模型层 ORM 操作
内容概要
- pycharm 与 Django 连接 MySQL 数据库
- Django 版本的区别
- ORM 简介
- 字段的增删改查
- 数据的增删改查
- ORM 创建表关系
- 单表查询以及测试环境
- 必知必会13条
- 双下划线查询
- 多表操作
- 外键的增删改查
- 正反向的概念
- 基于对象的跨表查询
- 基于双下划线的跨表查询
- 聚合查询
- 分组查询
- Django 后台 admin 的使用
内容详细
pycharm 与 Django 连接 MySQL 数据库
首先,得启动 MySQL 服务端
其次,创建一个新的数据库
最后,才开始连接数据库
pycharm 连接 MySQL
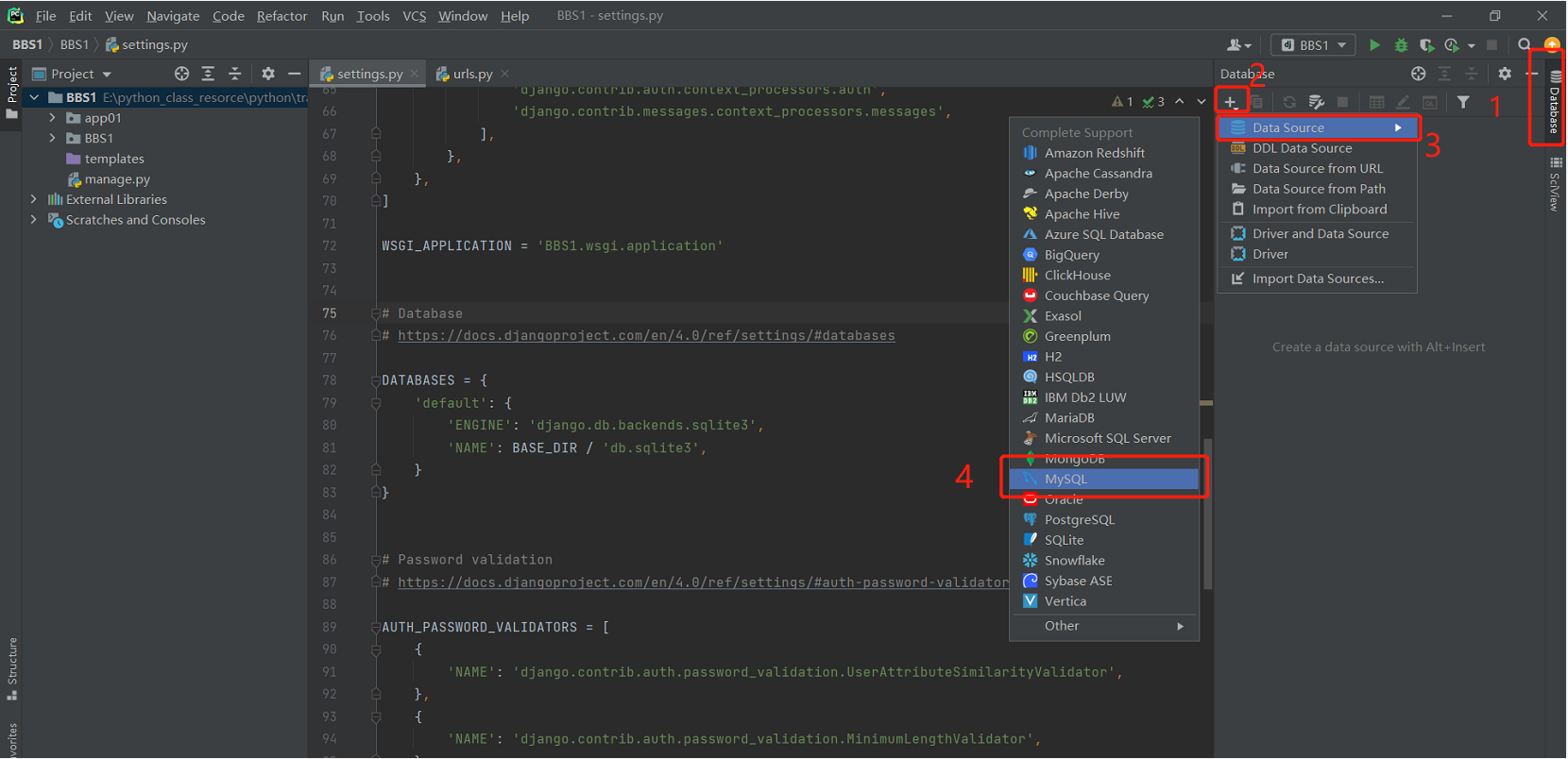
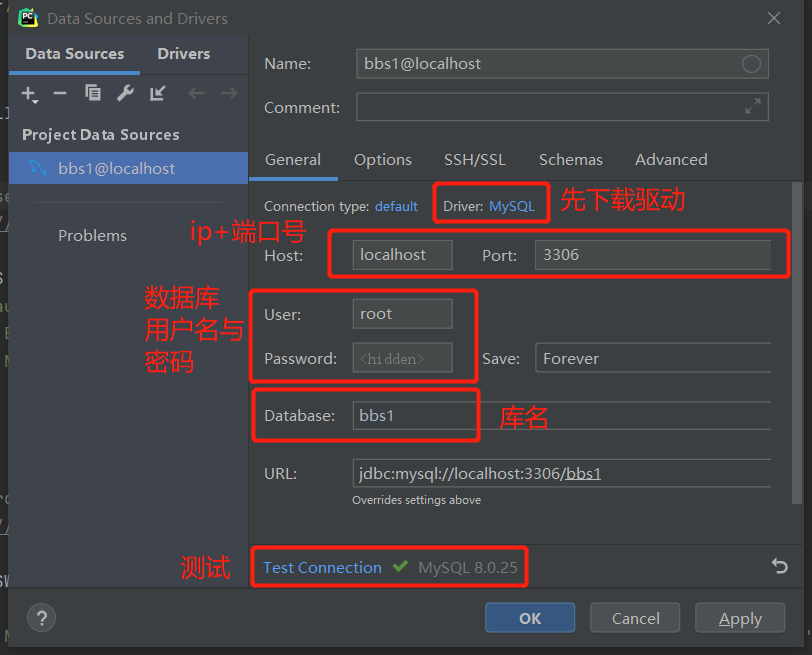
Django 连接 MySQL
1、修改settings.py 配置文件中 数据库的配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'bbs1',
'USER': 'root',
'PASSWORD': '123',
'HOST': '127.0.0.1',
'PORT': 3306,
'CHARSET': 'utf8',
}
}
2、在 init 文件中把mysqldb替换成pymysql连接数据库
import pymysql
pymysql.install_as_MySQLdb()
3、在models.py 中创建对象与表关系映射
class UserInfo(AbstractUser):
phone = models.BigIntegerField(verbose_name='电话号码', null=True, blank=True) # null是告诉数据库不能为空,blank才是在后台不用填写
avatar = models.FileField(upload_to='avatar/', default='avatar/3_mm.jpg')
create_time = models.DateField(auto_now_add=True)
blog = models.OneToOneField(to='Blog', null=True, on_delete=models.CASCADE)
class Meta:
verbose_name_plural = '用户表' # 修改后台管理的默认表名
def __str__(self):
return self.username
class Blog(models.Model):
site_name = models.CharField(max_length=32, verbose_name='站点名称')
site_title = models.CharField(max_length=32, verbose_name='站点标题')
# 存放样式文件路径
site_theme = models.CharField(max_length=64, verbose_name='站点样式')
class Meta:
verbose_name_plural = '个人站点表'
def __str__(self):
return self.site_name
4、执行迁移命令
python manage.py makemigrations
python manage.py migrate
Django 版本的区别
区别1: urls.py 文件路由配置:
# Django 1.0 使用的是 url
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^library/', views.library),
]
