
搭建hadoop cluster
准备4台机器,一台做namenode和jobtracker,假设它主机名和ip都是master。三台机器做datanode,主机名和ip分别是d1-d3,统称为ds。网络互通。
首先准备ssh。因为hdfs是分布式文件系统,并且node之间会有各种操作,所以需要打通ssh。方法是在所有机器上生成key,比如你将要使用的用户是hadoop
ssh-keygen -t rsa
然后将master的~/.ssh/id_rsa.pub追加到ds的~/.ssh/authorized_keys,实现m->ds打通。反过来,ds->m的也都要打通。这样所有datanode和m都能互通,但是ds之间不需要。另外还得记得一点,master自己的pub要放到自己的authorized去,自己和自己打通,否则启动secondNamenode会失败,因为这里只有一个master
接下来全部在master操作,不需要去ds
其次下载hadoop,比如hadoop-2.7.4,master下载并解压到/opt/下,需要进入/opt/hadoop/etc/hadoop目录并进行如下设置
hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/usr/lib/jvm/java-8-oracle
core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop-2.7.4/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>/data/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/data/hadoop/hdfs/data</value> </property> </configuration>
这是hdfs设置,注意相关目录都要有权限,最好设置owner为hadoop。replication是复制因子,1的意思是每个datanode都会复制一份数据去别的datanode,每个节点的数据只少在另一个节点有备份
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration>
hadoop自带一个yarn server,这个做mapReduce作业管理
mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>master:9001</value> </property> </configuration>
这个自然是指定yarn的地址了
最后2个就是master和slaves两个文件了,很直观,master填入namenode,slaves是datanode
hadoop@master:/opt/hadoop/etc/hadoop# cat master master hadoop@master:/opt/hadoop/etc/hadoop# cat slaves d1 d2 d3
到此为止conf设置完毕,现在把/opt/hadoop scp到各个ds
进入hadoop bin,先格式化namenode,这个步骤仅需执行一次
./hadoop namenode -format
然后可以启动hadoop了,先启动hdfs,再启动jobtracker
./start-dfs.sh ./start-yarn.sh
正常来讲,在master和ds上操作jps -m,应该有以下进程
master:
NameNode
SecondaryNameNode
ds:
DataNode
可以测试一些命令
# ls hadoop fs -ls / # mkdir hadoop fs -mkdir hdfs://master:9000/test # add hadoop fs -put hadoop-2.7.4.tar.gz /test # delete hadoop fs -rm /test/hadoop-2.7.4.tar.gz # 一些参数 hadoop fs -ls -h /test hadoop fs -du -h /test/hadoop-2.7.4.tar.gz
这样分布式文件系统hdfs和hadoop mapReduce job环境就搭建好了
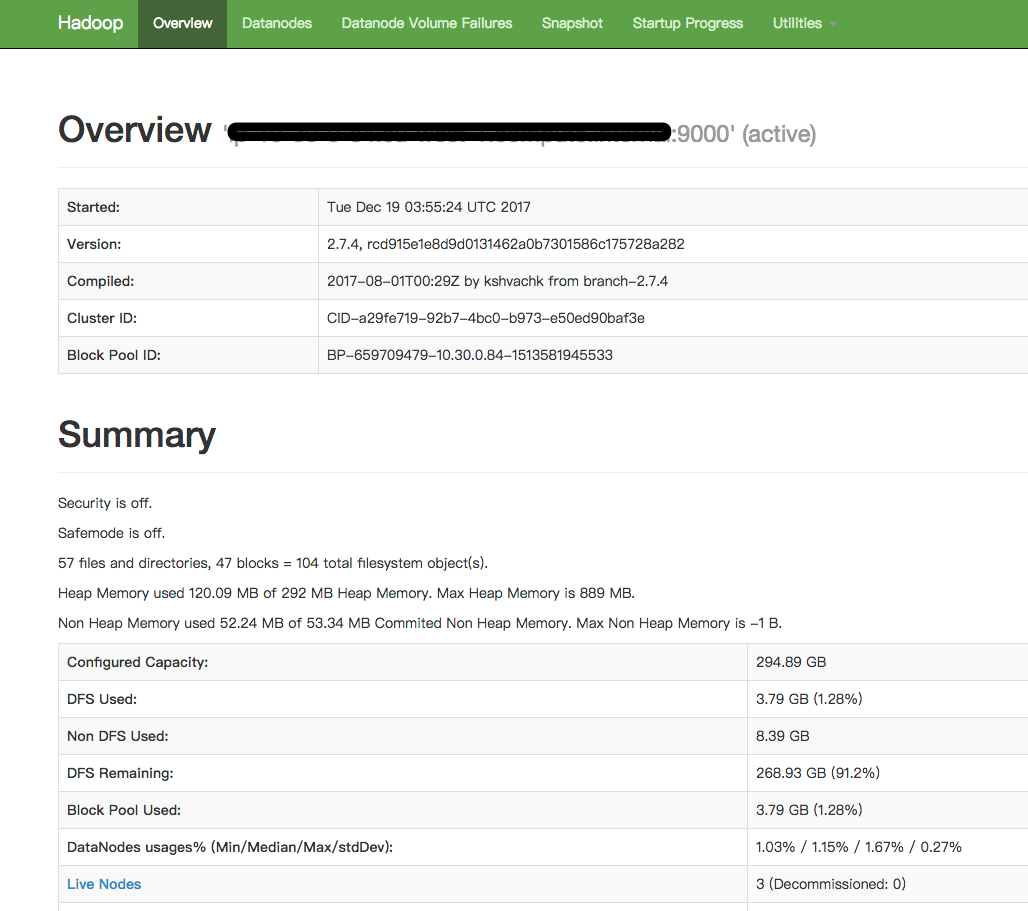
查看节点状态
