python requests的content和text方法的区别
requests对象的get和post方法都会返回一个Response对象,这个对象里面存的是服务器返回的所有信息,包括响应头,响应状态码等。其中返回的网页部分会存在.content和.text两个对象中。
两者区别在于,content中间存的是字节码,而text中存的是Beautifulsoup根据猜测的编码方式将content内容编码成字符串。
直接输出content,会发现前面存在b'这样的标志,这是字节字符串的标志,而text是,没有前面的b,对于纯ascii码,这两个可以说一模一样,对于其他的文字,需要正确编码才能正常显示。大部分情况建议使用.text,因为显示的是汉字,但有时会显示乱码,这时需要用.content.decode('utf-8'),中文常用utf-8和GBK,GB2312等。这样可以手工选择文字编码方式。
所以简而言之,.text是现成的字符串,.content还要编码,但是.text不是所有时候显示都正常,这是就需要用.content进行手动编码。
eg:text
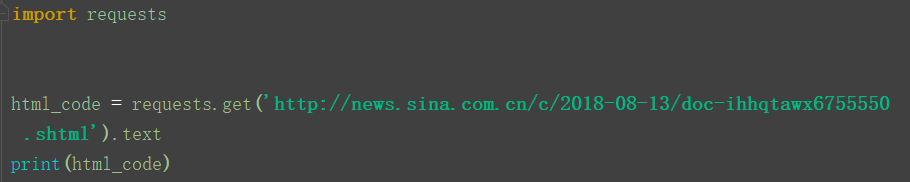
输出的结果为:
遇到中文时就会显示乱码
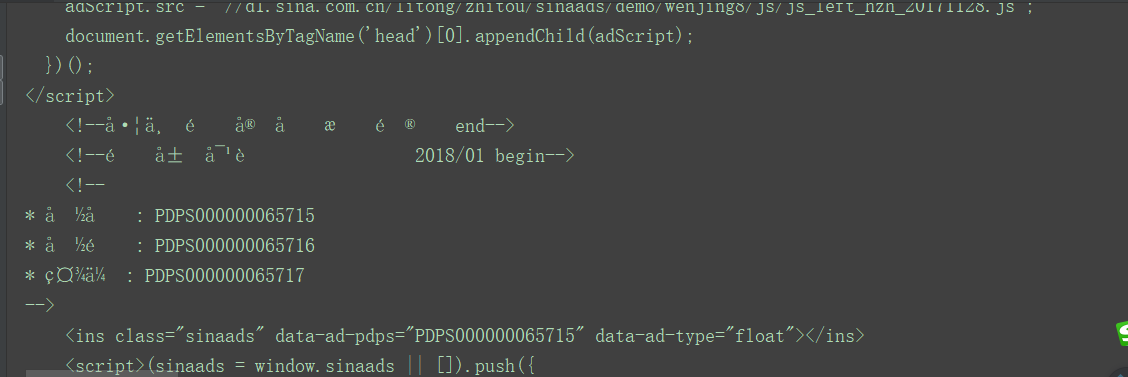
这样不是我们想要的结果了
那么这个时候就只能用content的方法来实现解码了
eg:content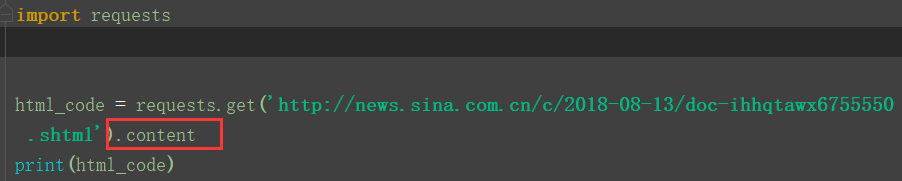
结果是:

这个时候不过都是16进制的东西,这个没有关系再进行encode('utf-8')对应的解码就可以了
解决方案:进行encode('utf-8')对应的解码就可以了
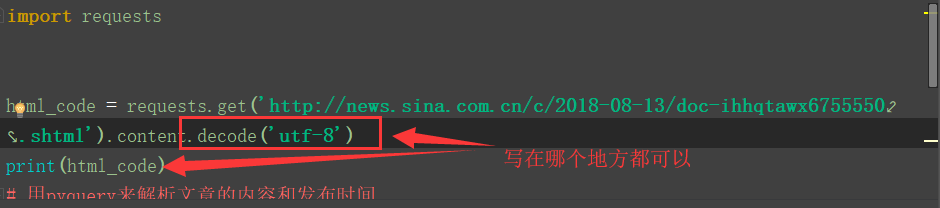
结果:

结论是:text 返回的是unicode 型的数据,一般是在网页的header中定义的编码形式。
content返回的是bytes,二级制型的数据。
也就是说你如果想要提取文本就用text
但是如果你想要提取图片、文件,就要用到content
举例说明:
# 例如下载并保存一张图片
import requests
jpg_url = 'http://img2.niutuku.com/1312/0804/0804-niutuku.com-27840.jpg'
content = requests.get(jpg_url).content
with open('demo.jpg', 'wb') as fp:
fp.write(content)
这样就可以显示你想要的结果了
当你的才华还撑不起你的野心的时候,你就应该静下心来学习;
当你的能力还驾驭不了你的目标时,就应该沉下心来历练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号