# Django 2.0 和 Django 3.0 使用的是 path
urlpatterns = [
path('admin/', admin.site.urls),
]
区别2: urls.py 路由中正则匹配:
# Django 1.0 默认使用正则
urlpatterns = [
url(r'^admin/$', admin.site.urls),
url(r'^library/', views.library),
]
# Django 2.0 和 Django 3.0 默认不使用正则,如果需要使用,则导入re_path
from django.urls import path, include, re_path
urlpatterns = [
path('admin/', admin.site.urls),
re_path('media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}),
]
# 虽然2以上版本path不支持正则匹配,但配备转换器,也可以用于接收参数,传给视图函数
path('app01/<int:num>', views.login, name='app01'),
区别3: ORM操作中建立外键时,2和3版本不会像1版本一样自动为外键添加级联更新级联删除,需要手动添加 on_delete 参数
class UserInfo(AbstractUser):
phone = models.BigIntegerField(verbose_name='电话号码', null=True, blank=True) # null是告诉数据库不能为空,blank才是在后台不用填写
avatar = models.FileField(upload_to='avatar/', default='avatar/3_mm.jpg')
create_time = models.DateField(auto_now_add=True)
blog = models.OneToOneField(to='Blog', null=True, on_delete=models.CASCADE) # 添加级联更新删除
ORM 简介
什么是ORM
即Object-Relationl Mapping,它的作用是在关系型数据库和对象之间作一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了 。
from django.db import models
关键的模块,每个类需要继承 models.Model
ORM 是 对象映射关系程序
通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言;
python与MySQL映射关系
| Python | 映射 | MySQL |
|---|---|---|
| 类 | -------> | 表 |
| 对象 | -------> | 表里面的数据 |
| 对象点属性 | -------> | 字段对应的值 |
ORM 常用字段和字段参数
AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField
一个整数类型,范围在 -2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存,)
CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
这里需要知道的是Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段,但是Django允许我们自定义新的字段,下面我来自定义对应于数据库的char类型
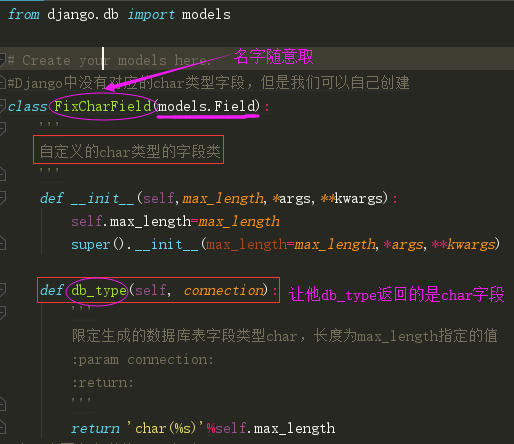
自定义字段在实际项目应用中可能会经常用到,这里需要对他留个印象!
自定义及使用
DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
字段合集(争取记忆)
字段合集
ORM字段与MySQL字段对应关系
字段参数
null
用于表示某个字段可以为空。
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
如果db_index=True 则代表着为此字段设置索引。
default
为该字段设置默认值。
DateField和DateTimeField
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
一对多 ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
字段参数
to
设置要关联的表
to_field
设置要关联的表的字段
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
db_constraint
是否在数据库中创建外键约束,默认为True。
其余字段参数
def func():
return 10
class MyModel(models.Model):
user = models.ForeignKey(
to="User",
to_field="id",
on_delete=models.SET(func)
)
一对一 OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。(通俗的说就是一个人的所有信息不是放在一张表里面的,简单的信息一张表,隐私的信息另一张表,之间通过一对一外键关联)
字段参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。(参考上面的例子)
字段的增删改查
# 原来的表
class user(models.Model):
username = models.CharField(max_length=32)
# 增加字段(两种方法)
password = models.IntegerField('密码',null=True) # 该字段可以为空
is_delete = models.IntegerField(default=0) # 默认值
# 修改字段
直接改代码,然后执行makemigrations,数据库迁移
# 删除
直接删除或者注释掉代码,然后执行makemigrations,数据库迁移
数据的增删改查
数据-增:
ORM增添数据有两种方式,一种是直接以对象的save方法保存,另一种是使用 object 的 create方法
from app01 import models # 导入model模块
username = 'elijah'
password = '123'
# 1、以对象的方式保存
user_obj = models.User(username=username, password=password)
user_obj.save()
# 2、create 方法
models.user.object.create(username=username, password=password)
'''具体什么时候用什么方法得看需求'''
数据-删:
先把要删除的数据过滤出来,再删除
models.user.object.filter(username=username).delete()
# 或者把对象找出来再删除
user_obj = models.User.object.filter(pk=1).first
user_obj.delete()
数据-改:
先把要更改的数据过滤出来,再修改
修改也有两种修改方式,一种是修改对象的属性值,另一种是object的 update 方法
# 1、对象
user_obj = models.user(username=username)
user_obj.username = 'jason'
user_obj.save()
# 2、update
model.user.object.filter(username=username).update(username='jason')
数据-查:
使用 filter
models.user.object.filter(username=username)
ORM 创建表关系
先创建表模型
# 博客文章表
class Article(models.Model):
title = models.CharField(max_length=64, verbose_name='文章标题')
desc = models.CharField(max_length=255, verbose_name='文章简介')
content = models.TextField(verbose_name='文章内容')
create_time = models.DateField(auto_now_add=True)
# 数据库字段设计优化
up_num = models.BigIntegerField(default=0, verbose_name='点赞数')
down_num = models.BigIntegerField(default=0, verbose_name='点踩数')
comment_num = models.BigIntegerField(default=0, verbose_name='评论数')
# 外键
blog = models.ForeignKey(to='Blog', on_delete=models.CASCADE, null=True)
category = models.ForeignKey(to='Category', on_delete=models.CASCADE, null=True)
tags = models.ManyToManyField(to='Tag',
through='Article2Tag',
through_fields=('article', 'tag')
)
class Meta:
verbose_name_plural = '文章表'
def __str__(self):
return self.title
# 博客站点表
class Blog(models.Model):
site_name = models.CharField(max_length=32, verbose_name='站点名称')
site_title = models.CharField(max_length=32, verbose_name='站点标题')
# 存放样式文件路径
site_theme = models.CharField(max_length=64, verbose_name='站点样式')
class Meta:
verbose_name_plural = '个人站点表'
def __str__(self):
return self.site_name
# 用户表
class UserInfo(AbstractUser):
phone = models.BigIntegerField(verbose_name='电话号码', null=True, blank=True) # null是告诉数据库不能为空,blank才是在后台不用填写
avatar = models.FileField(upload_to='avatar/', default='avatar/3_mm.jpg')
create_time = models.DateField(auto_now_add=True)
blog = models.OneToOneField(to='Blog', null=True, on_delete=models.CASCADE)
class Meta:
verbose_name_plural = '用户表' # 修改后台管理的默认表名
def __str__(self):
return self.username
# 标签表
class Tag(models.Model):
name = models.CharField(max_length=32, verbose_name='文章标签')
blog = models.ForeignKey(to='Blog', null=True, on_delete=models.CASCADE)
class Meta:
verbose_name_plural = '标签表'
def __str__(self):
return self.name
# 文章与标签多对多关系的关联表
class Article2Tag(models.Model):
article = models.ForeignKey(to='Article', on_delete=models.CASCADE)
tag = models.ForeignKey(to='Tag', on_delete=models.CASCADE)
表关系图:

一对多
博客文章表与分类表是一对多关系,一个分类里有篇文章,但一篇文章不可以有多个分类,文章是一对多关系中多的一方,外键创建在文章表中
category = models.ForeignKey(to='Category', on_delete=models.CASCADE, null=True)
一对一
站点表和用户信息表是一对一关系,每个用户都有自己的站点,外键创建在查询频率较高的表中(用户表)
blog = models.OneToOneField(to='Blog', null=True, on_delete=models.CASCADE)
多对多
文章表和标签表是多对多关系,一篇文章可以有多个标签,一个标签可以有多个文章,需要另创一张表来存储两表的对应关系,有三种创建方式
1、全自动创建
2、半自动(推荐)
3、手动创建
半自动(推荐):
# 文章与标签多对多关系的关联表
class Article2Tag(models.Model):
article = models.ForeignKey(to='Article', on_delete=models.CASCADE)
tag = models.ForeignKey(to='Tag', on_delete=models.CASCADE)
# 文章表中创建外键
tags = models.ManyToManyField(to='Tag',
through='Article2Tag',
through_fields=('article', 'tag')
)
单表查询以及测试环境
测试环境
创建好模型,并做好数据迁移之后,如果要对数据库表进行增删改查测试,可以创建一个测试文件
固定步骤:
1、创建测试文件 test.py
2、在 manage.py 文件中复制启动项目代码,并导入固定模块
3、导入models模块,开始测试
# test.py
from django.test import TestCase
# Create your tests here.
import os
if __name__ == '__main__':
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'BBS1.settings')
import django
django.setup()
from app01 import models
models.Tag.objects.create(name='elijah的标签三', blog_id=1)
必知必会13条
tips: pk 指代的是当前表的主键值
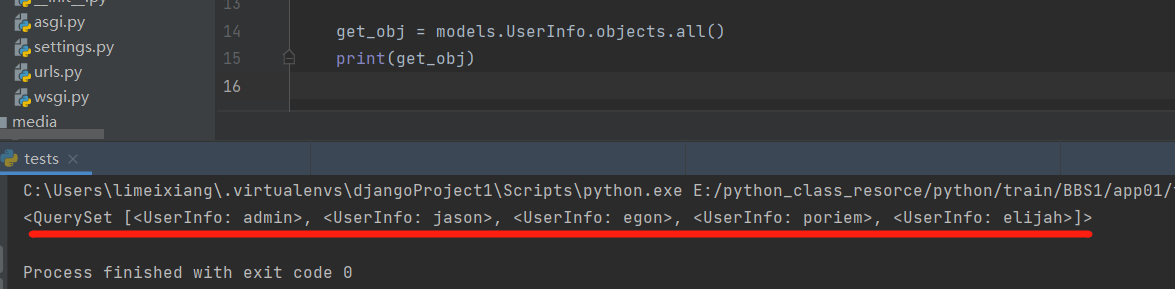
1 .all()
获取所有数据对象
get_obj = models.UserInfo.objects.all()
2 .filter(筛选条件)
获取符合条件的数据对象
get_obj = models.UserInfo.objects.filter(pk=5)
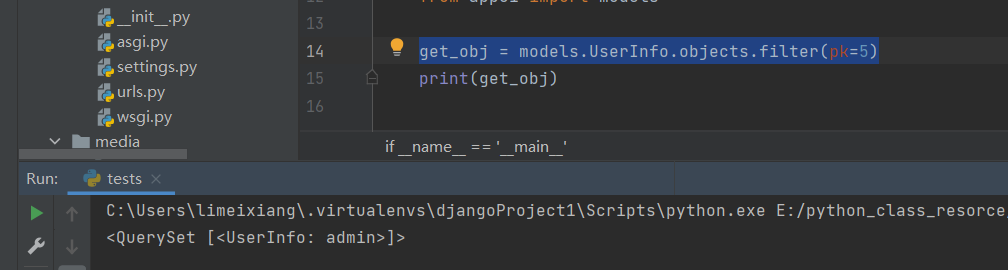
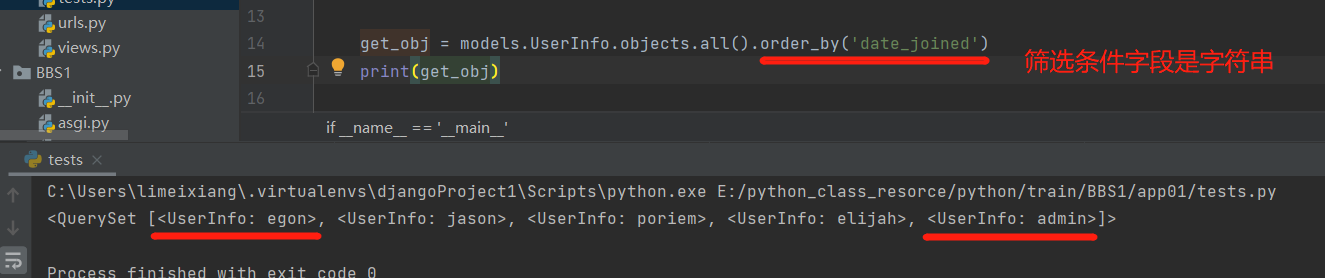
3 .order_by()
排序
get_obj = models.UserInfo.objects.all().order_by('date_joined')
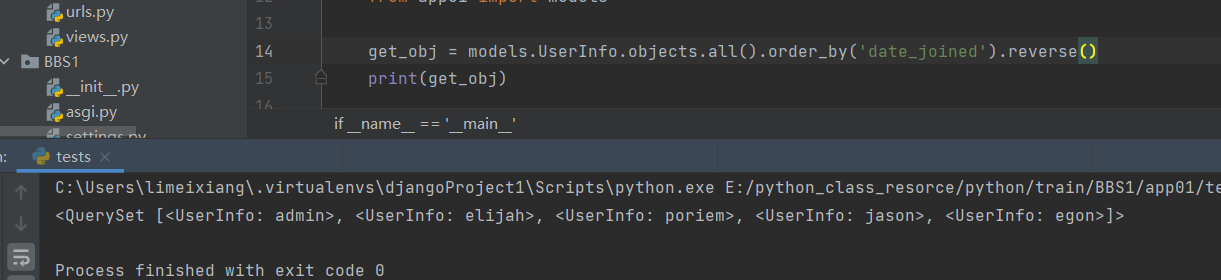
4 .reverse()
倒序
get_obj = models.UserInfo.objects.all().order_by('date_joined').reverse()
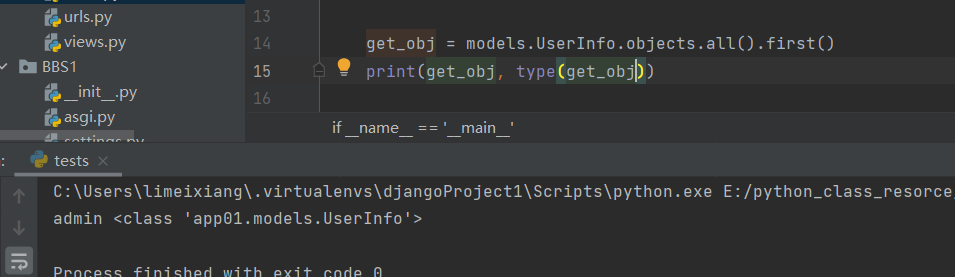
5 .first()
获取 QuerySet 对象中第一个具体对象
get_obj = models.UserInfo.objects.all().first()
print(get_obj, type(get_obj))
6 .last()
获取 QuerySet 对象中最后一个具体对象
get_obj = models.UserInfo.objects.all().last()
print(get_obj, type(get_obj))

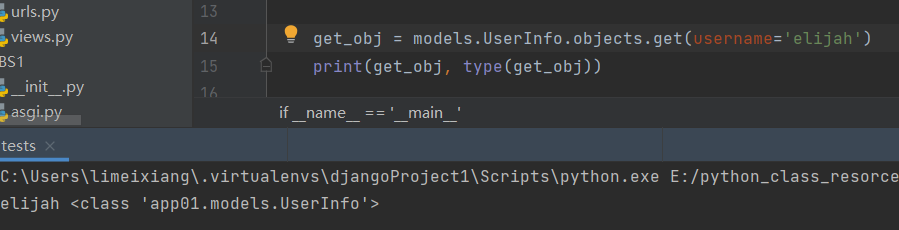
7 .get()
返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
get_obj = models.UserInfo.objects.get(username='elijah')
8 .values()
返回一个可迭代的字典序列
返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
get_obj = models.UserInfo.objects.all().values('username', 'phone')

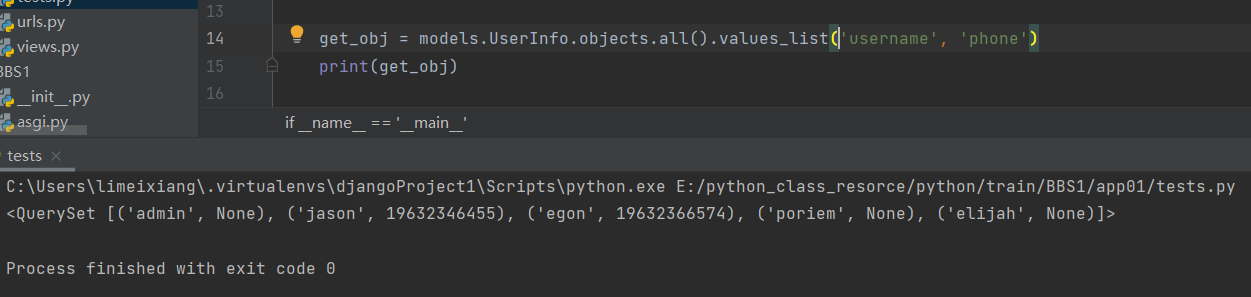
9 .values_list()
返回一个可迭代的元祖序列
它返回的是一个元组序列,values返回的是一个字典序列
get_obj = models.UserInfo.objects.all().values_list('username', 'phone')
