
译:Local Spectral Graph Convolution for Point Set Feature Learning-用于点集特征学习的局部谱图卷积
标题:Local Spectral Graph Convolution for Point Set Feature Learning
作者:Chu Wang, Babak Samari, Kaleem Siddiqi
译者:Elliott Zheng
来源:ECCV 2018
Abstract
点云的特征学习已经显示出巨大的希望,引入了有效且可推广的深度学习框架,例如pointnet ++。
然而,到目前为止,点特征已经以独立和孤立的方式被抽象,忽略了相邻点的相对布局及其特征。在本文中,我们建议通过在局部图上使用谱图卷积结合新的图池化策略来克服这种限制。在我们的方法中,图卷积是在从点的邻域构造的最近邻图上执行的,从而共同学习特征。我们用递归聚类和池化策略替换标准的最大池化步骤,设计用于聚合来自其谱坐标中彼此接近的节点簇内的信息,从而产生更丰富的整体特征描述符。通过对各种数据集的广泛实验,我们展示了点集分类和分割任务的一致可证明的优势。
1 Introduction
随着复杂的现实世界场景的预配准深度和彩色图像的可用性,对于经典计算机视觉问题(包括对象检测,分类和分割)的特征处理算法存在极大的兴趣。
例如,在他们最新的版本中,现在可以在苹果iPhone X相机中找到深度传感器,为普通用户提供全新的计算机视觉技术。对于这样的数据,直接使用无组织的3D点云并且不需要诸如表面网格的中间表示是特别有吸引力的。来自这些传感器的3D点云的处理仍然具有挑战性,因为所感测的深度点可以在空间密度上变化,由于遮挡或透视效应而可能是不完整的并且可能遭受传感器噪声。
由于需要处理非结构化3D点云,同时利用深度神经网络的强大功能,Pointnet ++框架已经显示出对于识别和分割任务的3D点云特征处理的前景[13]。在这种方法中,网络结构被设计为直接与点云数据一起工作,同时以常规网格上的传统CNN的精神以分层方式聚合信息。为此,首先在输入点云上应用质心采样,然后进行半径搜索以形成点邻域。然后通过多层感知器[11]处理点邻域,并通过池化操作抽象得到的点特征。通过对点云数据的分层多层学习,pointnet ++框架在有挑战性的基准测试中在分段和分类方面表现出令人印象深刻的性能,同时将输入数据视为无组织点云。
与此同时,Defferrard等人,试图将传统上应用于常规域的CNN(例如2D中的采样图像像素或3D中的体素)扩展到表示为图的不规则域[4]。他们的方法使用切比雪夫多项式逼近谱图滤波器;通过卷积运算处理初始图以产生特征,然后使用子采样和汇集方法对这些特征进行粗化。 Kipf和Welling [6]简化了Defferrard等人的高阶多项式近似。并提出了谱图滤波器的一阶线性逼近。
上述频谱方法在完整图上运行,并且具有图拉普拉斯算子和图粗化层次必须在网络训练或测试之前以离线方式预先计算的限制。当完整图很大时,这会增加显着的开销。
在本文中,我们建议在pointnet ++框架中利用频谱图CNN的强大功能,同时采用不同的汇集策略。这使我们能够从点云解决目前深度学习方法的两个局限性:1)事实上,对于每个点样本,局部点云的特征的学习是以孤立的方式进行的。2)后面层中的信息聚合使用贪婪的赢家通吃最大池策略。相反,我们采用不同的池化模块,如图1中的详细示例所示。此外,与现有的谱图CNN方法相比,我们的方法不需要预计算[4,6]。我们将局部谱特征学习与递归聚类和池化相结合,为无组织点云的点集特征提取提供了一种新颖的架构。我们主要的方法论贡献如下:
