
浅谈--技术架构的演进(微服务,负载均衡,异步,消息队列,数据存储,高并发处理,缓存机制)
想象一下,你家楼上有个业主在装修,施工不当,导致你家里有个卧室漏水了,这个时候你怎么办?
在程序中的体现:
单体应用:
项目所有的模块都打包到一起,然后扔到服务器上部署运行。假如这个项目是一个电商项目,里面有下单模块,派送模块等等。你把这些模块想象成你家的房间,一个模块对应一个房间,现在派送模块对应的房间漏水了,这个时候怎么办?没办法,只能全家出去住了,为啥,因为你所有的模块都打包到一个项目里面去了,一个模块挂了,整个项目都得停下来,等派送模块修好了,再启动项目继续运行。缺点一目了然。
微服务应用:
为了解决单体式应用的不足,微服务的概念横空出世。核心就是“拆”,把一整个项目按模块拆成一个个的小项目,所有拆分的小项目之间进行合作通信形成原先的整体项目。这样有什么好处,当我们的项目在运行的时候,同样派送模块挂了,这时候挂了的只有这一个模块服务,你其它模块的服务还是能后正常运行,用户还是能够正常下单,老板还是正常赚钱。维修人员只需要把派送模块修好之后重新运行起来,然后加进来继续给用户下的单送货。当然,最重要的就是,你不用全家出去睡了!
2、三个臭皮匠顶个诸葛亮——系统应用的高并发怎么处理
在学校的时候,自己的毕业课设是《网上求职招聘管理系统》,做完了之后,和同学室友测了请求响应都很迅速,没啥毛病。但是,当在面试的时候,面试官问我这个系统的并发量、性能问题的时候,我只能说额,今天天气真不错。
实际在公司做项目的时候,不仅仅是系统能够正常跑起来这么简单而已,更重要的是系统能够承受住的用户并发请求。当用户数量庞大时,我们就需要更好的机器、更好的CPU、更大的内存、更好的网络环境去应对请求的高并发。
为了应对这种高并发的情况,两种处理方式:
垂直扩展
那就是在一台服务器的基础上,不断升级其中的配件,加入更多的磁盘、升级更大的内存、买更好更快的CPU......更加强大的服务器当然能够处理更高的并发量。总结一句话,充钱使你更加强大。
但是,这样也是有弊端的,首先就是老板与客户不一定愿意花钱(有钱当我没说),更重要的一点还是,就算你给这台服务器 所有的配件都升级成最好的。但是,单台服务器处理性能还是有瓶颈的。那怎么办呢?俗话说得好,三个臭皮匠能顶一个诸葛亮。于是水平扩展出现了。
水平扩展
既然一台服务器有瓶颈,那就多换几个机器来处理用户请求,把单体应用转变成分布式集群应用。不仅省钱,处理并发 的能力也好。
3、缓存架构提高系统的读能力
讲个简单的场景:前台用户访问系统应用的数据,后台是通过查询数据库的数据返回给前端展示的,在低访问量的情况下,这简单的流程,系统还是能够妥妥处理的。但是,你想想,在淘宝双11的活动下,成千上万的用户同时访问淘宝,购买商品,同一个时间点,几百万几千万的用户请求往后台的数据库打,能直接把后台数据库给打崩。
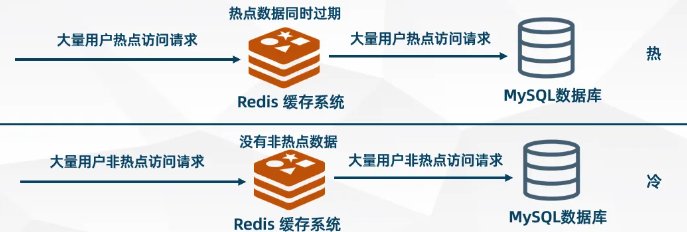
为了防止这种情况的发生,缓存出现了。在原来的逻辑中间加一层缓存,前台用户请求来的时候,不用每次都去数据库里操作数据,而是将应用程序需要的数据暂存在缓存之中,请求来了,先查缓存,缓存中有的话就不用去数据库里查。这样就能够大大减少数据库直接被用户打崩的情况,而且缓存是在内存中的,用户请求不用去I/O磁盘,而是直接读取内存数据,快得很。
4、异步架构提高系统的写能力
缓存架构的出现,大大提高了程序的读能力,那么系统写的能力有没有什么方法提高呢?这时候,异步架构的概念就出现了,也就是消息队列的应用。
同步概念
