爬虫-使用Xpath以及lxml解析html数据
使用lxml之前,我们首先要会使用XPath。利用XPath,就可以将html文档当做xml文档去进行处理解析了。
一、XPath的简单使用:
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
1.开发工具的安装
Chrome浏览器,可以安装Xpath Helper插件。如果从网上下载插件,得到的文件以.crx结尾,不能直接添加到浏览器扩展程序里,我们需要将这个文件改为.zip结尾,然后新建一个文件夹,将.zip文件解压到新建的文件夹内。通过浏览器的扩展程序-加载已解压的扩展程序-选择该文件夹就可以安装好插件了。
2.语法
XPath使用路径表达式来选取XML文档中的节点或者节点集。节点是通过沿着路径(path)或步(steps)来选取的。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
-
XML实例文档
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
下面的例子中都使用这个文档进行演示。
-
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
常见路径表达式:
| 表达式 | 描述 |
| 节点名 | 必须是根节点,选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
示例:
| 路径表达式 | 结果 |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
-
谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中(模糊查询很重要!!!)。
示例:
| 路径表达式 | 结果 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取bookstore元素中最前面2个book 元素。 |
| /bookstore/book[position()<3 or position()>5] | 选取bookstore 元素下最前面的2个或者自第5个开始的book元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| //BBB[ position() = floor(last() div 2 + 0.5) or position() = ceiling(last() div 2 + 0.5) ] | 选择中间的BBB元素 |
| //BBB[normalize-space(@name)='bbb'] | 选择含有属性name且其值(在用normalize-space函数去掉前后空格后)为'bbb'的BBB元素 |
| //book[./title/@lang="eng"]或者//book[./title[@lang="eng"]] | 选取title子标签lang属性值为eng的book标签 |
| //*[name() != "span"] | 选取除了span标签外的所有标签 |
| //li[span] | 选取包含span子标签的li标签 |
| //li[contains(span,"学习")]') | 选取span子标签内容包含'学习'的li标签 |
| //li[not(span)] | 选取不包含span子标签的li标签 |
| //div[not(@class or @id)] | 选取不包含class属性和id属性的div标签 |
| //div[not(@class='doubles')] | 选取class属性不为doubles的div标签 |
| //title[contains(@lang,'e')] | 模糊查询,选取lang属性中包含e的所有title元素 |
//a[not(contains(text(),"公知")) and contains(@href, "files")]
|
选取超链接文本中不包含"公知"且url中包含"fiels"的a标签 |
//div[starts-with(@class,'ta')]
|
模糊查询,选取class属性以ta开头的元素 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
-
选取未知节点和属性
XPath 通配符可用来选取未知的 XML 元素和属性。
通配符:
| 通配符 | 描述 |
| * | 匹配任何节点。 |
| @* | 匹配任何属性 |
示例:
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
-
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径
示例:
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
-
xpath轴
可定义某个相对于当前节点的节点集:
| 轴名称 | 描述 |
| self | 选取当前节点 |
| attribute | 选取当前节点的所有属性 |
| child | 选取当前节点的所有子元素 |
| parent | 选取当前节点的父节点 |
| ancestor | 选取当前节点的所有先辈(包括父,祖父,祖祖父等) |
| ancestor-or-self | 选取当前节点的所有先辈以及当前节点本身 |
| descendant | 选取当前节点的所有后代元素(包括子,孙等) |
| descendant-or-self | 选取当前节点的所有后代元素及当前节点本身 |
| following | 选择文本中当前节点结束标签后的所有节点 |
| namespace | 选取当前节点的所有命名空间节点 |
| preceding-sibling | 选取当前节点之前的所有同级节点 |
| following-sibling | 选取当前节点之后的所有同级节点 |
//*[text()="供应商"]/following-sibling::span[1]/text() |
选取文本内容为‘供应商’节点后面的第1个span节点内容 |
示例:
| 轴名称 | 描述 |
| parent::* | 选取当前节点的父节点 |
//*[text()="400电话"]/parent::*/following-sibling::td[1]//text() |
选取文本内容为‘400电话’节点的父节点后面第1个td节点的文本内容 |
| child::div | 所有属于当前节点的子元素的div节点 |
| child::* | 选取当前节点的所有子元素 |
| attribute::id | 选取当前节点的id属性 |
| attribute::* | 选取当前节点的所有属性 |
| child::text() | 选取当前节点的所有文本子节点 |
| child::node() | 选取当前节点的所有子节点 |
| descendant::div | 选取当前节点的所有div的后代元素 |
| ancestor::div | 选取当前节点的所有div 的先辈元素 |
| ancestor-or-self::div | 选取当前节点的所有div的先辈元素以及当前节点(如果此节点为div节点的话) |
| child::*/child::div | 选取当前节点的所有div孙节点 |
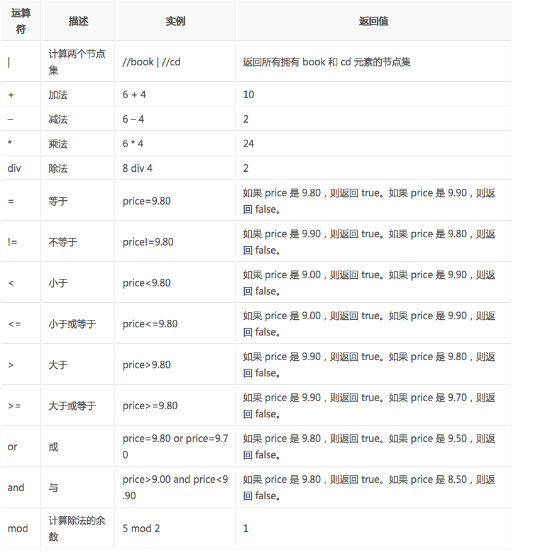
3.运算符
下面列出了可用在 XPath 表达式中的运算符:
二、lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用C实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath语法,来快速的定位特定元素以及节点信息。