- 在点集特征学习中使用局部谱图卷积以在每个点的邻域中结合结构信息。
- 局部频谱图卷积层的实现,其不需要离线计算并且可以端到端方式训练。我们在运行时动态构建图,并动态计算拉普拉斯算子和池化层次结构。
- 使用新颖有效的图池化策略,通过递归聚类谱坐标来聚合图节点处的特征。
2 Challenges in point set feature learning
Pointnet ++框架[13]中特征学习的局限性在于,一个点的k个最近邻(k-NN)的特征是以孤立的方式学习的。设\(h\)表示深层网络中任意隐藏层的输出,通常是多层感知器。在Pointnet ++中,\(k\)-NN中每个点的各个特征都是用$h(x_i),i \in 1,2,...,k $实现的。不幸的是,这个隐藏层函数不模拟k-NN中各点之间的联合关系。一个联合学习来自k-NN中的所有点的特征的卷积核将捕获与点的几何布局相关的拓扑信息,以及与输入点样本本身相关的特征,例如颜色,纹理或其他属性。在下一节中,我们将扩展诸如Pointnet ++框架之类的方法,以通过使用局部图卷积来实现这一目标,不过是在谱域中。
Pointnet ++的另一个限制是\(k\)-NN的集合激活函数是通过跨每个点的隐藏层输出的最大池化来实现的,也就是说
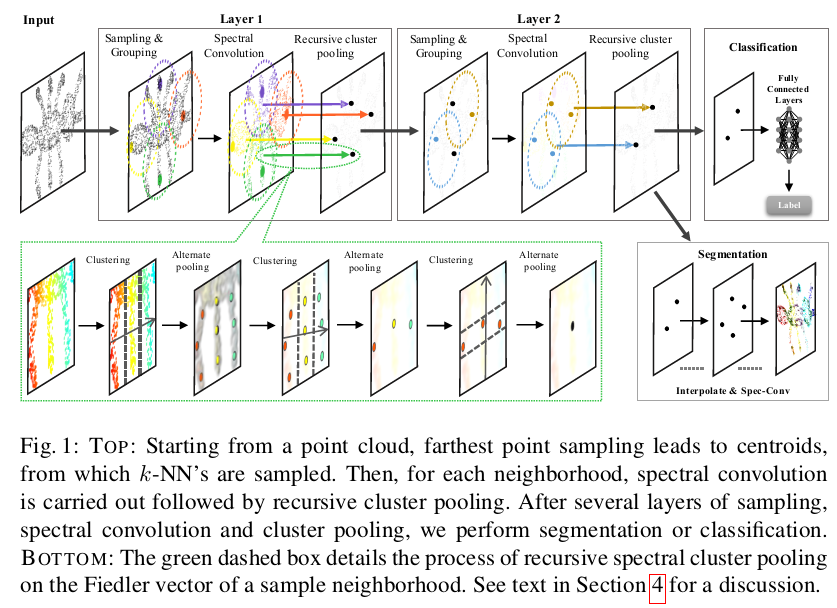
最大池化不允许保留来自邻域内不相交点集的信息,如图1中蚂蚁的腿的情况。为了解决这个限制,我们引入了一个递归谱聚类和池化模块,产生一个用于\(k\)-NN的改进的集合激活函数,如第(4)节所述。
本文中的组合点集特征抽象操作可以归纳为
其中\(h_i\)是卷积的输出\(h(x_1,x_2,...,x_k)\)衡量第\(i\)个点,\(\oplus\)表示我们提出的集合激活函数。
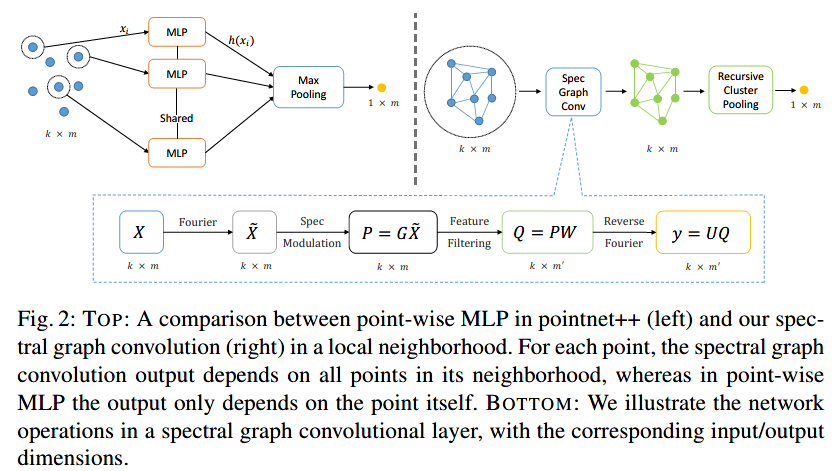
图2提供了PointNet++ [13]中的逐点MLP与我们的谱图卷积之间的比较,以更好地说明我们的动机。Pointnet ++以孤立的方式抽象点特征,而谱图卷积以联合方式考虑局部邻域中的所有点,并且在相邻点处结合邻域点的特征和在抽象的图拓扑中编码的结构信息。更正式地说,这是通过图傅里叶变换和谱调制步骤完成的,它们使用图拉普拉斯算子的特征空间(eigenspace)来混合邻域特征(参见图3)。在下一节中,我们提供了谱图卷积核的理论背景和实现细节。
3 Graph Convolution 图卷积
在空间域上的卷积操作(直接作用在图上顶点)可以通过以下公式描述:
其中\(X\)代表输入点集特征,\(g\)代表空间卷积核。
这等价于图谱域中的逐元素哈达玛积,如Defferrard等人 [4]和舒曼等人[15]所示。
这里\(\tilde{X}\)代表点集特征的图傅里叶变换,\(\tilde{g}\)代表图傅立叶域中的滤波器,而\(\tilde h\)代表滤波后的输出。为了获取原始空间(顶点)域中的滤波输出,需要逆傅里叶变换。我们在下面详细说明图傅立叶变换和谱滤波。
3.1 Graph Formulation of a Local Neighborhood 局部邻域的图表示
给定局部邻域中\(k\)个点\(x_1,x_2,...,x_k\)的集合,我们构建一个表示图\(G_k\),其顶点\(V\)是点,其边\(E\subseteq V\times V\)带有权重\(w : E \to R_+^*\)基于成对距离的测量,例如\(xyz\)空间坐标之间的欧氏距离或深层网络提供的特征空间中的距离。这提供了图的邻接矩阵\(W\),它是\(k\times k\)非负的,对称的,条目\(W_{ij} = dist(x_i, x_j)\)。然后,我们基于该邻接矩阵计算图谱,并执行图傅里叶变换,谱滤波,最后进行逆傅里叶变换。
3.2 Graph Fourier Transform 图傅里叶变换
为了计算点特征\(X\in R^{k\times m}\)的傅里叶变换,它是\(G_k\)顶点上的图信号,我们首先需要计算归一化图拉普拉斯矩阵,其定义为
其中\(I\)是单位阵,\(D\in R^{k\times k}\)是对角的度矩阵,其中的记录\(D_{ii}=\sum_j W_{ij}\)。由此得出\(L\)是一个实对称的半正定矩阵,并且具有一套完整的标准正交特征向量,组成图的傅立叶基。
特征值可以用来构造一个对角阵。
其中包含图的频率。由此得出\(L=U\Lambda U^T\)。\(X\)的图傅里叶变换就可以定义为\(\tilde X=U^TX\),及其逆操作\(X=U\tilde X\)
3.3 Spectral Filtering 谱滤波
傅里叶域上的卷积操作可以定义为
根据Shuman等人 [15],其中\(\bigodot\)是逐元素哈达玛积,\(x\)是任意图信号,\(g\)是空间滤波器。如果我们将\(y = x*g\)定义为图卷积的输出,则可以将由\(g\)过滤的图信号\(X \in R^{k \times m}\)写为
\(y=\tilde g_\theta(L)X=\tilde g_\theta (U\Lambda U^T)X=U\tilde g_\theta (\Lambda)\tilde X\)
其中\(\theta\)代表任意参数化。在下一节中,我们将介绍谱滤波的实现,它是使用TensorFlow在现有的Pointnet ++ [13]框架之上作为模块引入的。
3.4 Implementation of Spectral Filtering 谱滤波的实现
我们使用标准的非参数傅里叶核执行谱图卷积,其中\(\tilde g_\theta(\Lambda)\)的条目都是可学习的。使用\(m\)输入特征维度和\(m\prime\)输出维度,带谱滤波器的图信号\(X\in R^{k \times m}\)的卷积可以通过以下三个步骤实现:
-
频谱调制 输出\(P = G\tilde X\),对角矩阵\(G\)是非参数化的核\(\tilde g_\theta(\Lambda)\)。$ G\(的\)k$个对角线条目都是非参数化傅立叶核公式中的自由参数。
-
特征过滤 它将输入维度从\(m\)扩展到\(m\prime\)。该步骤的输出是特征矩阵\(Q\in R^{k\times m\prime}\)。条目\(q_{k,i}\)是第\(k\)个点的第\(i\)个输出特征并且由\(q_{k,i}=\sum_{j=1}^m p_{k,j}w_{j,i}\)这里\(p_{k,j}\)是对应于在前一步骤中定义\(P\)的第k个点的第\(j\)条输入特征,\(w_{j,i}\)是第\(j\)个输出特征和第\(i\)个输入特征之间的滤波器系数。该步骤可以由\(Q = P W\)表示,其中\(W\)是可学习滤波器的参数矩阵。步骤1和2中的过滤操作可以概括为
\[Q=(G\tilde X)W \] -
傅里叶逆变换 它通过\(y = UQ\)在空间图信号域中提供卷积输出。
上述公式类似于[4]和[6]的公式,不同之处在于我们在运行时构建k-NN图,即时计算其拉普拉斯算子和池化层次结构,因此不需要离线预计算。我们进一步注意到,特征滤波器\(W\)的权重以及频谱调制矩阵\(G\)由给定图卷积层中的所有不同局部邻域共享。因此,与[4,6]不同,我们工作中的学习参数不依赖于基础图结构。图2(下)说明了上述谱滤波过程。
