python multiprocessing 源码分析
1. 文档是最先需要了解的,读完文档可能会有很多的意外的收获同时也会留下疑惑,对于一般的使用我觉得读完文档就差不多了,除非一些很有疑惑的地方你可能需要再深入的了解一下。我读文档的目的第一个就是为了找出疑惑然后带着疑惑去读源码,还有一个目的就是为了后面读源码提供指导。
2. multiprocessing.Process类是multiprocessing中最基础的类,后面的pool都是在这个类的基础上再包装的,所以从它入手最合适不过了。这个类的文档和源码都比较简单,唯一可能有点让人疑惑的就是daemon这个属性,千万不要被名字迷惑了,它跟我们常见的Linux daemon进程没有任何关系了。简单点说它的功能就是:一个进程退出(exit)的时候会尝试把它所有daemonic(设置了daemon属性)的子进程终止(terminate)。
3. multiprocessing.Process源码分析
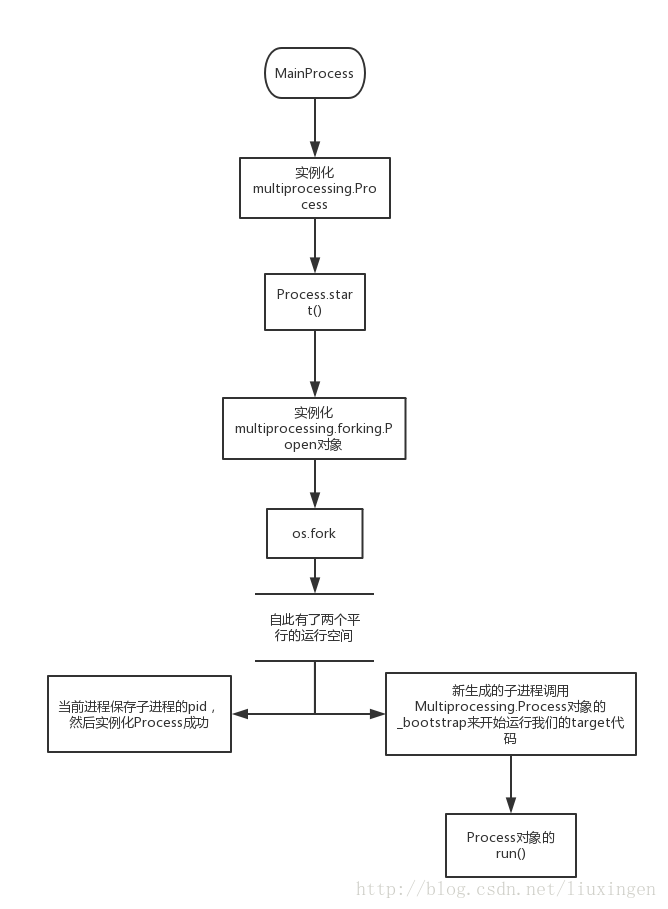
当我们import multiprocessing的时候就会生成一个_MainProcess类,这是代表当前主进程,内容比较简单。当我们在主进程中调用Process()来生成一个进程对象的时候会从_MainProcess中继承一些属性,例如:daemon属性。当调用Process.start()开始运行一个进程的时候首先会有三条assert断言语句:不能重复start一个进程、只能start当前进程自己创建的进程、daemon进程不能有子进程。接着调用_cleanup()清理当前已经运行完的进程(join,然后把它从当前进程的子进程集合中去掉)。到了动真格的时候,就是要fork生成子进程了,在Process中用Popen封装了子进程的操作,用属性_popen来代表子进程。下面是Process.start()的源码:
def start(self): ''' Start child process ''' assert self._popen is None, 'cannot start a process twice' assert self._parent_pid == os.getpid(), \ 'can only start a process object created by current process' assert not _current_process._daemonic, \ 'daemonic processes are not allowed to have children' _cleanup() if self._Popen is not None: Popen = self._Popen else: from .forking import Popen self._popen = Popen(self) _current_process._children.add(self)
我们看到调用Popen创建子进程,然后把生成的Process对象加入到当前进程的子进程集合中后我们就算完成了子进程的初始化、运行,这个步骤看起来比较简单,其实真正的干货实在Popen中,所以我们接着来看forking.Popen类。
4. multiprocessing.forking.Popen源码分析
Popen首先把stdin、stdout刷新一下,接着就是代表子进程退出码的returncode,然后就是调用os.fork来真正生成子进程。fork后当前进程(也就是父进程)返回并且记录子进程的进程ID(Popen对象的pid属性),新生成的子进程调用Process对象的_bootstrap()来运行我们的target,最后调用os._exit()直接退出。
Process.start()->Popen.__init__()->os.fork->Process._bootstrap()
我们又回到了Process了,感觉是不是有点绕呢。当我们再次回到Process.__bootstrap()的时候一定要记住我们是在一个克隆的新空间中了,不再是前文中我们一直提到的当前进程了,而是我们在当前进程新生成的子进程中了。在__bootstrap()中会先重新设置children、_count属性以及代表当前进程的全局变量_current_process,之所以要重新设置就是我们已经新生成了一个进程空间,我们当前是在这个新空间中运行着,特别是代表当前进程的_current_process变量需要好好理解一下。接着就是清空_finalizer_registry(这个我们留到后面再说),调用util._run_after_fork()来做一些fork之后运行target之前的操作,当然默认情况下是没有任何操作的,不过我们也可以调用util.register_after_fork()来注册一些函数,util.register_after_fork()这个函数在文档中是没有提及到的,算是一个”偏门”。最后就是调用Process.run运行我们的target了,到此时我们的子进程就运行到了我们自己要运行的目标中了。运行完后会调用util._exit_function()来做一些扫尾工作,这个函数是我们接下来的重点内容。
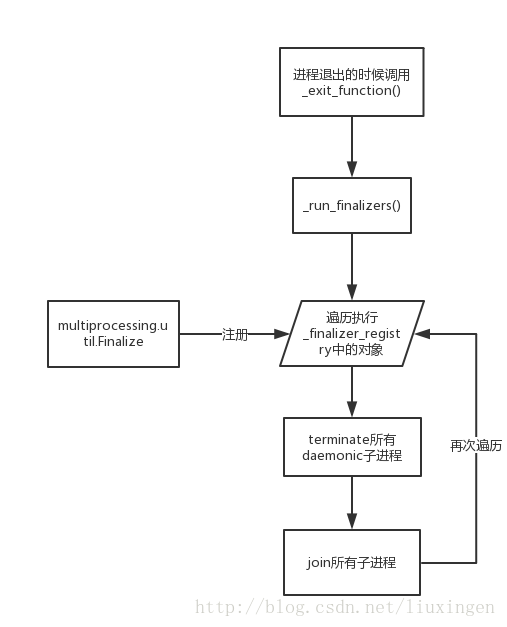
5. 进程退出的清理工作,_exit_function源码分析
