内容概要
- 内置函数(可与匿名函数一起使用)
- 可迭代对象
- 迭代器对象
- for循环内部原理
- 异常处理
内容详细
一、内置函数
# 1、 map() 映射
l1 = [1, 3, 5, 7, 9]
res = map(lambda x:x**2, l1) # 返回一个迭代器对象,可循环取出元素
print(list(res)) # [1, 9, 25, 49, 81]
# 2、zip() 拉链
list1 = ['name', 'age', 'hobby']
list2 = ['elijah', 18, 'read']
# 把上面两个列表相同索引的元素组成列表套元组的形式:[('name','elijah'),(),()]
# for循环:
l = []
for i in range(len(list1)):
l.append((list1[i], list2[i]))
print(l)
# zip()函数
print(list(zip(list1, list2))) # [('name', 'elijah'), ('age', 18), ('hobby', 'read')]
'''而且就算两个列表中的元素个数不一致,使用这个函数也不会报错,会以最短的列表为准'''
'''zip(list1, list2, list3, list4)函数还可以接收多个列表'''
# 3、max() 和 min(), 找出数据集理的最大值和最小值
# 列表
list1 = [2, 4, 5, 6, 7, 8, 9, 33]
print(max(list1))
print(min(list1))
# 字典,比较的是字典的key值
dict1 = {
'jason': 30000,
'elijah': 500000,
'tony': 6000000,
'kevin': 10000000000
}
print(max(dict1)) # tony
print(min(dict1)) # elijah
# A-Z 65-90
# a-z 97-122
# 比较字典的values值, 在函数后面添加key=的值,用户匿名函数返回字典的value值
print(max(dict1, key=lambda key: dict1[key])) # kevin
print(min(dict1, key=lambda key: dict1[key])) # jason
# 4、filter() 过滤器
# filter(function or None, iterable) --> filter object
list1 = [2, 4, 5, 6, 7, 8, 9, 33]
print(list(filter(lambda x: x > 7, list1))) # [8, 9, 33]
# 5、reduce() 归总 functools模块里
# reduce(function, sequence, initial=None)
# reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates ((((1+2)+3)+4)+5)
from functools import reduce
list1 = [2, 4, 5, 6, 7, 8, 9, 33]
print(reduce(lambda x, y: x + y, list1)) # 74
res1 = reduce(lambda x, y: x + y, list1, 100) # 还可以额外添加元素值
二、可迭代对象
# 什么是迭代?
迭代即是更新换代,每一次更新换代都是基于上一次的结果形成的
# 可迭代对象由哪些?
内置方法中有"双下划iter"内置方法的就是可迭代对象 __iter__
# 内置方法
数据类型加"."就可以看到自带的内置方法,就是函数功能,有些是带双下划线的,读作"双下划+方法名",与面向对象名"__name(隐藏变量)"区分开
无__iter__内置方法的数据类型:
int、float
有__iter__内置方法的类型:
str,list,dict,tuple,set,file(文件类型)
字符串 列表 字典 元组 集合 文件对象
支持for循环取值
# 可迭代对象.__iter__ --> 可迭代对象会转变成迭代器对象,
# 会增加一个__next__内置方法,这个方法执行一次就取出一个可迭代对象里的值
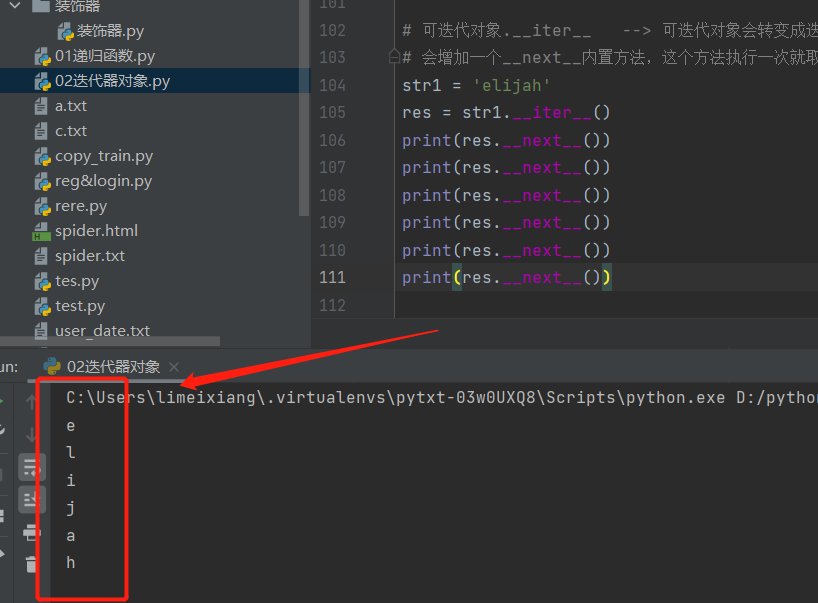
str1 = 'elijah'
res = str1.__iter__()
print(res.__next__())
print(res.__next__())
print(res.__next__())
print(res.__next__())
print(res.__next__())
print(res.__next__())
# 取完元素之后再取会"报错"
三、迭代器对象
# 文件类型本身就自带__next__内置方法,是个迭代器对象,再使用__iter__()方法也还是个迭代器对象,不受影响
res = open('a.txt', 'w', encoding='utf8')
res.__iter__()
res.__next__()
'''
迭代器对象
即含有__iter__方法,又含有__next__方法
如何生成迭代器对象
让可迭代对象执行__iter__方法
迭代器对象无论执行多少次__iter__方法,还是迭代器对象
迭代器给我们提供了不依赖于索引取值的方式
'''
四、for 循环遍历取值原理
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
res = list1.__iter__ # 把可迭代对象转变成迭代器对象
while True:
try:
print(res.__next__())
except Exception:
break
# 无限循环取出列表里面的值,当取完之后会报错,做异常处理
'''
for循环内部原理
1.将关键字in后面的数据先调用__iter__方法转为迭代器对象
2.循环执行__next__方法
3.取完之后__next__会报错,但是for循环会自动捕获该错误并处理
'''
五、异常处理
# 什么是异常?
当程序逻辑有错时,运行之后会报错,并停止运行,不再执行下面的代码
# 异常三个重要组成部分
1.traceback
翻到最下面从下往上的第一个蓝色字体鼠标左键点击即可跳转到错误的代码所在的行
2.XXXError
错误的类型
3.错误类型冒号后面的内容
错误的详细原因(很重要 仔细看完之后可能就会找到解决的方法)
# 错误的种类
1.语法错误
不被允许的 出现了应该立刻修改
2.逻辑错误
可以被允许的 出现了之后尽快修改即可 # 修改逻辑错误的过程其实就是在从头到尾理清思路的过程
# 异常处理:
把有可能出错的代码放进异常处理的代码里,出错时会接收错误信息并可返回,继续执行剩余的代码
try:
print(name)
int('abc')
except NameError as e:
print('变量名错误')
except ValueError as e:
print('值错误')
except Exception:
print('可以接收任何报错类型')
# 异常处理使用注意:
1、尽量只在有可能出错的代码段才使用
2、异常处理中的代码越少越好
3、异常处理的频率越低越好

