1 redis高可用
# 主从复制存在的问题:
1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master--->哨兵
2 主从复制,只能主写数据,所以写能力和存储能力有限----》集群
# 案例
-一主两从,主写数据,从读数据
-如果主库挂掉,从库只能读,redis就不能对外提供服务了,它就不高可用
-即便主挂掉,选一个从库作为主库,继续对外提供服务
-原来的主库,又启动起来了,它现在作为从库
# 使用哨兵完成上面的事情 sentinel--》哨兵
##### 搭建步骤
# 搭建一主两从
# 配置3个哨兵
daemonize yes
dir ./data3
protected-mode no
bind 0.0.0.0
logfile "redis_sentinel3.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
port 26380
daemonize yes
dir ./data2
protected-mode no
bind 0.0.0.0
logfile "redis_sentinel3.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
port 26381
daemonize yes
dir ./data
protected-mode no
bind 0.0.0.0
logfile "redis_sentinel1.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
# 启动三个哨兵
./src/redis-sentinel sentinel_26379.conf
./src/redis-sentinel sentinel_26378.conf
./src/redis-sentinel sentinel_26377.conf
# 客户端连接到某一个redis上
info # 查看主从信息
# 客户端连到某个sentinel上(一个sentinel类似于一个redis-server,客户端可以连接)
redis-cli -p 26379 # 连到这个哨兵上
info
'''
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
'''
# 演示故障切换
# 停掉主库---》6379
# 哨兵认为主挂了,会自动选一个从库当主库
选择了6380作为主了
# 把6379启动,6379现在变成从库
# python连接redis---》写写到主库,读从从库中读---》一旦用了高可用(主库会变)---》python连接哨兵---》通过哨兵返回主,去写,返回从,去读
import redis
from redis.sentinel import Sentinel
# 连接哨兵服务器(主机名也可以用域名)
# 10.0.0.101:26379
sentinel = Sentinel([('127.0.0.1', 26379),
('127.0.0.1', 26380),
('127.0.0.1', 26381)
],
socket_timeout=5)
print(sentinel)
# 获取主服务器地址
master = sentinel.discover_master('mymaster')
print(master) # 返回所有主
# 获取从服务器地址
slave = sentinel.discover_slaves('mymaster')
print(slave) # 返回所有从
##### 读写分离
# 获取主服务器进行写入
master = sentinel.master_for('mymaster', socket_timeout=0.5)
w_ret = master.set('foo', 'bar')
slave = sentinel.slave_for('mymaster', socket_timeout=0.5)
r_ret = slave.get('foo')
print(r_ret)
2 redis集群
# 主从复制,只能主写数据,所以写能力和存储能力有限----》集群
# 存在问题
1 并发量:单机redis qps为10w/s,但是我们可能需要百万级别的并发量
2 数据量:机器内存16g--256g,如果存500g数据呢?
# 解决:加机器,分布式
redis cluster 在2015年的 3.0 版本加入了,满足分布式的需求
#分布式数据库
假设全量的数据非常大,500g,单机已经无法满足,我们需要进行分区,分到若干个子集中
# 分区方式
-哈希分布
# 原理:hash分区: 节点取余 ,假设3台机器, hash(key)%3,落到不同节点上
# 优点:热点数据分散 缺点:不利于批量查询
-顺序分布
# 原理:100个数据分到3个节点上 1--33第一个节点;34--66第二个节点;67--100第三个节点(很多关系型数据库使用此种方式,mysql通常用它)
# 缺点:热点数据太集中
# mysql 官方没有集群方案---》第三方解决方案---》顺序,哈希
# 哈希分区
-节点取余:后期扩容--》迁移数据总量大---》推荐翻倍库容