无论是主进程还是生成的子进程在进程退出之前都需要做一些清理工作,避免一些系统资源被一直占用而不释放。在主进程中当我们import multiprocessing.forking的时候会间接的import multiprocessing.util,此时就会在util中调用atexit.register(_exit_function)来注册主进程的exit handler。而子进程在上面我们看到运行完我们的target以后会主动调用_exit_function(),所以无论是主进程还是子进程都是调用_exit_function()来做最后的”善后”工作。
_exit_function()的功能其实也比较简单,调用_run_finalizers(0)、终止(terminate)daemonic子进程、join回收子进程、再次调用_run_finalizers()(参数有变化)。这里的代码也很好的帮我理解了进程的daemon属性是干嘛的了。
def _exit_function(info=info, debug=debug, _run_finalizers=_run_finalizers,
active_children=active_children,
current_process=current_process):
# NB: we hold on to references to functions in the arglist due to the
# situation described below, where this function is called after this
# module's globals are destroyed.
global _exiting
info('process shutting down')
debug('running all "atexit" finalizers with priority >= 0')
_run_finalizers(0)
if current_process() is not None:
# NB: we check if the current process is None here because if
# it's None, any call to ``active_children()`` will throw an
# AttributeError (active_children winds up trying to get
# attributes from util._current_process). This happens in a
# variety of shutdown circumstances that are not well-understood
# because module-scope variables are not apparently supposed to
# be destroyed until after this function is called. However,
# they are indeed destroyed before this function is called. See
# issues 9775 and 15881. Also related: 4106, 9205, and 9207.
for p in active_children():
if p._daemonic:
info('calling terminate() for daemon %s', p.name)
p._popen.terminate()
for p in active_children():
info('calling join() for process %s', p.name)
p.join()
debug('running the remaining "atexit" finalizers')
_run_finalizers()
接下来就是_run_finalizer()了,这个函数就是把优先级高于传入的minpriority参数的finalizer函数按照创建时间的倒序执行一遍,当前进程的finalizer函数都是保存在全局变量_finalizer_registry中,这个默认是为空的,也就是没有任何的额外finalizer函数会调用,不过用户可以通过创建multiprocessing.util.Finalize对象来注册finalizer函数。Finalize这个类在multiprocessing的文档中也没有公开,所以这也算是一个隐藏的功能。这个类我们可以在什么时候用到呢?比如你在一个Process中创建了一个数据库连接,需要在进程退出之前关闭这个连接,你除了在你的target代码中执行关闭以外还可以通过实例化multiprocessing.util.Finalize对象来实现这个功能。在multiprocessing内部代码中就有很多的地方使用Finalize来实现清理工作。
6. 至此Process的出生到灭亡我们都有涉及了,其它的一些功能大体从代码中都能看明白了,无非就是对子进程的pid做一些os.waitpid、os.kill之类的调用,不再一一讨论了。Process只是multiprocessing中最基础的部分,后面我会接着写一下最重要的multiprocessing.pool。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号