python_day2(列表,元组,字典,字符串)
1.bytes数据类型
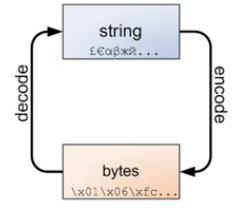
msg = '我爱北京天安门' print(msg.encode(encoding="utf-8")) print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))
>> b'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8' (b代表二进制)
>> 我爱北京天安门
2.列表
#Author:Elson Zeng names = ["lina","kara","elson","drango"] #加入到列表后面 names.append("test") print("name") #插入 names.insert(1,"test2") print(names) #更改 names[2] = "test3" print(names) #删除 names.remove("test3") #del names[1] #names.pop(1) print(names) #查找lina位置 print(names.index("lina")) #统计一个列表元素的数量 print(names.count("lina")) #翻转列表 names.reverse() #列表排序 names.sort() #扩展列表 names2 = [1,2,3,4] names.extend(names2)
import copy
#浅copy(只复制第一层)
name2 = copy.copy(names)
#深cpoy
name2 = copy.deepcopy(names)
#清空列表 names.clear()
3.元组
不能修改,只读列表
names = ('a','b') print(names.index('a')) print(names.count('b'))
4.程序练习

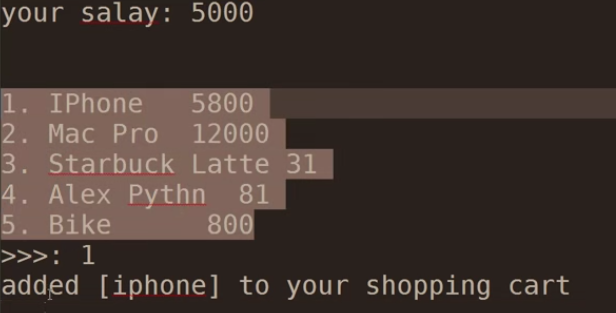
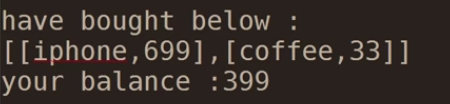
#Author:Elson Zeng shop_list = [ ['iphone',5800], ['Mac',15800], ['bike',800], ['alex python',5800]] buy_shop = [] salay = int(input('your salay:')) index_shop = '' while index_shop != 'q': for shop_num in range(len(shop_list)): print(shop_num+1,shop_list[shop_num]) index_shop = int(input('>>>:')) memory = shop_list[index_shop-1][1] #print(memory) if memory > salay: print('your menery loss' ) index_shop = 'q' continue else: print('add {shop} to your shoping cat'.format(shop=shop_list[index_shop-1][0])) salay = salay - memory #print(salay) buy_shop.append(shop_list[index_shop-1]) else: print('''have bought below: {shop} your balance : {memory}'''.format(shop=buy_shop,memory=salay))
5.字符串操作
#Author:Elson Zeng name = 'elson' #首字母大写 print(name.capitalize()) #统计'e'字符数量 print(name.count('e')) #打印字符 print(name.center(50,'-')) '''----------------------elson-----------------------''' #判断结尾 print(name.endswith('son')) '''True''' #查找字符index print(name.find('l')) '''1''' #判断字符(<>特殊符号) print('ab123'.isalnum()) #判断英文 print('ABc'.isalpha()) #判断是否整数 print('123'.isdigit()) print('|'.join(['1','2','3'])) '''1|2|3''' #补齐字符串/rjust print(name.ljust(20,'*')) #elson*************** #变大小写 print(name.lower()) print(name.upper()) #去空格换行(左lstrip,右rstrip# ) print(' elson '.strip()) '''elson''' #密码对应 p = str.maketrans('abcdef','123456') print('abccc'.translate(p)) '''12333''' #替换 print('elson'.replace('e','E',1)) '''Elson''' #分裂 print('elson is good'.split(' ')) '''['elson', 'is', 'good']'''
6.字典
#Author:Elson Zeng info = { 'stu01':'tenglan wu', 'stu02':'longzemali', 'stu03':'xiaoze maliya' } info['stu01'] = '武藤兰' #删除 # del info['stu01'] # a = info.pop('stu02') # info.popitem() print(info) #打印所有值 print(info.values()) #打印所有key print(info.keys()) #判断是否在字典 print('stu03' in info) #存在就忽略,不存在就创建 info.setdefault("大陆",{'wwww.baidu.coom'}) print(info) #合并两个字典 b = {'stu01':'elsom',1:5,2:3} info.update(b) print(info) '''{'stu01': 'elsom', 'stu02': 'longzemali', 'stu03': 'xiaoze maliya',
'大陆': {'wwww.baidu.coom'}, 1: 5, 2: 3}''' #初始化一个新的字典 c = dict.fromkeys([6,7,8],'test') print(c) '''{6: 'test', 7: 'test', 8: 'test'}''' #字典的循环 for i in info: print(i,info[i]) '''stu01 elsom stu02 longzemali stu03 xiaoze maliya 大陆 {'wwww.baidu.coom'} 1 5 2 3'''
7. 字符串转列表
str1 = "hi hello world"
print(str1.split(" "))
输出:
['hi', 'hello', 'world']
8. 列表转字符串
l = ["hi","hello","world"]
print(" ".join(l))
输出:
hi hello world

 浙公网安备 33010602011771号
浙公网安备 33010602011771号