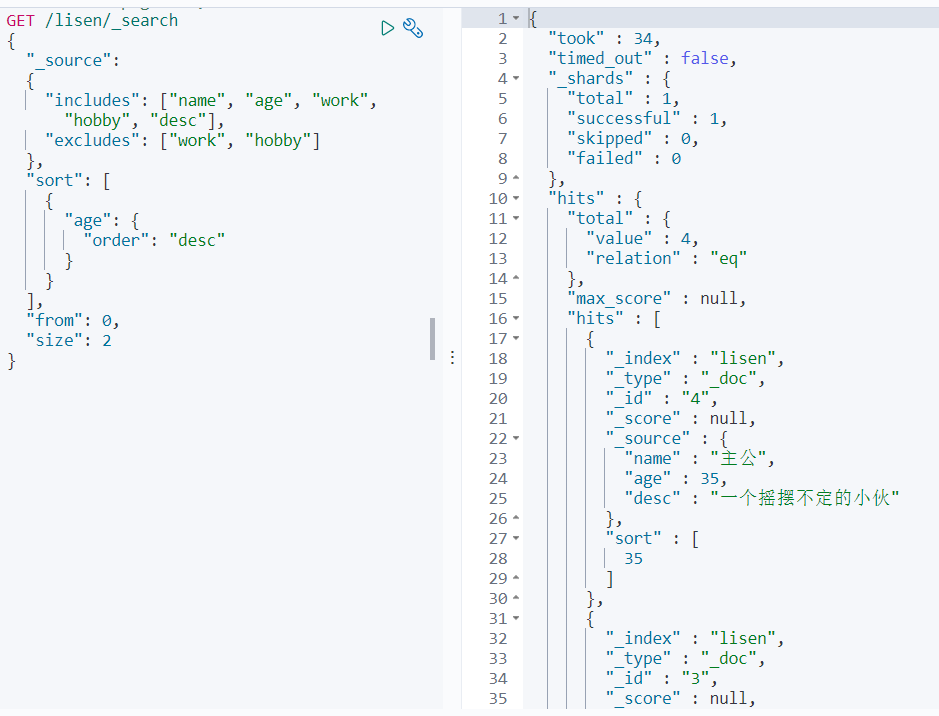
可以直接写数组, 如: ["name", "age", "work", "hobby", "desc"]
还可以设置 includes 和 excludes, 如:
"_source":
{
"includes": ["name", "age", "work", "hobby", "desc"],
"excludes": ["work", "hobby"]
}
#sort 排序
对字段进行排序, 如:
"sort": [
{
"age": {
"order": "desc"
}
}
]
分页
#from 相当于pageNo
#size 相当于pageSize, 默认20
将上面组合起来, 查询看看: