python文件操作方式
一、文件操作
1.什么是文件
文件是操作系统暴露给用户能够快捷方便操作硬盘的快捷方式(接口)
2.代码如何操作文件
关键字:open()
三步走:
1.利用关键字open打开文件
2.利用其他方法操作文件
3.关闭文件
文件路径:相对路径与绝对路径
路径中出现了字母与斜杠的组合产生了特殊含义如何取消>>在路径字符串前面加一个r
r'D:\project\try.txt'
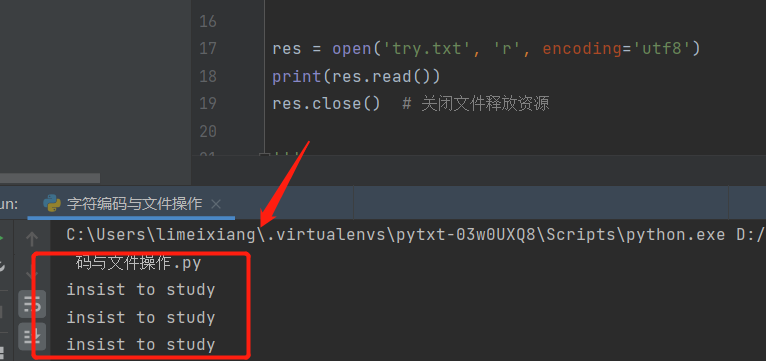
res = open('try.txt', 'r', encoding='utf8')
print(res.read())
res.close() # 关闭文件释放资源
'''
open(文件路径,读写模式,字符编码)
文件路径与读写模式是必须的
字符编码是可选的(有些模式需要编码)
'''
# with上下文管理(能够自动帮你close())
with open(r'try.txt', 'r', encoding='utf8') as f: # f=open() f.close()
print(f.read())
'''代码操作文件,一般使用with语法'''
3.文件读写模式
r, 只读模式(只能看不能改)
# 路径不存在,直接报错
with open(r'a.txt', 'r', encoding='utf8') as f1:
f1.read()
# 路径存在
with open(r'try.txt', 'r', encoding='utf8') as f2:
print(f2.read()) # 读取文件所有内容
w, 只写模式(只能写不能看)
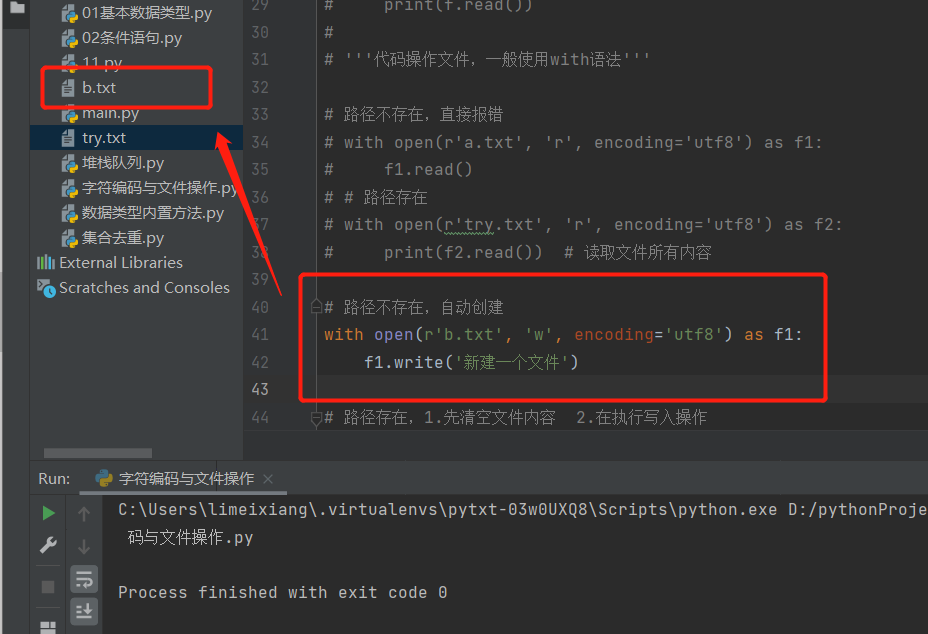
# 路径不存在,自动创建
with open(r'b.txt', 'w', encoding='utf8') as f1:
f1.write('新建一个文件')
# 路径存在,1.先清空文件内容 2.在执行写入操作
with open(r'try.txt', 'w', encoding='utf8') as f2:
f2.write('insist insist')
a, 只追加模式(追加内容)
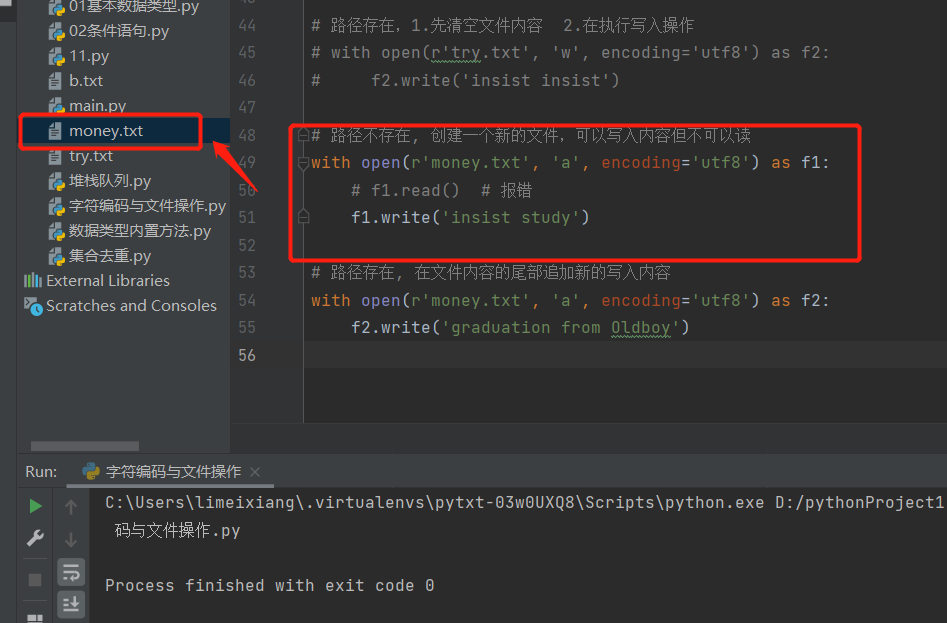
# 路径不存在, 创建一个新的文件,可以写入内容但不可以读
with open(r'money.txt', 'a', encoding='utf8') as f1:
# f1.read() # 报错
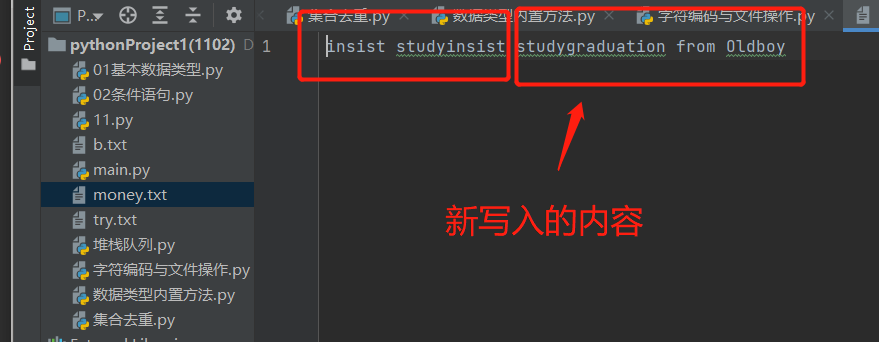
f1.write('insist study')
# 路径存在, 在文件内容的尾部追加新的写入内容
with open(r'money.txt', 'a', encoding='utf8') as f2:
f2.write('graduation from Oldboy')
目前所说的r w a读写模式还只能操作文本文件
操作视频图片等其他文件得使用下方提到的二进制模式操作
二、文件操作方法
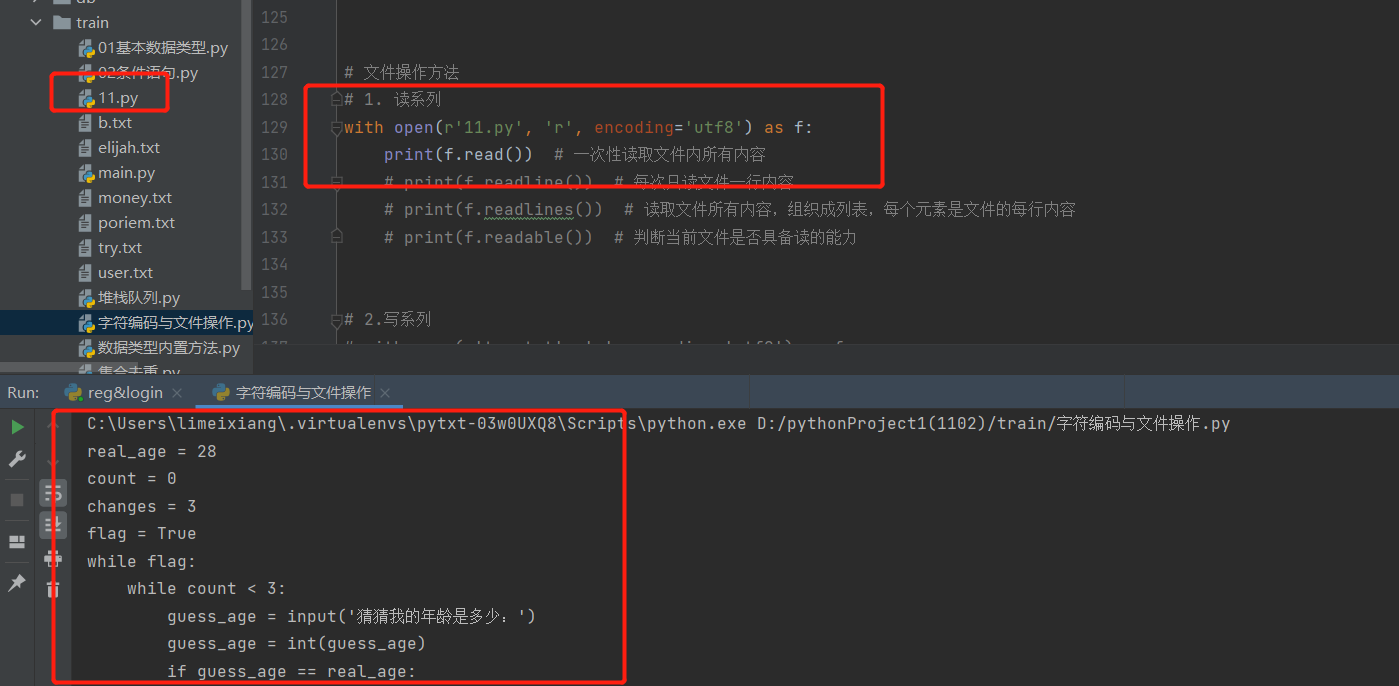
1.读系列
# 1. 读系列
with open(r'11.py', 'r', encoding='utf8') as f:
print(f.read()) # 一次性读取文件内所有内容
print(f.readline()) # 每次只读文件一行内容
print(f.readlines()) # 读取文件所有内容,组织成列表,每个元素是文件的每行内容
print(f.readable()) # 判断当前文件是否具备读的能力
2.写系列
with open(r'try.txt', 'w', encoding='utf8') as f:
f.write('insist every day') # 往文件内写入内容
f.writelines(['elijah\n', 'jason\n', 'egon\n']) # 将列表中的多个字符串元素全部写入
f.write(123) # 写入操作的时候只能写入字符串,写入数字会报错
print(f.writable()) # 判断该文件是否具备写的能力
f.flush() # 直接将内存中的数据刷到硬盘中,相当于ctrl + s
3.文件优化操作
# with open(r'11.py', 'r', encoding='utf8') as f:
# # print(f.read())
# for line in f: # 文件变量名f支持for循环 相当于一行行读取文件内容
# print(line)
'''以后涉及多行文件内容情况一般都是采用for循环读取'''
'''
1.一次性读完之后光标停留在文末尾 无法再次读取内容
2。该方法在读取大文件的时候 可能会导致内存溢出的情况
解决上述问题的策略就是逐行读取文件内容
'''
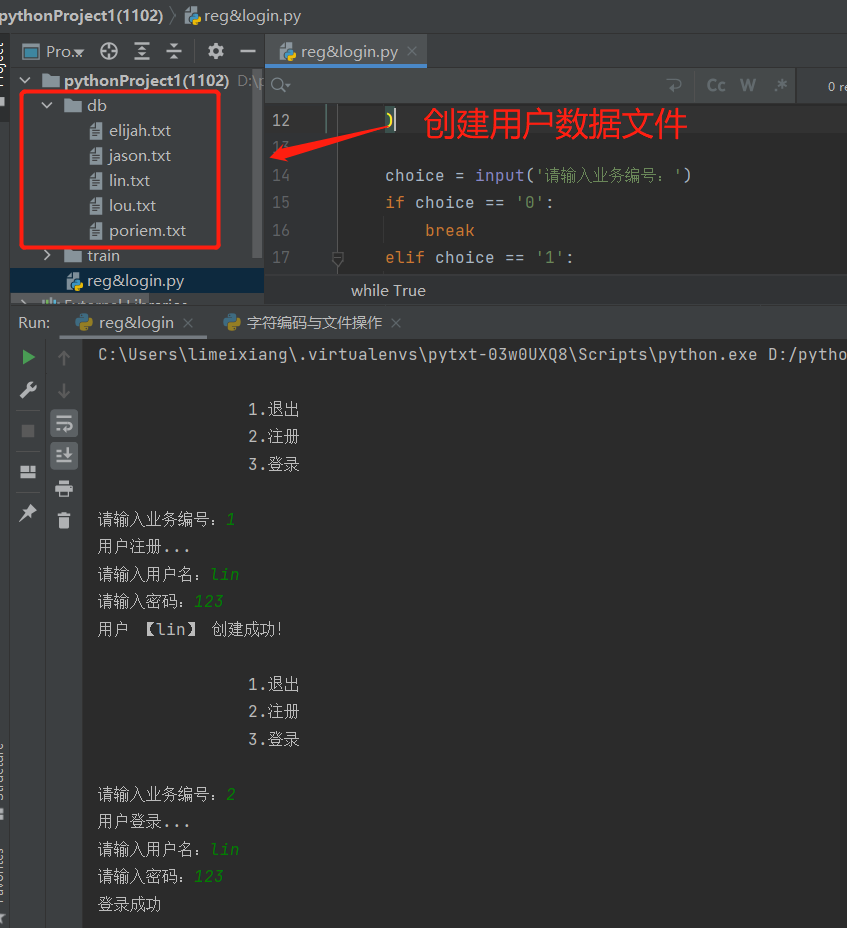
4.练习多用户注册&登录功能
import os
while True:
# 打印功能列表
print(
'''
1.退出
2.注册
3.登录
'''
)
choice = input('请输入业务编号:')
if choice == '0':
break
elif choice == '1':
# 注册功能
print('用户注册...')
# 获取用户名和密码
username = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
# 把用户数据组合成字符串
user_data = f'{username}|{password}'
# 判断用户数据文件是否已经存在,如果存在,提醒用户
if os.path.exists(rf'D:\pythonProject1(1102)\db\{username}.txt'):
print(f'用户 【{username}】 已存在,请不要重复注册')
else:
# 在数据库中文件创建相应的用户文件,存入用户信息
with open(rf'D:\pythonProject1(1102)\db\{username}.txt', 'w', encoding='utf8') as f:
f.write(user_data)
print(f'用户 【{username}】 创建成功!')
elif choice == '2':
# 登录功能
print('用户登录...')
# 获取用户名和密码
username = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
# 判断用户数据文件路径是否存在
if os.path.exists(rf'D:\pythonProject1(1102)\db\{username}.txt'):
# 如果存在,读取文件数据并作解压赋值,取出用户名和密码
with open(rf'D:\pythonProject1(1102)\db\{username}.txt', 'r', encoding='utf8') as f:
res = f.read()
name, pwd = res.split('|')
if username == name and password == pwd:
print('登录成功')
else:
print('用户名或密码错误')
else:
print('用户不存在...')
else:
print('请输入正确的编号...')
三、文件操作模式
t >> 文本模式
1.默认的模式。。r w a >>> rt、 wt、 at
2.该模式所有操作都是以字符串为基本单位(文本)
3.该模式必须要指定encoding参数
4.该模式只能操作文本文件
b >> 二进制模式
1.该模式可以操作任意类型的文件
2.该模式所有操作都是以bytes类型(二进制)为基本单位
3.该模式不需要指定encoding参数
rb、wb、ab
文件拷贝练习
while True:
# 获取要拷贝的文件路径和目标粘贴位置路径
file_path = input('请输入要拷贝的文件路径(0为退出):')
if file_path == '0':
break
copy_path = input('请输入要粘贴的目的地位置:')
# 以二进制模式打开并读取文件数据
with open(file_path, 'rb') as f:
res = f.read()
# 以二进制模式写入新的文件路径
with open(copy_path, 'wb') as f1:
for line in res:
f1.write(res)
print('拷贝成功')
# 方式2
# 1.待拷贝的文件路径
wait_copy_file = input('file path>>>:').strip()
# 2.新的文件路径
new_file_path = input('new path>>>:').strip()
# 3.以r模式打开步骤1的路径 以w模式打开步骤2的路径
with open(r'%s' % wait_copy_file, 'rb') as f1, \
open(r'%s' % new_file_path, 'wb') as f2:
for line in f1:
f2.write(line)

二进制的读写操作
# t 文本模式
#
# a.txt 文件内容
# insist
# 坚持吧坚持吧
# 顶住顶住
with open(r'a.txt', 'rb') as f:
print(f.read().decode('utf8'))
print(f.read(6).decode('utf8')) # insist
with open(r'a.txt', 'r', encoding='utf8') as f1:
# print(f1.read())
print(f1.read(8)) # insist 坚
'''
read() 括号内可以放数字
在t模式下数字表示字符个数
在b模式下数字表示字节格式
英文字符统一使用一个bytes来表示
中文字符统一使用三个bytes来表示
'''
文件内光标的移动
# 文件内光标的移动
with open(r'a.txt', 'rb') as f:
print(f.read(6)) # b'insist'
print(f.tell()) # 查看光标移动了多少个字节 6
f.seek(8, 0)
print(f.tell()) # 8
print(f.read().decode('utf8'))
'''
控制文件内光标的移动 f.seek()
f.seek(offset, whence)
offset表示位移量
始终是以字节为最小单位
正数从左到右移动
负数从左往右移动
whence表示模式
0: 以文件开头为参考系(支持tb两种模式)
1: 只支持b模式 以当前位置为参考系
2: 只支持b模式 以文件末尾为参考系
'''
文件的内容修改
# 文件内容修改
# 方式1 覆盖
with open(r'a.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'a.txt', 'w', encoding='utf8') as f1:
new_data = data.replace('insist', 'hard study')
f1.write(new_data)
# 方式2 新建
import os
with open('a.txt', 'r', encoding='utf8') as f, \
open('a.txt.swap', 'w', encoding='utf8') as f1: # 同时打开两个文件的方式
for line in f:
f1.write(line.replace('坚持', '努力')) # 替换掉原文件的字符
os.remove('a.txt')
os.rename('a.txt.swap', 'a.txt')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人