10 .distinct()
从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。
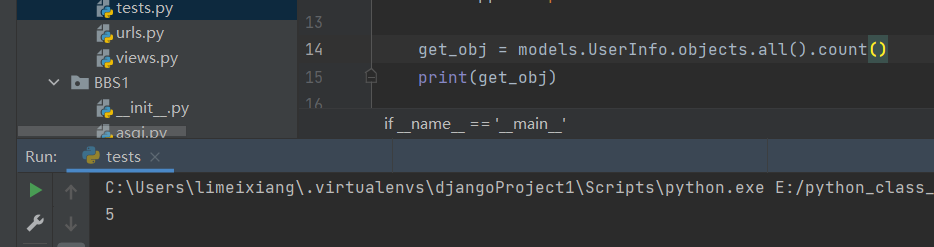
11 .count()
返回数据库中匹配查询(QuerySet)的对象数量
get_obj = models.UserInfo.objects.all().count()
12 .exists()
如果QuerySet包含数据,就返回True,否则返回False
get_obj = models.UserInfo.objects.filter(pk=1).exists()

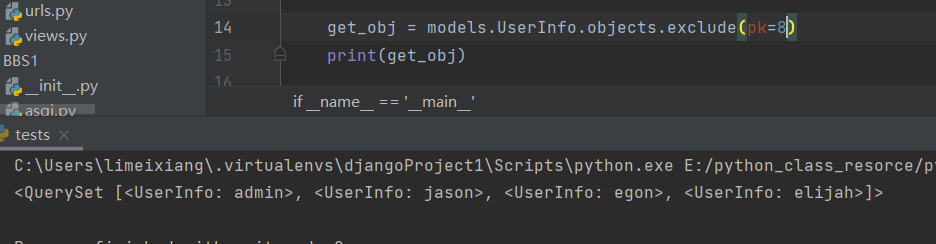
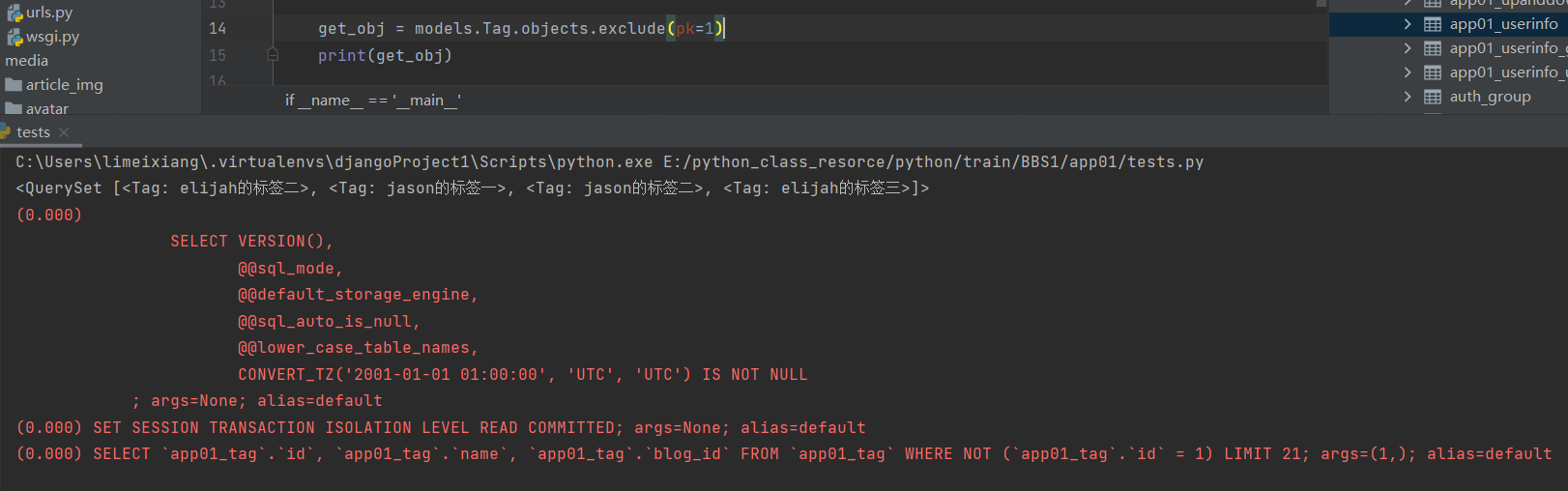
13 .exclude
它包含了与所给筛选条件不匹配的对象
get_obj = models.UserInfo.objects.exclude(pk=8)
PS:
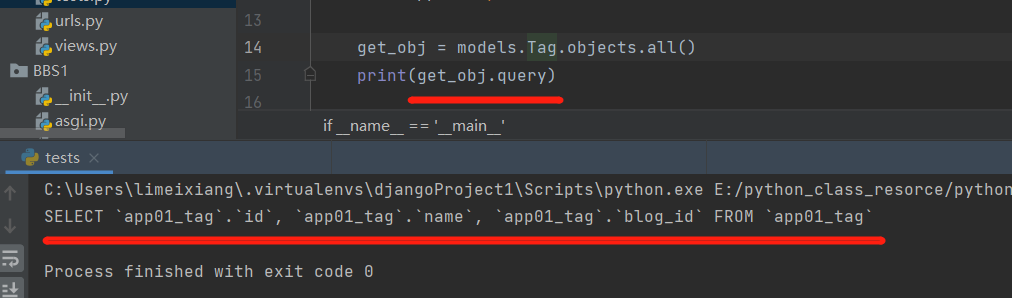
1、QuerySet 对象有 .query 属性可以查看原生的sql查询语句
get_obj = models.Tag.objects.all()
print(get_obj.query)
2、如果你想知道你对数据库进行操作时,Django内部到底是怎么执行它的sql语句时可以加下面的配置来查看
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
小总结
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
返回具体对象的
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有
count()
单表双下划线查询
get_obj = models.UserInfo.objects.filter(id__gt=8) # id 大于 8
get_obj = models.UserInfo.objects.filter(id__lt=8) # 小于
get_obj = models.UserInfo.objects.filter(id__in=[7, 8, 9])
get_obj = models.UserInfo.objects.filter(id__gte=8) # 大于等于
get_obj = models.UserInfo.objects.filter(id__lte=8) # 小于等于
get_obj = models.UserInfo.objects.filter(id__range=[8, 10])
get_obj = models.UserInfo.objects.filter(username__contains='elij') # 包含
get_obj = models.UserInfo.objects.filter(username__icontains='elij') # 大小写不敏感
get_obj = models.UserInfo.objects.filter(username__istartswith='e') # 以什么开头
get_obj = models.UserInfo.objects.filter(username__endswith='h') # 以什么结尾
# date字段还可以:
models.Class.objects.filter(first_day__year=2017)
# date字段可以通过在其后加__year,__month,__day等来获取date的特点部分数据
get_obj = models.UserInfo.objects.filter(date_joined__year=2020)
get_obj = models.UserInfo.objects.filter(date_joined__month=2)
get_obj = models.UserInfo.objects.filter(date_joined__day=20)
# date
#
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1))
# year
#
# Entry.objects.filter(pub_date__year=2005)
# Entry.objects.filter(pub_date__year__gte=2005)
# month
#
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6)
# day
#
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3)
# week_day
#
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2)
需要注意的是在表示一年的时间的时候,我们通常用52周来表示,因为天数是不确定的,老外就是按周来计算薪资的哦~
多表操作
外键的增删改查
一对多关系表
# 增
1、保存外键字段的id
models.UserInfo.objects.create(username='elijah', password='123', blog_id=1)
2、保存外键对象
blog_obj = models.Blog.objects.filter(pk=1).first()
models.UserInfo.objects.create(username='elijah', password='123', blog=blog_obj)
# 删 级联删除
models.UserInfo.objects.filter(pk=1).delete()
# 更新(修改)
1、修改外键字段的id
models.UserInfo.objects.filter(pk=1).update(blog_id=1)
2、修改外键对象
blog_obj = models.Blog.objects.filter(pk=1).first()
models.UserInfo.objects.filter(blog=blog_obj).
多对多关系表
多对多表外键的操作方法支持操作具体数值或者对象
# 增 add()
>>> author_objs = models.Author.objects.filter(id__lt=3)
>>> models.Book.objects.first().authors.add(*author_objs)
models.Book.objects.first().authors.add(*[1, 2])
# 删 remove()
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.remove(3)
# 更新(修改)注意得是可迭代对象 set()
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.set([2, 3])
# 清空相关书本对象的所有数据 clear()
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.clear()