虽然可以使用[4]中更复杂的高效核,但我们的目标是证明图CNN获得的一般的改进。我们的非参数化频谱内核中的特征值分解(EVD)的开销不会显著影响运行时间,因为EVD是在局部k-NN图上计算的,其中k非常小。这种计算很容易通过GPU上的并行计算来处理,如第5.3节中我们的模型消融研究中显示训练时间成本的实验所示。
4 Pooling on Local \(k\)-NN Graph 局部\(k\)-NN图的池化
第2节中讨论的集合激活函数,其目的是总结来自\(k\)-NN图的信息,本质上是图池化的一种形式,其中\(k\)个顶点的图通过特征池化被抽象到单个顶点。我们提出了一种新的k-NN图池化算法,该算法使用分层聚类和聚类内聚类。

整体的策略是在学习期间以仅在具有相似抽象点特征的集群内池化聚集信息,这与最大池化的贪婪策略形成对比,后者通常应用于常规CNN以及PointNet++中。这里的直观感觉是,多组不同的特征可以共同为当前任务的显着特性做出贡献,并且这些集群的检测与集群内池化的组合将提高性能。例如,对于对从人头部采样的点集进行分类的任务,人们希望同时学习和捕获类似鼻子,类似下巴和类似耳朵的特征,而不是假设这些只有一个会对这个对象类别具有辨别力。我们将依次讨论每个步骤。
4.1 Spectral Clustering 谱聚类
我们建议根据使用谱坐标嵌入的局部\(k\)-NN的几何信息将特征分组成簇。我们使用的谱坐标是基于图拉普拉斯矩阵\(L\)的低频特征向量,它捕获粗略的形状属性,因为拉普拉斯算子本身编码\(k\)NN图中的成对距离。正如[9][1]中用于计算网格上的点到点对应或用于特征描述,低频谱坐标提供了对象局部几何的辨别谱嵌入(参见图1底部和图3) 。对应于第二个最小特征值的特征向量,即Fiedler向量[2],被广泛用于谱聚类[14]。
4.2 Clustering, Pooling and Recurrences 聚类,池化和重现
在归一化切割聚类算法[14]之后,我们对Fiedler向量进行划分以在局部\(k\)-NN中执行谱聚类。我们首先按照它们的数值的升序对Fiedler向量的条目进行排序,然后在第一次迭代中将其均匀地切割成\(k_1\)个部分。 Fiedler向量条目落入同一区域的邻域中的点将聚集在一起。这导致\(k_1\)簇具有簇大小\(c = \frac {k}{k_1}\)。在获得\(k_1\)集群的分区后,我们仅在每个集群内执行池化操作。这允许网络利用k-NN图中可能不相交的组件的分离特征。
上述步骤导致具有聚合点特征的粗化\(k_1\)-NN图。然后以递归方式在粗化图上重复相同的过程,以获得每次迭代\(i\)的\(k_i\)簇。注意,我们在不同重现之间交替使用最大池化和平均池化,以进一步增加图池化算法的判别能力。当剩余的顶点数量小于或等于规定的簇大小时,所提出的算法终止。然后对得到的图信号应用规则的全步幅池化。我们在算法1中形式化了上述步骤。
在实践中,我们发现使用\(k = 2c^2\)作为簇大小和邻域大小之间的关系给出了良好的结果,其中两次重现聚类池化和最终池化大小为2.我们使用最大池化作为交替池化方案的第一阶段,我们在第5节中为所有实验修复了这些配置。我们在TensorFlow中实现了递归集群池化模块,将其与谱图卷积层完全集成,使得端到端的网络端到端可训练。

译者致谢
感谢
- 论文原文
- CopyTranslator提供翻译辅助,强烈推荐的论文辅助阅读工具。

