
多线程笔记 - Master-Worker
多线程的 Master-Worker 从字面上也是可以理解的.
Master 相当于领导, 一个就够了, 如果是多个, 那么听谁的, 是个大问题. Master负责指派任务给 Worker. 然后对每个人完成的情况进行汇总.
Worker 相当于具体干活的人, 完成领导分配的任务, 然后把成果交给领导.
这种模式, 有点类似大数据的 MapReduce. 但是比那个简单很多.
这里有个例子:
计算 1²+2²+......+100²的结果.
假如使用 Master-Worker 的方式来计算, 先假设 平方计算 比较耗时, 此处假设每一次平方运算耗时为 100ms.
那么此处要得到计算结果, 就至少需要 100 * 100ms = 10000 ms, 也就是 10s 的时间.
如果此处通过 Master-Worker 的模式来解决此问题, 那么时间会大大缩短.
MyTask 用来存储待计算的数值, 如: 1, 2, 3
public class MyTask implements Serializable { private int id; private int num; public MyTask(int id, int num) { this.id = id; this.num = num; } ...... @Override public String toString() { return "MyTask{" + "id=" + id + ", num=" + num + '}'; } }
Master既然是领导, 肯定需要知道来了哪些任务, 要分配给哪些下属, 且下属干活的成果是什么
public class MyMaster { //1. 需要一个容器来存储待执行任务 private final ConcurrentLinkedQueue<MyTask> tasks = new ConcurrentLinkedQueue<>(); //2. 需要一个容器来存储执行任务的线程 <线程名称, 线程> private HashMap<String, Thread> workThreads = new HashMap<>(); //3. 需要一个容器来存储每一个线程执行后的结果 <任务id, 任务结果> private ConcurrentHashMap<Integer, Object> resMap = new ConcurrentHashMap<>(); //4. 构造函数, 将 Worker 传入, 让每个线程都执行相同的方法 public MyMaster(AbstractWorker myWorker, int workerCount) { myWorker.setTasks(tasks); myWorker.setResMap(resMap); for (int i = 1; i <= workerCount; i++) { String name = "worker" + i; workThreads.put(name, new Thread(myWorker)); } } //5. 任务提交到容器中 public boolean addTask(MyTask task) { return tasks.add(task); } //6. 任务开始执行方法 public void execute(){ for (Map.Entry<String, Thread> worker : workThreads.entrySet()) { worker.getValue().start(); } } //7. 判断所有线程是否执行完毕 public boolean isComplated(){ for (Map.Entry<String, Thread> worker : workThreads.entrySet()) { if(worker.getValue().getState() != Thread.State.TERMINATED){ return false; } } return true; } //8. 总结归纳, 获取结果 public int getResult(){ int res = 0; for (Map.Entry<Integer, Object> resItem : resMap.entrySet()) { res += (int) resItem.getValue(); } return res; } }
Worker 作为干活的人, 也需要知道任务列表, 当干完一个之后, 可以再领取一个任务撸起袖子加油干. 然后还需要知道需要将干活的成果放到哪里去.
public abstract class AbstractWorker implements Runnable { // <线程名称, 线程>, 子类持有 Master 的任务列表, 从中拿取任务 private ConcurrentLinkedQueue<MyTask> tasks; //<任务id, 任务结果>, 子类持有 Master 的结果列表, 将计算结果放进去 private ConcurrentHashMap<Integer, Object> resMap; public void setTasks(ConcurrentLinkedQueue<MyTask> tasks) { this.tasks = tasks; } public void setResMap(ConcurrentHashMap<Integer, Object> resMap) { this.resMap = resMap; } @Override public void run() { while (true) { MyTask task = tasks.poll(); if (task == null) { break; } Object res = handle(task); resMap.put(task.getId(), res); System.out.println(Thread.currentThread().getName() + " 计算 " + task.getNum() + " 结果为 : " + res); } } //这里将具体的实现逻辑放到子类里去, 可以增加扩展性, 此例中现在是算平方, 那通过传入不同的Worker, 也可以算开方 public abstract Object handle(MyTask task); } public class SquareWorker extends AbstractWorker { public Object handle(MyTask task) { int res= task.getNum() * task.getNum(); try { //模拟运算耗时 Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } return res; } }