正反向概念
外键字段在我表中,我查你就是正向
外键字段不在我表中,我查你就是反向
1、正向查找
1.对象查找(跨表)
要点:先拿到对象,再通过对象去查对应的外键字段,分两步
book_obj = models.Book.objects.first() # 第一本书对象(第一步)
print(book_obj.publisher) # 得到这本书关联的出版社对象
print(book_obj.publisher.name) # 得到出版社对象的名称
2.字段查找(跨表)
要点:利用Django给我们提供的神奇的双下划线查找方式
models.Book.objects.all().values("publisher__name")
#拿到所有数据对应的出版社的名字,神奇的下划线帮我们夸表查询
2、反向查找
1.对象查找
obj.表名_set
要点:先拿到外键关联多对一,一中的某个对象,由于外键字段设置在多的一方,所以这里还是借用Django提供的双下划线来查找
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象
books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书
titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名
结论:如果想通过一的那一方去查找多的一方,由于外键字段不在一这一方,所以用__set来查找即可
2.字段查找
要点:直接利用双下滑线完成夸表操作
titles = models.Publisher.objects.values("book__title")
基于对象的跨表查询
正向的对象查询
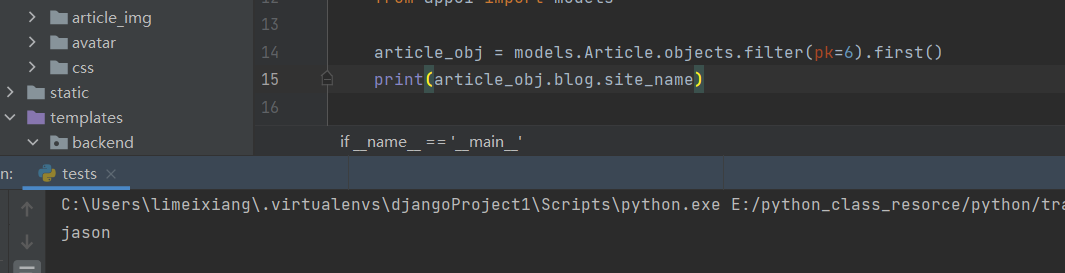
# 查询id为6的文章的站点名字
article_obj = models.Article.objects.filter(pk=6).first()
print(article_obj.blog.site_name)
反向的对象查询
# 查询名字为elijah的站点下所有的文章
site_obj = models.Blog.objects.filter(site_name='elijah').first()
print(site_obj.article_set.all())

基于双下划线的跨表查询
一般是直接查字段
# 查找 jason 的所有文章标题
dict1 = models.UserInfo.objects.filter(username='jason').values('blog__article__title')
print(dict1)

dict1 = models.UserInfo.objects.filter(username='jason').values('blog__site_name', 'blog__site_theme')
print(dict1)

聚合查询
aggregate()
是QuerySet 的一个终止子句,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
用到的内置函数:
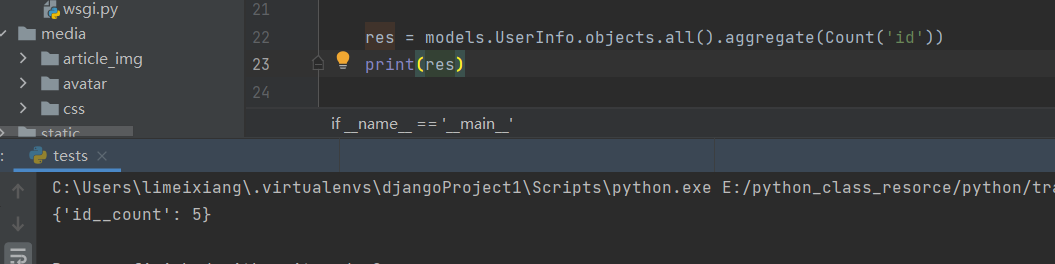
from django.db.models import Avg, Sum, Max, Min, Count
res = models.UserInfo.objects.all().aggregate(Count('id'))
