
中文词频统计及词云制作
1.中软国际华南区技术总监曾老师还会来上两次课,同学们希望曾老师讲些什么内容?(认真想一想回答)
大数据具体的生活应用(具体到某个领域,以及其中起到的作用)
2.中文分词
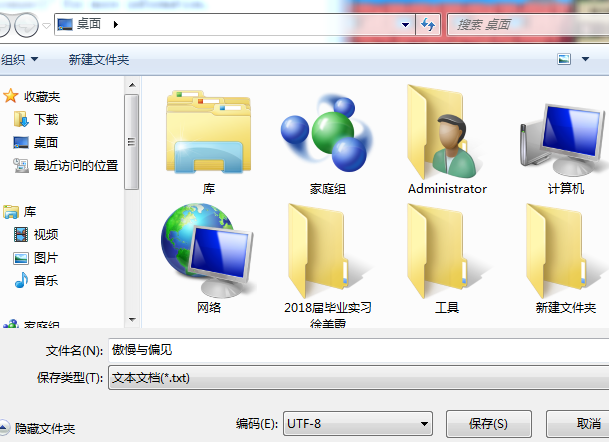
- 下载一中文长篇小说,并转换成UTF-8编码。
- 使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
- **排除一些无意义词、合并同一词。
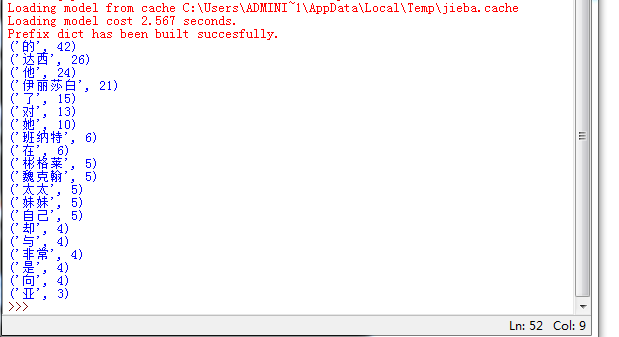
import jieba
fr=open("傲慢与偏见.txt",'r',encoding='utf-8')
s=list(jieba.cut(fr.read()))
exp={',','\n','.','。','”','“',':','…',' ','?'}
key=set(s)-exp
dic={}
for i in key:
dic[i]=s.count(i)
wc=list(dic.items())
wc.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
print(wc[i])
fr.close()
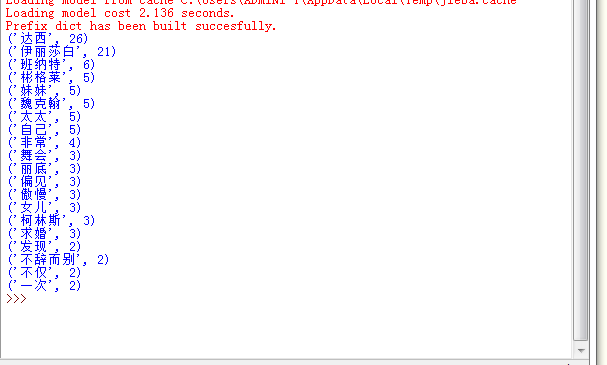
import jieba
fr=open("傲慢与偏见.txt",'r',encoding='utf-8')
s=list(jieba.cut(fr.read()))
key=set(s)
dic={}
for i in key:
if len(i)>1:
dic[i]=s.count(i)
wc=list(dic.items())
wc.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
print(wc[i])
fr.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号