测试:
public static void main(String[] args) throws InterruptedException { SquareWorker worker = new SquareWorker(); MyMaster master = new MyMaster(worker, 10); String outPrint = ""; for (int i = 1; i <= 100; i++) { MyTask task = new MyTask(i, i); master.addTask(task); outPrint += i + "²" ; if(i < 100){ outPrint += " + "; } } System.out.println(outPrint);
//统计下计算时间 long startTime = System.currentTimeMillis(); master.execute(); while (true){ if(!master.isComplated()){ Thread.sleep(50); continue; } int result = master.getResult(); System.out.println("计算的结果为 : " + result + ", 耗时为 : " + (System.currentTimeMillis() - startTime)); break; } }
结果:
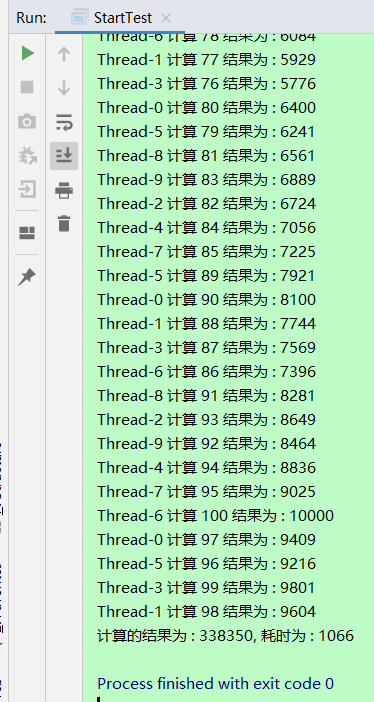
可以看到, 耗时才 1s 多一点, 比之前的 10s 中, 确实缩短了很多.
此处的输出顺序, 并不是有序的. 这也是多线程的一个特点, 正常情况下代码书写顺序和多线程的执行顺序, 往往不是一致的.
当然任何方式, 都是有优点和缺点的.
优点是缩短了执行时间
缺点却是起了更多的线程, 要知道起线程(还有的优化)是有开销的. 起了更多的线程, 就占了更多的空间. 相当于是用空间换时间的一种干法.
这里可以先做一个小优化, 将线程交给线程池托管. 可以不用知道下面具体是那些人干活, 有点外包的意思. master 只要发布任务, 然后拿到自己想要的结果就行了.
先对 Master 进行改写:
public class MyMaster { // <线程名称, 线程>, 子类持有 Master 的任务列表, 从中拿取任务 private final ConcurrentLinkedQueue<MyTask> tasks = new ConcurrentLinkedQueue<>(); //2. 需要线程池来对线程进行托管 private ThreadPoolExecutor pool; //3. 具体干活的标准 private AbstractWorker worker; //4. 雇佣几个人干活 private int workerCount ; //3. 需要一个容器来存储每一个线程执行后的结果 <任务id, 任务结果> private ConcurrentHashMap<Integer, Object> resMap = new ConcurrentHashMap<>(); //4. 构造函数, 将 Worker 传入, 让每个线程都执行相同的方法 public MyMaster(AbstractWorker worker, int workerCount) { this.worker = worker; worker.setResMap(resMap); worker.setTasks(tasks); this.workerCount = workerCount; pool = new ThreadPoolExecutor(workerCount, workerCount, 0, TimeUnit.SECONDS, new LinkedBlockingQueue()); } public void addTask(MyTask task) { tasks.add(task); } public void execute(){ for (int i = 0; i < workerCount; i++) { pool.execute(worker); } } //7. 判断所有线程是否执行完毕 public void finish() { pool.shutdown(); } public boolean isFinished() { return pool.isTerminated(); } //8. 总结归纳, 获取结果 public int getResult() { int res = 0; for (Map.Entry<Integer, Object> resItem : resMap.entrySet()) { res += (int) resItem.getValue(); } return res; } }
测试方法:
public static void main(String[] args) throws InterruptedException { SquareWorker worker = new SquareWorker(); MyMaster master = new MyMaster(worker, 10); String outPrint = ""; long startTime = System.currentTimeMillis(); for (int i = 1; i <= 100; i++) { MyTask task = new MyTask(i, i); master.addTask(task); outPrint += i + "²"; if (i < 100) { outPrint += " + "; } } System.out.println(outPrint); master.execute(); master.finish(); while (!master.isFinished()){ Thread.sleep(10); } int res = master.getResult(); System.out.println("计算的结果为 : " + res + ", 耗时为 : " + (System.currentTimeMillis() - startTime)); }
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号