
python3 + Tensorflow + Faster R-CNN训练自己的数据
之前实现过faster rcnn, 但是因为各种原因,有需要实现一次,而且发现许多博客都不全面。现在发现了一个比较全面的博客。自己根据这篇博客实现的也比较顺利。在此记录一下(照搬)。
原博客:https://blog.csdn.net/char_QwQ/article/details/80980505
文章代码连接:https://github.com/endernewton/tf-faster-rcnn
显卡:TiTan RTX/Qudro K2200(丽台k2200)。--我分别在两张显卡都实现过
Python 3.6 + TensorFlow-gpu 1.2.0rc2 + Cuda8.0 + Cudnn v5.1
一、克隆代码
git clone https://github.com/endernewton/tf-faster-rcnn.git
二、根据你的显卡更改下对应的计算单元。
在tf-faster-rcnn/lib/setup.py的第130行。TiTan RTX对应的是sm_52, K2200对应的是sm_30。在这可以查看每种显卡对应的计算单元:http://arnon.dk/matching-sm-architectures-arch-and-gencode-for-various-nvidia-cards/
三、编译Cython
仍然在lib路径下,编译Cython模块(确保你已经安装了easydict, 如果没有,pip install easydict):
1. make clean 2. make 3. cd ..
四、安装COCO API.
这点按照GitHub的步骤走就ok,没啥错误:
1. cd data 2. git clone https://github.com/pdollar/coco.git 3. cd coco/PythonAPI 4. make 5. cd ../../..
五、下载数据:
Download the training, validation, test data and VOCdevkit
1. wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar 2. wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar 3. wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
Extract all of these tars into one directory named VOCdevkit
1. tar xvf VOCtrainval_06-Nov-2007.tar 2. tar xvf VOCtest_06-Nov-2007.tar 3. tar xvf VOCdevkit_08-Jun-2007.tar
It should have this basic structure
1. $VOCdevkit/ # development kit 2. $VOCdevkit/VOCcode/ # VOC utility code 3. $VOCdevkit/VOC2007 # image sets, annotations, etc. 4. # ... and several other directories ...
Create symlinks for the PASCAL VOC dataset
1. cd $FRCN_ROOT/data 2. ln -s $VOCdevkit VOCdevkit2007
注:这里有个小问题,我的软连接似乎不起作用了,于是我直接把VOCdevkit文件拷贝到tf-faster-rnn/data路径下,并重命名为VOCdevkit2007,记得删除那个VOCdevkit的软连接。
六、下载预训练模型
需要FQ,如果翻不了墙就从网盘下载吧。
链接:https://pan.baidu.com/s/1F8VfDKjlq9x42ZDrrvfx2A 密码:8ahl
七、建立预训练模型的软连接
在tf-faster-rcnn目录下建立output文件夹,并使用软连接来使用预训练模型,这里按照步骤走就行,没啥问题:
1. NET=res101 2. TRAIN_IMDB=voc_2007_trainval+voc_2012_trainval 3. mkdir -p output/${NET}/${TRAIN_IMDB} 4. cd output/${NET}/${TRAIN_IMDB} 5. ln -s ../../../data/voc_2007_trainval+voc_2012_trainval ./default 6. cd ../../..
八、对一些图片进行测试。
仍然按步骤走:
1. GPU_ID=0 2. CUDA_VISIBLE_DEVICES=${GPU_ID} ./tools/demo.py
九、 使用训练好的faster模型对数据进行测试。
这里有点地方需要修改:首先把tf-faster-rcnn/lib/datasets/voc_eval.py的第121行的
with open(cachefile,'w') as f
改成:
with open(cachefile,'wb') as f
同时还要把第105行的
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
改成:
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile.split("/")[-1].split(".")[0])
然后再按照步骤走就Ok了!
1. GPU_ID=0 2. ./experiments/scripts/test_faster_rcnn.sh $GPU_ID pascal_voc_0712 res101
测试结果:
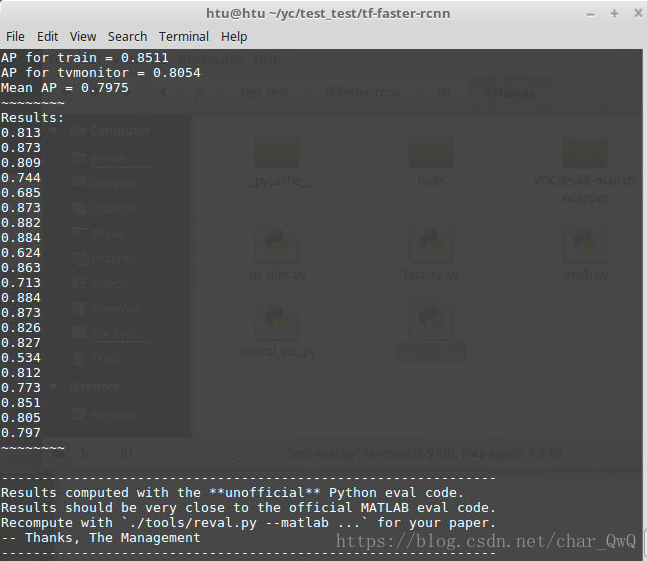
十、训练模型
这里按照步骤走可能会连不上外网,我把权重数据存网盘了。
网盘地址:https://pan.baidu.com/s/1aD0jlYGHhZQeeTvNJy0GGQ
密码:45ef
在data目录下创建一个imagenet_weights文件夹,解压权重数据并把解压后的vgg_16.ckpt重命名为vgg16.ckpy,因为后面在调用权重数据的时候需要对应的上。
开始训练(这里最后的vgg16就是对应的权重数据, 名字要对的上, 0是GPU的ID, pascal_voc是训练使用的数据集):
./experiments/scripts/train_faster_rcnn.sh 0 pascal_voc vgg16
为了节省时间并排除错误,我把迭代次数只设置了20次,把
./experiments/scripts/train_faster_rcnn.sh里的第22行把ITERS=70000改成ITERS=20,同时记得把./experiments/scripts/test_faster_rcnn.sh的ITERS也改成20.