快递员在送快递的时候,往往都会要求买家在收到快递的时候签个名字,有的时候,买家不在家还需要站在门口等买家回来,浪费自己送快递的时间。
在程序中的体现:A系统向另一个B系统发了一个消息,此时,A系统要收到B系统的回信才能进行其他的操作,否则这个进程就一直卡在这里。问题来了,要是B系统能够立即回复还好,要是因为网络等原因一直在延迟,那么A系统的CPU资源就一直在那里等着,也就是说那些CPU资源就是被浪费了。
异步概念
快递员在送快递的时候,不需要用户直接签名签收,我直接给你放快递柜里就行了,你人回家直接去快递柜里扫码取件就行了。
在程序中的体现:你在微信给你的好朋友发一条消息,发完之后你就可以不用管了,手机想玩啥就玩啥,不用等到对方回了你的消息你才能够使用手机玩别的。
流程示意图:
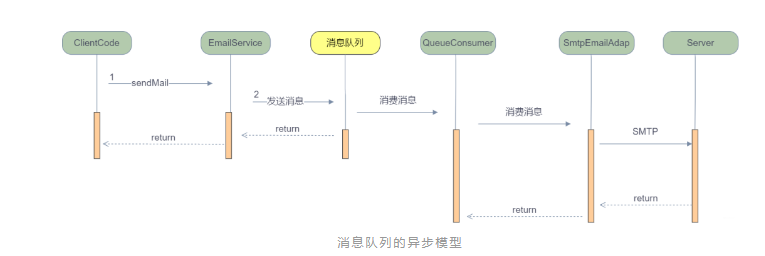
你只需要将消息发给中间新加入的消息队列组件,消息队列在收到你发的消息之后就给你立即返回,至于这条消息发给另一个用户的操作消息队列自己会处理就不用你关心了。
这样做的好处:
-
给你快速的响应,避免白白等待,浪费系统资源。
-
流量削峰,在淘宝双11活动下,加入这个消息队列,成千上万的用户请求过来,系统一时间处理不过来,就可以把用户的请求放到这个消息队列里面,让系统进行排队处理。
-
降低系统的耦合度,在调用者系统和被调用者系统之间加入消息队列,这样两者之间的代码依赖就少了,交互的部分交给中间的消息队列处理就好了。
5、解决机器不干活——负载均衡的出现
前面说到,使用多台机器代替一台机器用来处理前台用户的请求。那么问题来了,前台过来的应用,发到后台来,后台三个服务器大眼瞪小眼,谁来干活呢?这时候负载均衡就出现了。
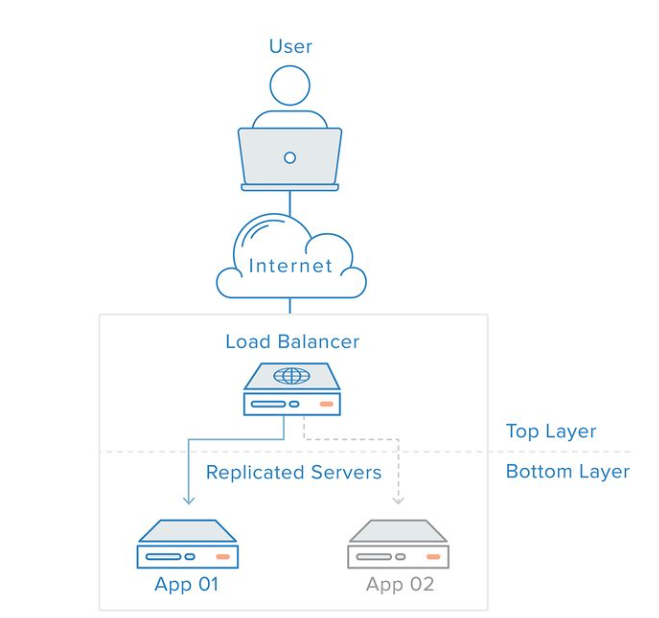
请求来到后台的时候,先要经过负载均衡处理器的一道处理,这里可以想象这个负载均衡器是一个包工头,项目来的时候,把项目分给自己手下管理的小弟来做。
当然,这个负载均衡里会涉及到很多不同的算法,轮询、随机、最多、最少......等。简单来讲就是,轮询算法包工头会把上面派下来的任务平均分到每一个小弟的手上,当然,包工头也可以根据心情,故意让你多做或者故意让你少干,这就是里面你选择的负载均衡算法。
6、狡兔三窟——数据存储
前面说到,大量的用户请求都需要访问数据库。你想过没有,如果系统只有一个数据库,当这个数据库因为停电啥的故障坏了怎么办,那么整个系统就都凉凉了。为了解决这个问题,那就是给数据做好备份,多台数据库服务器提供用户服务。当一台数据库服务器挂了的时候,其它的还可以顶上去,继续给用户提供服务。

用专业的话来讲就是,主从复制,整个服务器有一台主服务器多台从服务器,从服务器定时同步主服务器的数据,这样,当主服务器挂了的时候,从服务器顶上,系统照样能够正常运行。
这种技术手段在大部分数据库里都有使用,如mysql、redis,
7、看起来不太聪明的样子——搜索引擎
相信对于程序员来讲,面向百度谷歌编程这句话大家都比较熟悉。但是,当程序出现bug的时候,打开百度的搜索栏,想了半天不知道怎么搜索问题。为了能够快速找到问题的解决方案,当然是输入的关键词越接近问题,显示出来的答案更加准确。
想百度谷歌这种大型的搜索网站都有属于自己的一套搜索引擎,根据这些搜索引擎里面的算法,可以根据我们提供的搜索关键字,排序显示给我们问题的答案。
现在比较热门搜索引擎有es、solr。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?