-一致性hash
-每个节点负责一部分数据,对key进行hash,得到结果在node1和node2之间,就放到node2中,顺时针查找
-扩容迁移数据迁移少,数据不均衡
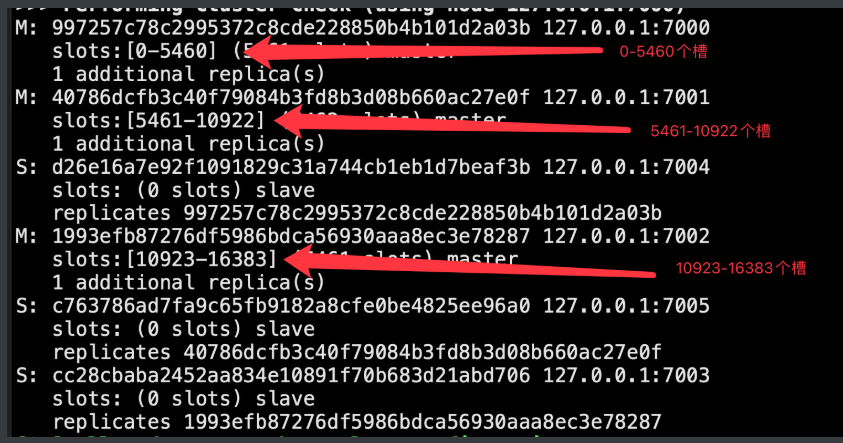
-虚拟槽分区(redis集群)
预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
良好的哈希函数:如CRC16
服务端管理节点、槽、数据:如redis cluster(槽的范围0–16383)
3.1 搭建
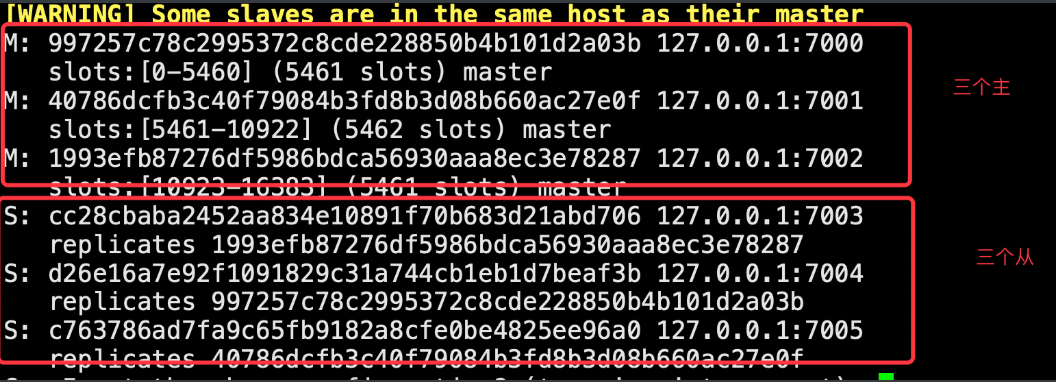
# 6台机器,3个节点的集群,另外三台做副本库(从库)
# 自动故障转移,3个主节点,如果有一个挂了,另外一个从库就会升级为主库
# redis的端口7000
# redis的端口7001
# redis的端口7002
# redis的端口7003
# redis的端口7004
# redis的端口7006
# 只要集群中有一个故障了,整个就不对外提供服务了,这个实际不合理,假设有50个节点,一个节点故障了,所有不提供服务了
port 7000
daemonize yes
dir "/root/s20/redis-5.0.7/data"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage yes
# 快速生成其他配置
sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf
sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf
sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf
sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf
sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf
# 启动6个节点
./src/redis-server ./redis-7000.conf
ps -ef |grep redis
./src/redis-server ./redis-7001.conf
./src/redis-server ./redis-7002.conf
./src/redis-server ./redis-7003.conf
./src/redis-server ./redis-7004.conf
./src/redis-server ./redis-7005.conf
### 客户端连上---》放数据--->想搭建集群---》集群模式没有分槽---》放的这个数据不知道放到哪个节点--》放不进去----》搭建完成才能写入数据
## 客户端链接上的命令:
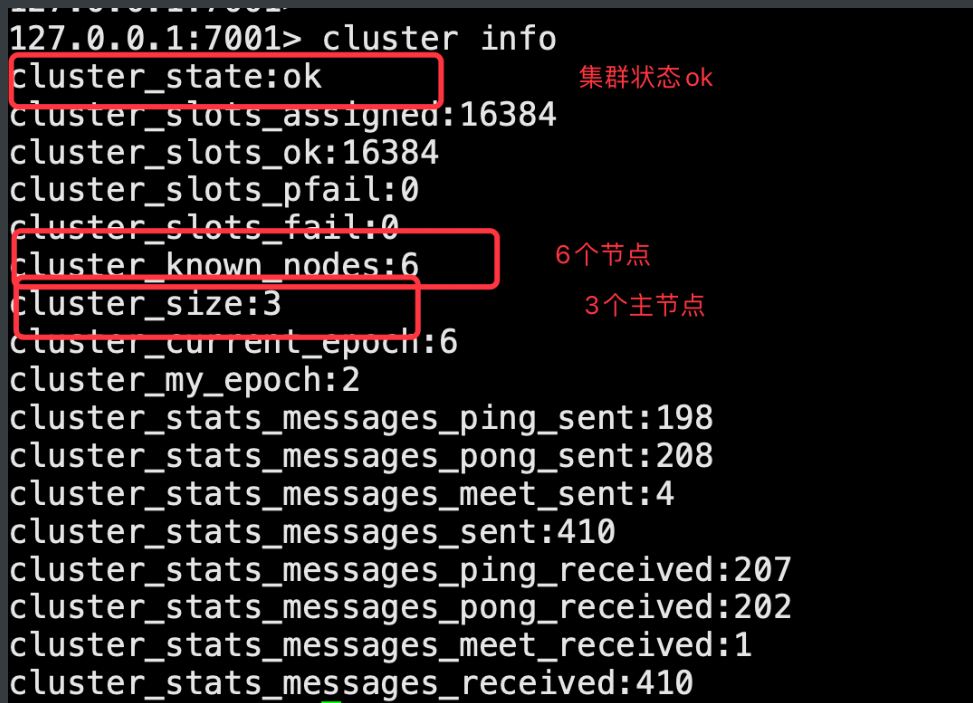
cluster nodes # 如果没有搭建完成,只能看到自己
cluster info # 集群状态是失败的
# 搭建集群 4.x以前版本,比较麻烦
-先meet
-指派槽
-建立主从
# 快速搭建集群 4.x以后,只需要这一条,自动meet,自动指派槽,自动建主从
# 注意这个数字---》指的是每个主节点有几个从节点
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
### 演示写入数据
-在7001上写入 name lqz
-去7002上查不到name
-对name crc16哈希运算完---》算完的槽--->知道哪个节点管了哪些槽---》告诉你去哪个节点存
-无论在哪个主节点,都能写入数据,获取数据
redis-cli -c -p 端口 # 以集群模式登陆,如果操作不到,自动重定向过去
# 演示故障转移
-7001 是个主库---》主库停掉--》7005从库会自动升级为主库
## 集群扩容
sed 's/7000/7006/g' redis-7000.conf > redis-7006.conf
sed 's/7000/7007/g' redis-7000.conf > redis-7007.conf
./src/redis-server ./redis-7006.conf
./src/redis-server ./redis-7007.conf
### 方式一
在7000上执行
redis-cli -p 7000 cluster meet 127.0.0.1 7006
redis-cli -p 7000 cluster meet 127.0.0.1 7007
### 方式二
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000
# 让7007做为7006的从
redis-cli -p 7007 cluster replicate 2d657119470fd7c65c366698f20cc104295b7555
#分槽
redis-cli --cluster reshard 127.0.0.1:7000
