GIL解释器锁 & 进程池与线程池
今日内容
- GIL 全局解释器锁(重要理论)
- 验证 GIL 的存在及功能
- 验证 python 多线程是否有用
- 死锁现象
- 进程池与线程池(使用频率高)
- IO模型
详细参考:
https://www.bilibili.com/video/BV1QE41147hU?p=500
内容详细
一、GIL 全局解释器锁
1、简介
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
1、python解释器有很多版本,但默认使用的是 Cpython
Cpython、Jpython、pypython
在Cpython中GIL全局解释器锁也是一把互斥锁,主要用于阻止同一进程下多个线程被同时执行(在python的多线程无法使用多核优势,线程不能实现并行)
GIL 肯定存在于Cpython中,因为Cpython解释器的内存管理不是线性安全的。
2、内存管理 就是 垃圾回收机制
引用计数
标记清楚
分代回收
'''
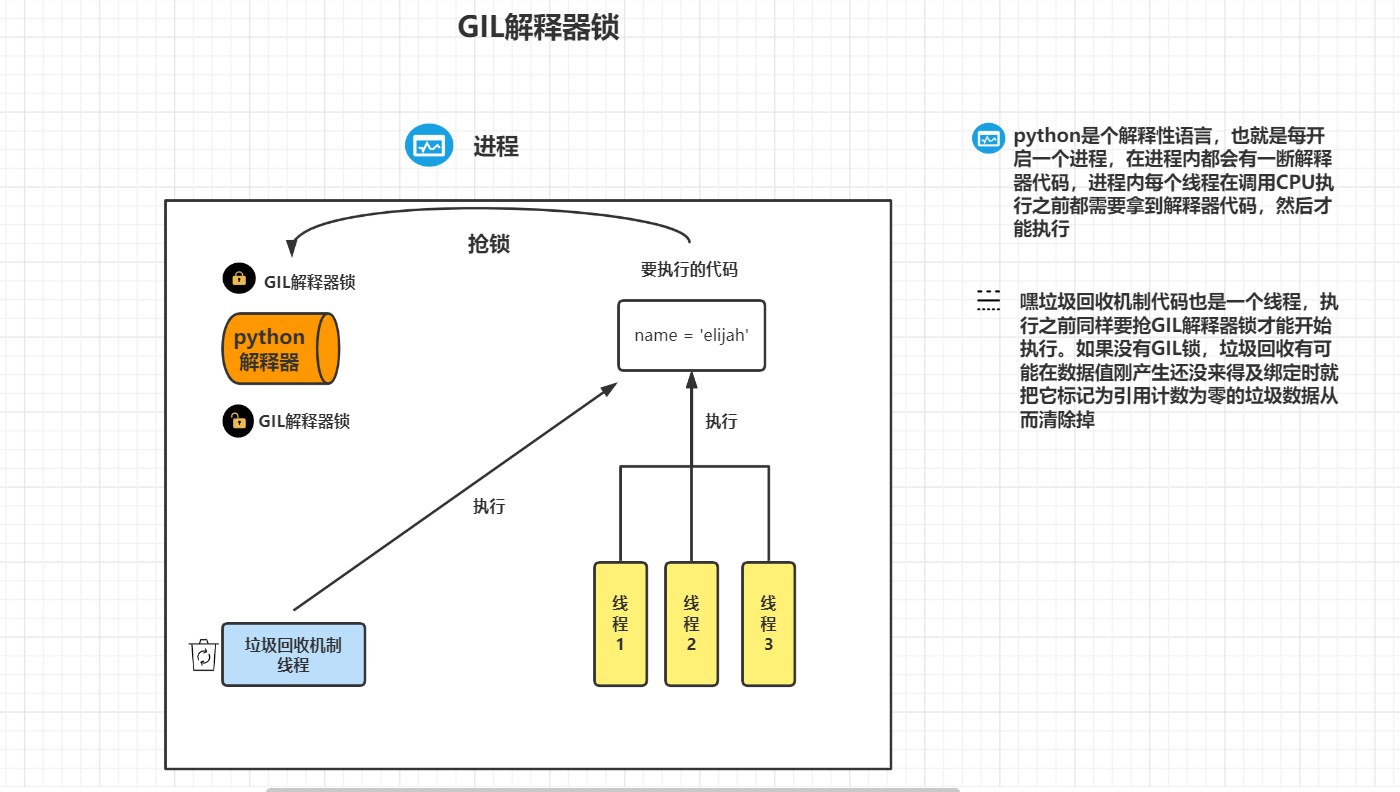
1、GIL是Cpython解释器的特点
2、python同一个进程内的多个线程无法使用多核优势(无法并行但能并发)
3、同一进程内多个线程想要运行必须先抢GIL锁
4、所有的解释型语言几乎都无法实现同一进程内多个线程同时运行
2、验证GIL的存在
同一个进程下的多个线程,如果没有IO操作,因为有GIL的存在是不会出现并行的效果的
但是如果线程内有IO操作还是会造成数据的错乱 这个时候需要我们额外的添加互斥锁
# 无 IO
from threading import Thread
import time
m = 100
def test():
global m
tmp = m
tmp -= 1
m = tmp
for i in range(100):
t = Thread(target=test)
t.start()
time.sleep(3)
print(m)
# 结果 0
# 出现 IO 操作 : time.sleep(1)
from threading import Thread
import time
m = 100
def test():
global m
tmp = m
time.sleep(1) < -- IO
tmp -= 1
m = tmp
for i in range(100):
t = Thread(target=test)
t.start()
time.sleep(3)
print(m)
# 结果 4秒后打印 99
二、死锁现象
互斥锁不可以随意使用,否则容易出现死锁现象:
在线程1 执行完fun1函数后开始执行func2函数,抢到了B锁,
但这时 线程2 也开始执行了 func1 抢到了A锁,
这时 线程1 无法抢到 A锁,停在原地,线程2也无法抢到B锁,停在原地
from threading import Thread, Lock
import time
A = Lock()
B = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A.acquire()
print('%s 抢到了A锁' % self.name) # current_thread().name 获取线程名称
B.acquire()
print('%s 抢到了B锁' % self.name)
time.sleep(1)
B.release()
print('%s 释放了B锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
def func2(self):
B.acquire()
print('%s 抢到了B锁' % self.name)
A.acquire()
print('%s 抢到了A锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
B.release()
print('%s 释放了B锁' % self.name)
for i in range(10):
obj = MyThread()
obj.start()
"""就算知道锁的特性及使用方式 也不要轻易的使用 因为容易产生死锁现象"""
三、python 多线程是否没用?
python 多线程是否没用?
(python的多进程是可以利用多核优势的,同一进程内多线程无法利用多核优势是因为GIL的存在)
这是要分情况而论的,主要看代码是 IO密集型的,还是 计算密集性的
-
IO密集型:
代码中有大量的IO操作,遇到IO 操作时,根据多道技术,CPU会切换到别的线程去运行
-
计算密集型:
代码中无IO操作,且运行速度快时间短,CPU不会进行切换,就无法使用多核优势
# 是否有用需要看情况而定(程序的类型)
# IO密集型
eg:四个任务 每个任务耗时10s
开设多进程没有太大的优势 10s+
遇到IO就需要切换 并且开设进程还需要申请内存空间和拷贝代码
开设多线程有优势
不需要消耗额外的资源 10s+
# 计算密集型
eg:四个任务 每个任务耗时10s
开设多进程可以利用多核优势 10s+
开设多线程无法利用多核优势 40s+
"""
多进程结合多线程
"""
"""IO密集型"""
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(400):
p=Process(target=work) #耗时22.31s多,大部分时间耗费在创建进程上
# p=Thread(target=work) #耗时2.08s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
"""计算密集型"""
(使用同一进程内多线程就会运行时间变长)
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
print(os.cpu_count()) # 本机为6核
start=time.time()
for i in range(6):
# p=Process(target=work) #耗时5.35s多
p=Thread(target=work) #耗时23.37s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
四、进程池与线程池
进程池和线程池的出现,是降低了代码的执行效率,但是保证了计算机硬件的安全
思考:能否无限制的开设进程或者线程???
