如何爬取js动态生成的页面数据--案例
一、目标网页及要求
目标网页:
https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html

要求:
- 爬取页面中的详情页文章标题、内容、发布时间、文章来源,存入本地mongodb数据库
- 同时在本地创建一个文件夹,在该文件夹下以文章标题.txt创建文本,写入文章内容
2、目标页面分析
以Chrome浏览器为例,通过F12打开抓包工具,按F5刷新下页面,ctr+F进行全局搜索页面中的内容,发现该页面内容是通过ajax动态获取的
Method:GET
url:https://www.xuexi.cn/lgdata/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.json?_st=27037952
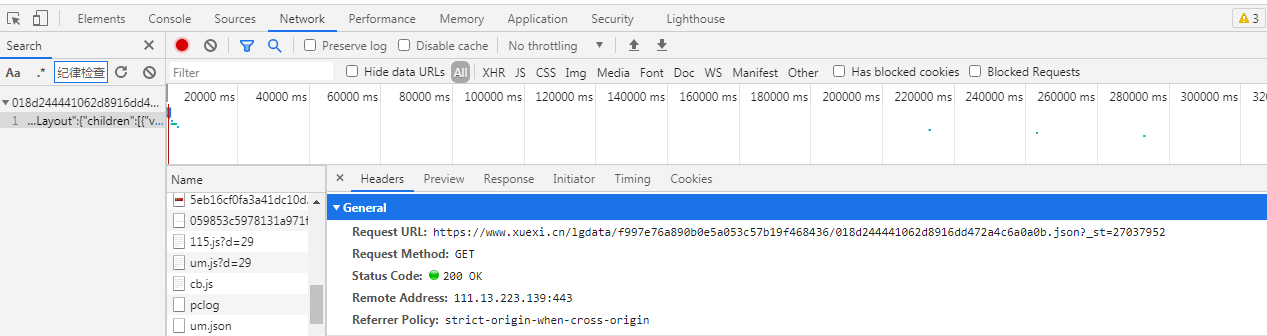
将响应内容通过新窗口打开(安装过JSONView插件),可以很直观的查看Json数据结构