# 16384总共平均分配到4个节点,每个节点需要有:4096槽
数入4096 指定到7006节点上
自动从三个节点中的每个节点拿一部分槽放到7006身上,凑够4096个
# 缩容
# 下线迁槽(把7006的1366个槽迁移到7000上)--->把槽迁走
redis-cli --cluster reshard --cluster-from 2d657119470fd7c65c366698f20cc104295b7555 --cluster-to 997257c78c2995372c8cde228850b4b101d2a03b --cluster-slots 1365 127.0.0.1:7000
yes
redis-cli --cluster reshard --cluster-from 2d657119470fd7c65c366698f20cc104295b7555 --cluster-to c763786ad7fa9c65fb9182a8cfe0be4825ee96a0 --cluster-slots 1366 127.0.0.1:7005
yes
redis-cli --cluster reshard --cluster-from 2d657119470fd7c65c366698f20cc104295b7555 --cluster-to 1993efb87276df5986bdca56930aaa8ec3e78287 --cluster-slots 1366 127.0.0.1:7002
yes
# 忘记节点,关闭节点
redis-cli --cluster del-node 127.0.0.1:7000 1cddf0889d525516ad38a714ad5d38bead74dbcb # 先下从,再下主,因为先下主会触发故障转移
redis-cli --cluster del-node 127.0.0.1:7000 2d657119470fd7c65c366698f20cc104295b7555
#
# 关掉其中一个主,另一个从立马变成主顶上, 重启停止的主,发现变成了从
3 redis缓存优化
# 双写一致性
-定时更新
-增数据删缓存
-增数据改缓存
# redis自身有缓存更新策略---》redis占内存不能无限大,可以控制,内存就是满了
# 缓存更新策略
-LRU -Least Recently Used,没有被使用时间最长的
># LRU配置
>maxmemory-policy:volatile-lru
>(1)noeviction: 如果内存使用达到了maxmemory,client还要继续写入数据,那么就直接报错给客户端
>(2)allkeys-lru: 就是我们常说的LRU算法,移除掉最近最少使用的那些keys对应的数据,ps最长用的策略
>(3)volatile-lru: 也是采取LRU算法,但是仅仅针对那些设置了指定存活时间(TTL)的key才会清理掉
>(4)allkeys-random: 随机选择一些key来删除掉
>(5)volatile-random: 随机选择一些设置了TTL的key来删除掉
>(6)volatile-ttl: 移除掉部分keys,选择那些TTL时间比较短的keys
-LFU -Least Frequenty User,一定时间段内使用次数最少的
># LFU配置 Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式:
>volatile-lfu:对有过期时间的key采用LFU淘汰算法
>allkeys-lfu:对全部key采用LFU淘汰算法
># 还有2个配置可以调整LFU算法:
>lfu-log-factor 10
>lfu-decay-time 1
># lfu-log-factor可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
># lfu-decay-time是一个以分钟为单位的数值,可以调整counter的减少速度
-FIFO -First In First Out
### 缓存穿透--(缓存中没有,数据中也没有---》基本是恶意攻击)
#描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
#解决方案:
1 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
3 通过布隆过滤器实现---》把数据库中存在的数据,放到布隆过滤器中--》查的时候,去布隆过滤器查一下在不在---》在的话,继续往后走,不在的话直接给前端错误
### 缓存击穿(缓存中没有,数据库中有)
#描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
#解决方案:
设置热点数据永远不过期。
### 缓存雪崩
#描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
# 解决方案:
1 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
3 设置热点数据永远不过期。