肯定是不能无限制开设的
如果单从技术层面上来说无限开设肯定是可以的并且是最高效的
但是从硬件层面上来说是无法实现的(硬件的发展永远赶不上软件的发展速度)
池
在保证计算机硬件不奔溃的前提下开设多进程和多线程
降低了程序的运行效率但是保证了计算机硬件的安全
进程池与线程池
进程池:提前开设了固定个数的进程 之后反复调用这些进程完成工作(后续不再开设新的)
线程池:提前开设了固定个数的线程 之后反复调用这些线程完成工作(后续不再开设新的)
创建线程池
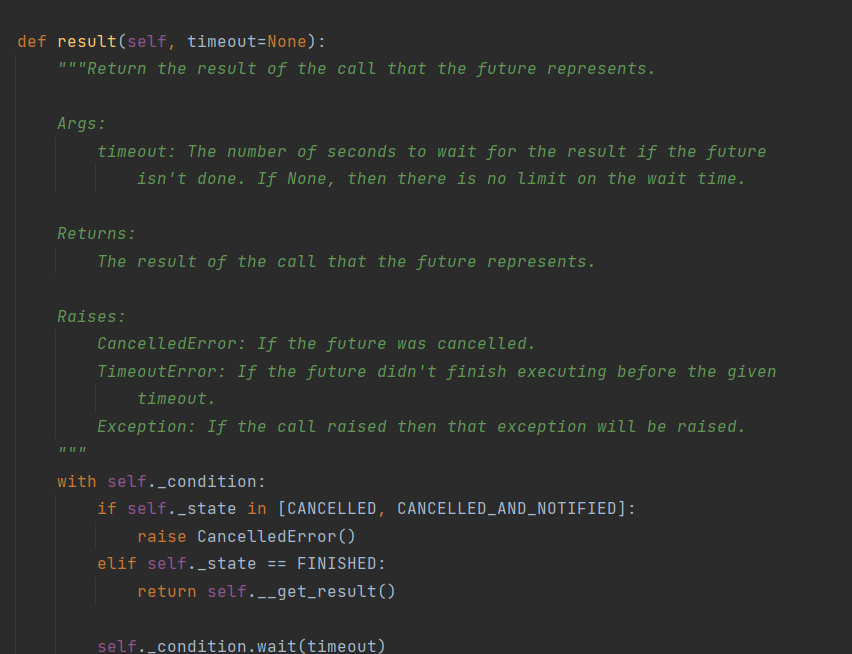
注意:开始多线程与多进程时,如果遇到同步提交任务的操作,如 .join 和 .resutl,可以先把所有进程(线程)先开启,再逐一调用他们的同步操作
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import time
import os
def run():
print('开始运算')
index = 10
time.sleep(0.3)
for i in range(10):
index += i
return '结果为: %s' % index
if __name__ == '__main__':
print('本机CPU数量: %s' % os.cpu_count())
# 开启10个线程,先把所有任务提交给线程池(异步提交),再把得到的操作对象放入列表,方便后续调用 .result()方法(同步提交)
t_list = []
# p = ProcessPoolExecutor() 创建进程池,默认进程数是本机的CPU数
t_pool = ThreadPoolExecutor() # 创建线程池,默认线程数是本机CPU数乘以5
for i in range(10):
# 创建线程之后需要提交函数
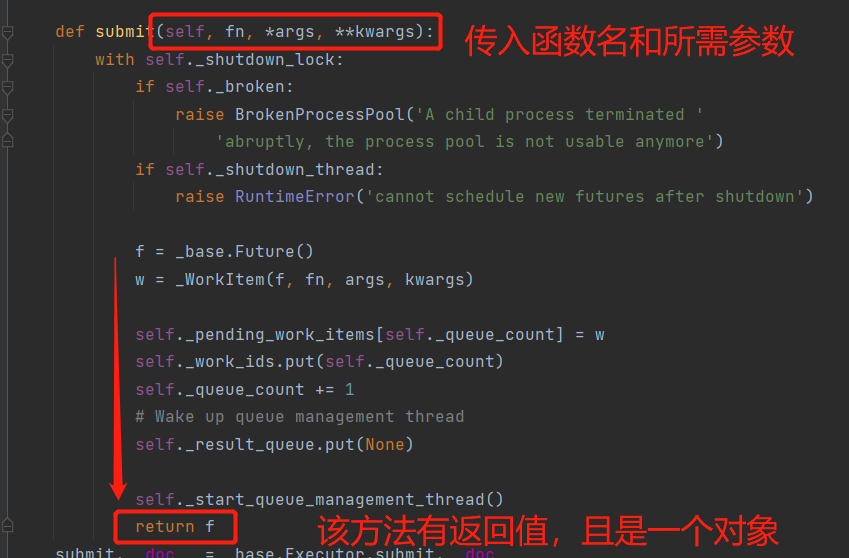
t = t_pool.submit(run) # 异步 submit() 方法返回的是线程对象
t_list.append(t)
for t in t_list:
ret = t.result() # 同步 提交的任务需要有返回值
print(ret)
# 运行结果
本机CPU数量: 4
开始运算
开始运算
开始运算
开始运算
开始运算
开始运算
开始运算
开始运算
开始运算
开始运算
结果为: 55
结果为: 55
结果为: 55
结果为: 55
结果为: 55
结果为: 55
结果为: 55
结果为: 55
结果为: 55
结果为: 55