1.安装
- 需要安装C语言库,可使用 pip 安装
sudo pip3 install lxml
2.简单使用(仅列出常见的一些操作)
-
etree
- 解析html数据,主要就是用到lxml库中的etree
In [1]: from lxml import etree #导入etree
- 解析html数据,主要就是用到lxml库中的etree
-
etree.HTML()
- 参数为字符串,读取字符串,返回html元素,并且会自动修正html代码,比如缺少html标签和body标签,则会自动添上
In [2]: text = ''' ...: <div> ...: <ul> ...: <li class="item-0"><a href="link1.html">first<br>item</a></li> ...: <li class="item-1"><a href="link2.html">second item</a></li> ...: <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li> ...: <li class="item-1"><a href="link4.html">fourth item</a></li> ...: <li class="item-0"><a href="link5.html">fifth item</a></li> ...: </ul> ...: </div> ...: ''' In [3]: html = etree.HTML(text) #读取字符串 In [4]: html #返回html元素 Out[4]: <Element html at 0x7f3ad0bb8340> In [5]: etree.tostring(html)#序列化成字节类型,并自动添上了html标签和body标签 Out[5]: b'<html><body><div>\n <ul>\n <li class="item-0"><a href="link1.html">first<br>item</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>\n <li class="item-1"><a href="link4.html">fourth item</a></li>\n <li class="item-0"><a href="link5.html">fifth item</a></li>\n </ul>\n</div>\n</body></html>'
- 参数为字符串,读取字符串,返回html元素,并且会自动修正html代码,比如缺少html标签和body标签,则会自动添上
-
etree.parse()
- 参数为文件名,从文件读取内容,返回_ElementTree
In [6]: html2 = etree.parse('./test.html',etree.HTMLParser())#从文件读取 In [7]: html2 #返回元素树 Out[7]: <lxml.etree._ElementTree at 0x7fc54d818d00> In [8]: etree.tostring(html2) Out[8]: b'<body>\n <div>\n <ul>\n <li class="item-0"><a href="link1.html">first<br>item</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>\n <li class="item-1"><a href="link4.html">fourth item</a></li>\n <li class="item-0"><a href="link5.html">fifth item</a></li>\n </ul>\n </div>\n</body>'
- 参数为文件名,从文件读取内容,返回_ElementTree
-
etree.tostring()
- 参数为元素或者元素树,序列化成字节类型
- 示例见etree.HTML()和etree.parse()
-
Element.xpath()或者_ElementTree.xpath()
- 参数是xpath表达式字符串,返回的是列表。如果表达式选取的是元素,则列表由元素组成。如果表达式选取的是属性,则列表由属性的值组成。如果表达式里面是以/text()结尾来取元素内容的话,则列表由内部的所有字符串内容所组成,比如内部以<br>标签将内容分成了多个部分,那么每个部分的内容都会显示出来。
In [9]: html.xpath('//a[contains(@href,"link")]') #使用模糊查询,查找href属性包含link的所有a标签,返回的是所有元素组成的列表 Out[9]: [<Element a at 0x7f9dc5830780>, <Element a at 0x7f9dc58309c0>, <Element a at 0x7f9dc59da540>, <Element a at 0x7f9dc4b7ba00>, <Element a at 0x7f9dc4ec8680>] In [10]: html.xpath('//a[contains(@href,"link")]/@href') #查找href属性的值,返回的是所有属性值组成的列表 Out[10]: ['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html'] In [11]: html.xpath('//a[contains(@href,"link")]/text()') #以列表的形式显示所有href属性包含link的a标签内容, Out[11]: ['first', 'item', 'second item', 'fourth item', 'fifth item'] In [12]: html.xpath('//a[contains(@href,"link1")]/text()') #第一个a标签内容通过<br>标签隔开,隔开的内容以列表的形式全部显示出来 Out[12]: ['first', 'item']
- 参数是xpath表达式字符串,返回的是列表。如果表达式选取的是元素,则列表由元素组成。如果表达式选取的是属性,则列表由属性的值组成。如果表达式里面是以/text()结尾来取元素内容的话,则列表由内部的所有字符串内容所组成,比如内部以<br>标签将内容分成了多个部分,那么每个部分的内容都会显示出来。
-
Element.tag
- 元素tag属性,返回元素标签名
In [13]: html.xpath('//a[contains(@href,"link1")]')[0].tag Out[13]: 'a'
- 元素tag属性,返回元素标签名
-
Element.get()
- 获取某个属性
-
Element.text
- 元素text属性,返回元素内容,如果内容是通过<br>标签隔开的,那么只能取到第一个值,取值会不完整
In [14]: html.xpath('//a[contains(@href,"link1")]')[0].text #text属性取内容,只会取内部第一个字符串 Out[14]: 'first' In [15]: html.xpath('//a[contains(@href,"link1")]/text()') #以text()结尾的xpath表达式,能够将标签内容以列表的形式完整显示 Out[15]: ['first', 'item']
- 元素text属性,返回元素内容,如果内容是通过<br>标签隔开的,那么只能取到第一个值,取值会不完整

 浙公网安备 33010602011771号
浙公网安备 33010602011771号