运行 hadoop dfsadmin -report DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Configured Capacity: 316636778496 (294.89 GB) Present Capacity: 292826760164 (272.72 GB) DFS Remaining: 288759403492 (268.93 GB) DFS Used: 4067356672 (3.79 GB) DFS Used%: 1.39% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (3): Name: d3:50010 (dd3) Hostname: d3 Decommission Status : Normal Configured Capacity: 105545592832 (98.30 GB) DFS Used: 1758699520 (1.64 GB) Non DFS Used: 2879700992 (2.68 GB) DFS Remaining: 95974314316 (89.38 GB) DFS Used%: 1.67% DFS Remaining%: 90.93% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 9 Last contact: Tue Dec 19 07:19:04 UTC 2017 Name: d2:50010 (d2) Hostname: d2 Decommission Status : Normal Configured Capacity: 105545592832 (98.30 GB) DFS Used: 1217626112 (1.13 GB) Non DFS Used: 3051429888 (2.84 GB) DFS Remaining: 96343658828 (89.73 GB) DFS Used%: 1.15% DFS Remaining%: 91.28% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 9 Last contact: Tue Dec 19 07:19:02 UTC 2017 Name: d1:50010 (d1) Hostname: d1 Decommission Status : Normal Configured Capacity: 105545592832 (98.30 GB) DFS Used: 1091031040 (1.02 GB) Non DFS Used: 3080253440 (2.87 GB) DFS Remaining: 96441430348 (89.82 GB) DFS Used%: 1.03% DFS Remaining%: 91.37% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 9 Last contact: Tue Dec 19 07:19:03 UTC 2017
自带的web ui:http://master:50070/dfshealth.html#tab-overview
测试一个大文件,比如梦幻西游客户端,3.8个G
wget http://xyq.gdl.netease.com/MHXY-JD-3.0.212.exe.1 hadoop fs -put MHXY-JD-3.0.212.exe.1 /test
然后去各个节点执行du -sh /data/hadoop
master:3.3M 因为不存数据嘛,只是namenode和jobtracker,换句话说只管理节点和mapReduce
d1:1.1G
d2:1.2G
d3:1.7G
西游客户端均分三份是4035141420/3/1024/1024/1024=1.25G
所以d1,d2都是自己的那份数据(因为之前还有别的文件添加,删除,所以不那么精确),而它俩都选择d3做自己的副本,所以d3上多承担了两份数据,变得更大,但并没有变成3*1.25。我的理解是,跟磁盘阵列一样,存放的是一部分数据和校验和checksum,只要能够拿到足够的副本数据和checksum,就能计算出来完整的副本
可以看到数据节点只需要打通ssh操作,其他都在master完成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号