print(res)
# 也可以指定 key 名称
res = models.UserInfo.objects.all().aggregate(user_cout=Count('id'))
print(res)
{'user_cout': 5}
分组查询
分组: annotate()
分组是按照 annotate() 前面的那个 values()中的字段来分组的
如果 annotate() 前面没有 values() 指定分组字段,则默认按照表id分组
下面例子是按照文章表中的 'blog' 字段分组
# select blog,count(id) from article group by blog
res = models.Article.objects.values('blog').annotate(a_count=Count('id')).values('blog', 'a_count')
print(res)
<QuerySet [{'blog': 1, 'a_count': 15}, {'blog': 2, 'a_count': 3}]>
总结
value里面的参数对应的是sql语句中的select要查找显示的字段,
filter里面的参数相当于where或者having里面的筛选条件
annotate本身表示group by的作用,前面找寻分组依据,内部放置显示可能用到的聚合运算式,后面跟filter来增加限制条件,最后的value来表示分组后想要查找的字段值
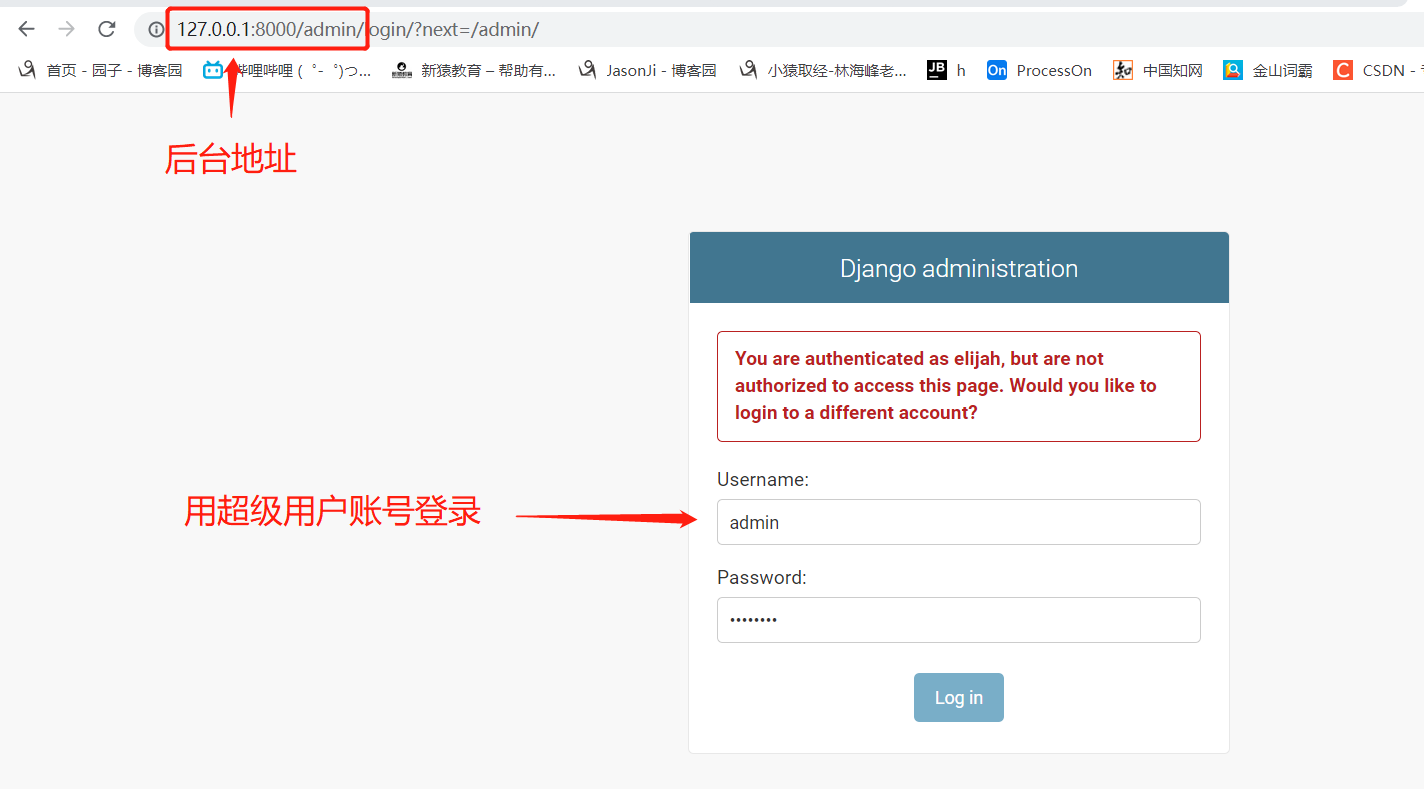
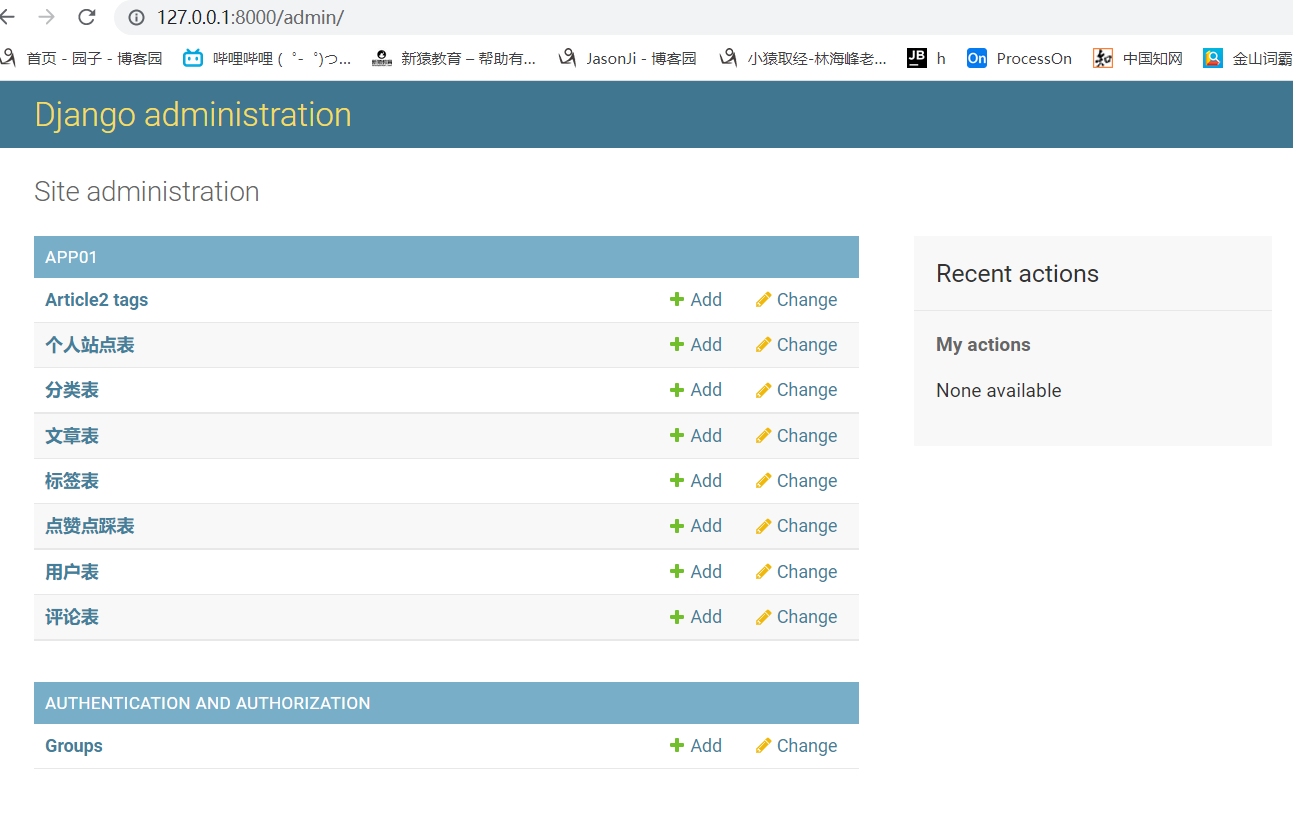
Django 后台 admin 的使用
Django 提供了一个可视化界面来方便我们来对模型表进行数据的增删改查
但我们首先得在 admin.py 文件中,对表进行注册
admin.py :
from django.contrib import admin
from app01 import models
# Register your models here.
admin.site.register(models.UserInfo)
admin.site.register(models.Blog)
admin.site.register(models.Category)
admin.site.register(models.Tag)
admin.site.register(models.Article)
admin.site.register(models.Article2Tag)
admin.site.register(models.UpAndDown)
admin.site.register(models.Comment)
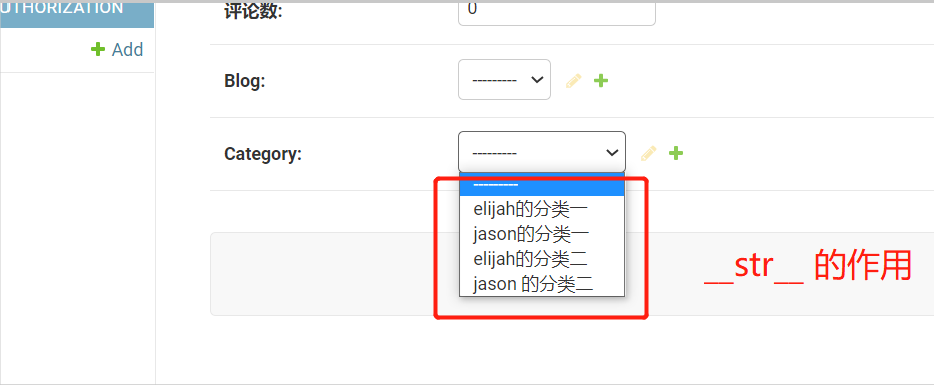
在模型表中添加 Meta 类,标注表名,添加 str 魔法方法,在选择该表时可以看到表名
class Category(models.Model):
name = models.CharField(max_length=32, verbose_name='文章分类')
blog = models.ForeignKey(to='Blog', null=True, on_delete=models.CASCADE)
class Meta:
verbose_name_plural = '分类表'
def __str__(self):
return self.name


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人