注意:因为我使用的是pascal_voc数据集,所以只需要更改对应数据集的ITERS的就行了,训练和测试的都要改,因为在train_faster_rcnn.sh的末尾会执行test_faster_rcnn.sh
训练过程的loss:
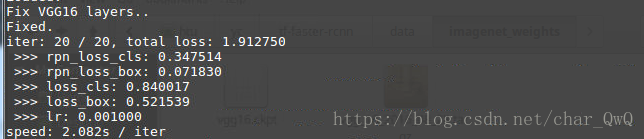
训练结果:
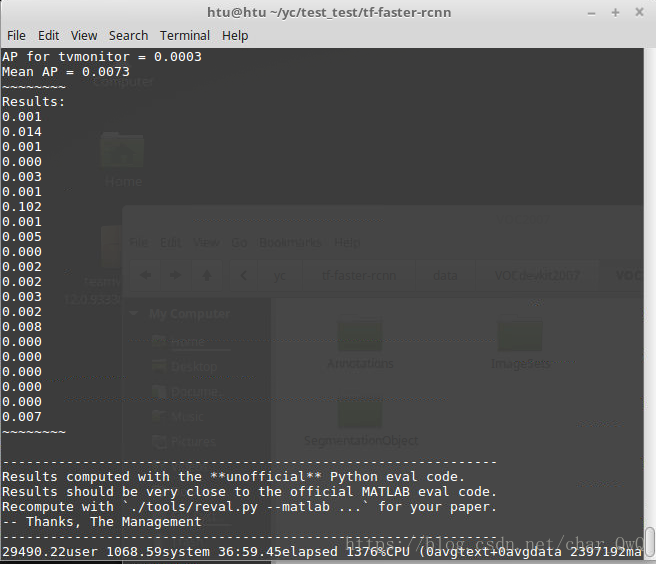
可以看到结果很差,因为就迭代了20轮。
十一、替换自己的数据
首先,在tf-faster-rcnn/lib/datasets目录下的pascal_voc.py里的第36行更改自己的类别,‘_background_'切记不可删掉,把后面的原来的20个label换成自己的,不用更改类别数目,也没有地方可以更改。
然后把你的xml文件放置在tf-faster-rcnn/data/VOCdevkit2007/Annotations路径下,记得把原来的删掉;同时把你的jpg文件放在
tf-faster/rcnn/data/VOCdevkit2007/VOC2007/JPEGImages路径下,xml和jpg替换完了,现在该txt了,把之前生成的四个txt文档放在tf-faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Layout 和tf-faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main。
在开始训练之前,还需要把产生的模型以及cache删除掉,分别在tf-faster-rcnn/output/vgg16/voc_2007_trainval/default路径下和tf-faster-rcnn/data/cache路径下,然后就可以开始训练了:
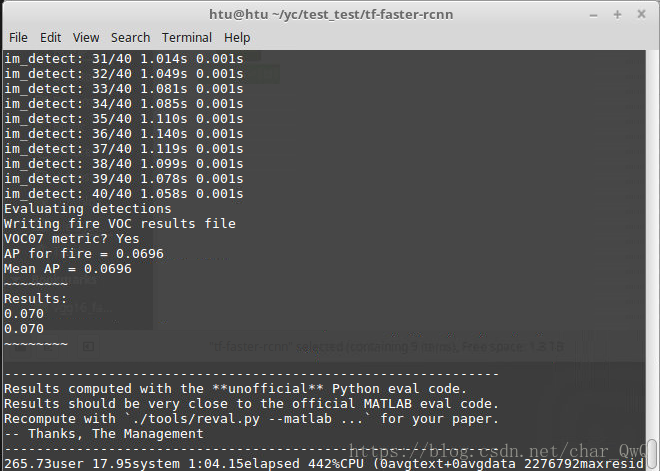
./experiments/scripts/train_faster_rcnn.sh 0 pascal_voc vgg16
因为我只训练了20轮,所以效果很差,不过能跑通就行了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号