通过分析发现,详情页链接都在title下的link中,并且分为:带请求参数id和不带请求参数两种形式
3、详情页分析
接下来分别对这两种形式的详情页链接进行访问,继续按照目标主页页面的分析步骤,发现数据是通过js动态加载的
携带请求参数id:
详情页url :https://www.xuexi.cn/lgpage/detail/index.html?id=10942099116228124117&item_id=10942099116228124117
数据来源js:https://boot-source.xuexi.cn/data/app/10942099116228124117.js?callback=callback&_st=1622280445799
其它详情页数据来源js都是这种格式
规律如下:
通过详情页url提取id,然后_st参数是16开头的13位数字,没错,就是时间戳*1000后的整数部分,这样我们就能通过详情页url来找到其数据来源js的url
提取数据:
-
- 首先通过正则提取出dict数据,然后通过jsonpath规则提取出目标数据
- 标题:‘$..title’
- 内容:'$..content',之后通过xpath提取p或者span标签中的内容
- 来源:'$..show_source'
- 出版时间:'$..publishi_time'
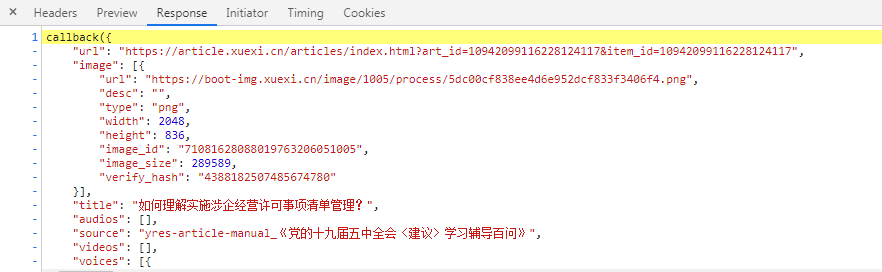
不带请求参数:
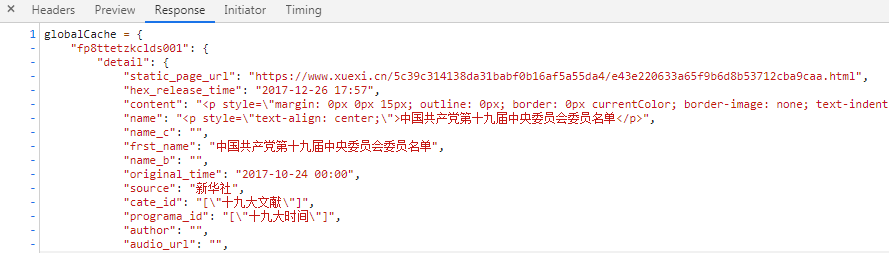
详情页url :https://www.xuexi.cn/5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html
数据来源js:https://www.xuexi.cn/5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js
其它详情页都是以e43e220633a65f9b6d8b53712cba9caa.html结尾,js页都是以datae43e220633a65f9b6d8b53712cba9caa.js结尾
规律如下:
将详情页url中的e43e220633a65f9b6d8b53712cba9caa.html替换成datae43e220633a65f9b6d8b53712cba9caa.js即可
提取数据:
-
- 首先通过正则提取出dict数据,然后通过jsonpath规则提取出目标数据
- 标题:'$.fp8ttetzkclds001..frst_name'
- 内容:'$.fp8ttetzkclds001.detail.content',之后通过xpath提取p或者span标签中的内容
- 来源:'$.fp8ttetzkclds001..source'
- 出版时间:'$.fp8ttetzkclds001..original_time'
4、代码实现
# coding:utf-8
import jsonpath
import json
import re
import requests
import time
import os
import pymongo
import fake_useragent
from lxml import etree
class XuexiSpider:
def __init__(self):
ua = fake_useragent.UserAgent().random # 生成随机User-Agent
self.headers = {
'User-Agent':ua
}
self.json_data_url = 'https://www.xuexi.cn/lgdata/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.json?_st=27035433' #首页数据来源
self.mongoClient = pymongo.MongoClient('mongodb://localhost:27017')
def work(self):
'''开启爬虫'''
if not os.path.exists('./data'):
os.mkdir('./data')
# 发送请求,获取首页dict数据
dict_data = requests.get(self.json_data_url,headers=self.headers).json()
# 提取详情页link
detail_page_links = jsonpath.jsonpath(dict_data,'$..title.link')
for link in detail_page_links:
if link.endswith('html'):
self.parse_link_no_id(link)
else:
self.parse_link_with_id(link)
self.mongoClient.close() #关闭数据库连接
def parse_link_with_id(self,link):
'''解析url中带有id参数的链接'''
id = re.findall(r'id=(\d+)',link)[0] #提取link中的id
_st = str(time.time()*1000).split('.')[0] #构造_st:当前时间戳*1000后取整数部分,然后转成str
js_link = 'https://boot-source.xuexi.cn/data/app/{0}.js?callback=callback&_st={1}'.format(id,_st)
response = requests.get(js_link,headers=self.headers).text
response_dict_data = json.loads(re.findall(r'{.*}',response)[0])
title = jsonpath.jsonpath(response_dict_data,'$..title')[0] #详情页标题
raw_content = jsonpath.jsonpath(response_dict_data,'$..content')[0]
#有的页面只有图片或者视频,content内容为''或者<!--{img:0}-->\n\n,所以需要做个判断
if not raw_content:
content = ''
elif raw_content.startswith('<!--'):
content = ''
else:
tree = etree.HTML(raw_content)
content_list = tree.xpath('//p/text()|//span/text()') #文本内容存放在p或者span标签内
content = '\n\n'.join(content_list) #详情页内容
source = jsonpath.jsonpath(response_dict_data,'$..show_source')[0] #详情页文章来源
publish_time = jsonpath.jsonpath(response_dict_data,'$..publish_time')[0] #详情页文章出版时间
item = {
'title':title,
'content':content,
'source':source,
'publish_time':publish_time
}
self.pipeline(item)
def parse_link_no_id(self,link):
'''解析url中不带有id参数的链接'''
js_link = link.replace('e43e220633a65f9b6d8b53712cba9caa.html','datae43e220633a65f9b6d8b53712cba9caa.js')
response = requests.get(js_link, headers=self.headers).text
response_dict_data = json.loads(re.findall(r'{.*}', response)[0])
title = jsonpath.jsonpath(response_dict_data, '$.fp8ttetzkclds001..frst_name')[0] # 详情页标题
raw_content = jsonpath.jsonpath(response_dict_data, '$.fp8ttetzkclds001.detail.content')[0]
#content内容可能为空字符串,所以需要做个判断
if not raw_content:
content = ''
elif raw_content.startswith('<!--'):
content = ''
else:
tree = etree.HTML(raw_content)
content_list = tree.xpath('//p/text()|//span/text()')
content = '\n\n'.join(content_list) # 详情页内容
source = jsonpath.jsonpath(response_dict_data, '$.fp8ttetzkclds001..source')[0] # 详情页文章来源
publish_time = jsonpath.jsonpath(response_dict_data, '$.fp8ttetzkclds001..original_time')[0] # 详情页文章出版时间
item = {
'title': title,
'content': content,
'source': source,
'publish_time': publish_time
}
self.pipeline(item)
def pipeline(self,item):
'''存储数据'''
# 写入本地文件,文件名:详情页标题.txt
with open('./data/'+item['title']+'.txt','w',encoding='utf-8') as f:
f.write(item['content'])
#存入mongodb数据库
db = self.mongoClient.test #获取数据库
collection = db.xuexi #获取集合
collection.insert_one(item) #集合中插入数据
if __name__ == '__main__':
xuexi = XuexiSpider()
xuexi.work()
由于爬取的数据不是很多,就没有采用多线程或协程异步去实现代码
爬取结果:

文本内容:

至此,大功告成!!!
分析案例来源:https://www.cnblogs.com/bobo-zhang/p/10561617.html#4216119

 浙公网安备 33010602011771号
浙公网安备 33010602011771号