使用CNN处理彩色图像
目的: 要求使用CNN来处理识别不同大小的彩色图像。
1. 分析问题
使用卷积神经网络处理彩色图像会遇到两个挑战:
1. 照片大小不同
2. 颜色是彩色的
对于第一个问题,将所有处理照片都调整成相同大小 。
对于第二个问题:将照片分成3维数据, 长,宽,深度
其中长与宽表示照片大小 , 深度表示RGP颜色。
执行卷积过程

图1-1 执行卷积过程 |
彩色图像通过RGB表示颜色, 所有深度为3, 每个通道颜色都有自己的核过滤器,将所有值都相加再加上bias值。
MaxPooling 过程
过程同样, 将执行卷积的三维的卷积结果使用RGB分别进行运算
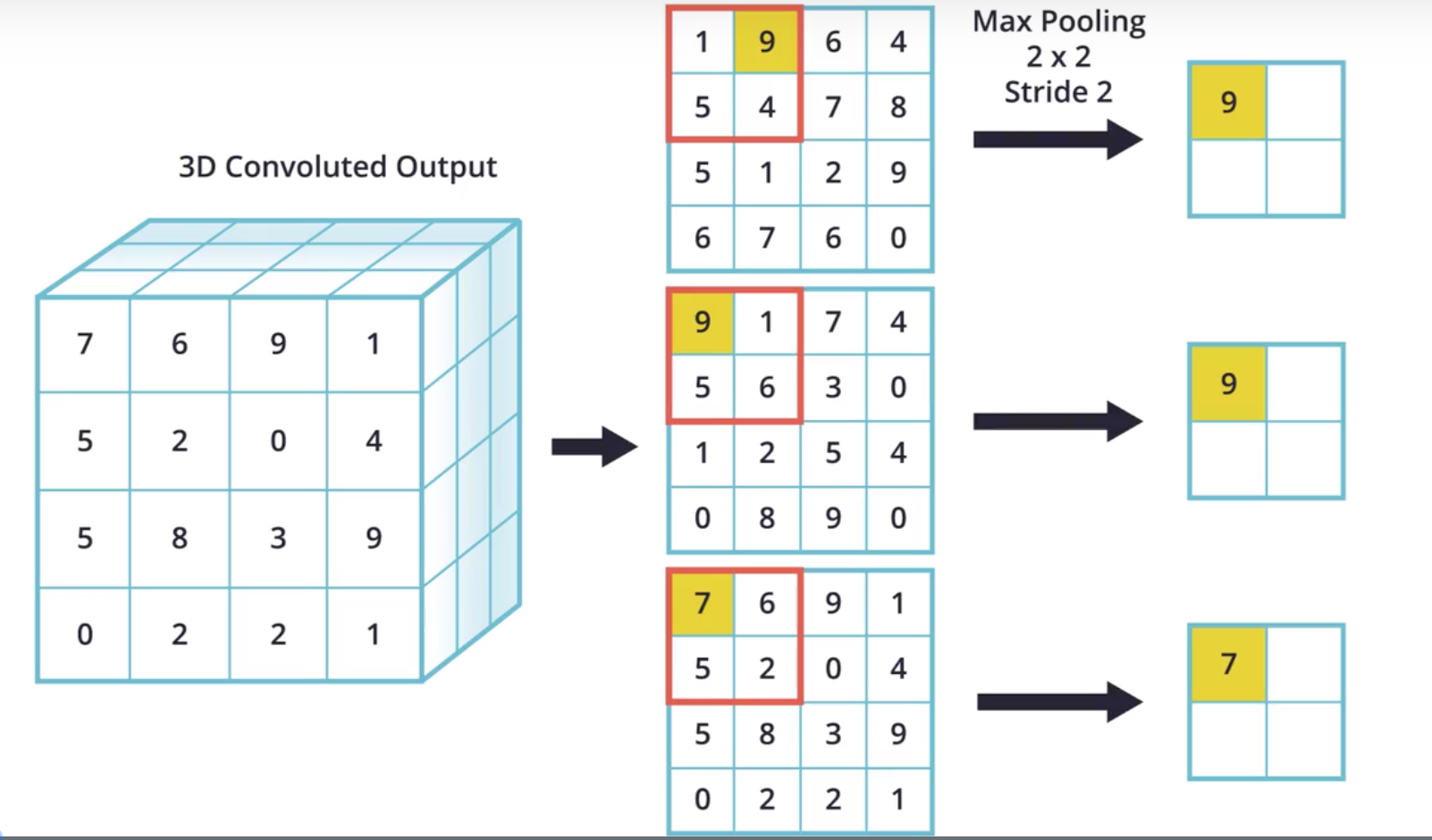
图1-2 执行MaxPooling过程 |
2. Coading
第一步:导入包头
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator # Import TensorFlow Datasets import tensorflow_datasets as tfds tfds.disable_progress_bar() # Helper libraries import numpy as np import matplotlib.pyplot as plt import os import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
注释: 理解

理解 ImageDataGenerator 函数接口 |
ImageDataGenerator 函数可以帮助你自动的标注该图片的类型
第二步:载入并下载数据
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True) zip_dir_base = os.path.dirname(zip_dir) base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') # directory with our training cat pictures train_dogs_dir = os.path.join(train_dir, 'dogs') # directory with our training dog pictures validation_cats_dir = os.path.join(validation_dir, 'cats') # directory with our validation cat pictures validation_dogs_dir = os.path.join(validation_dir, 'dogs') # directory with our validation dog pictures num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val print('total training cat images:', num_cats_tr) print('total training dog images:', num_dogs_tr) print('total validation cat images:', num_cats_val) print('total validation dog images:', num_dogs_val) print("--") print("Total training images:", total_train) print("Total validation images:", total_val)
输出结果
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
68608000/68606236 [==============================] - 20s 0us/step
total training cat images: 1000
total training dog images: 1000
total validation cat images: 500
total validation dog images: 500
--
Total training images: 2000
Total validation images: 1000
第三步: 设置参数
BATCH_SIZE = 100 # Number of training examples to process before updating our models variables IMG_SHAPE = 150 # Our training data consists of images with width of 150 pixels and height of 150 pixels
第四步:准备数据
包括以下步骤
* 从硬盘上读取数据
* 将这些照片信息转换成RGB格式的信息
* 转换成floating 张量格式
* 将RGB值[0,255] 转换成[0,1]
train_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our training data validation_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our validation data
flow_from_directory 方法将会从硬盘上面读取数据
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), #(150,150) class_mode='binary')
第五步: 查看数据
sample_training_images, _ = next(train_data_gen) # This function will plot images in the form of a grid with 1 row and 5 columns where images are placed in each column. def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show() plotImages(sample_training_images[:5]) # Plot images 0-4
对于过拟合问题的解法
* 图像增强
* 丢弃
第六步: 定义模型
模型由4个卷积块组成,每个卷积都有max pool 层。
然后使用512个单元格的神经组成密集层,激活函数使用relu
输出使用2个概率, 总和值为1
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
在处理二元分类问题时,另一个常见做法是
分类器由一个 Dense 层(具有 1 个输出单元)和一个 sigmoid 激活函数组成
tf.keras.layers.Dense(1, activation='sigmoid')
并且将loss 函数修改成“binary_crossentropy”
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
第七步:编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
第八步: 查看模型汇总信息
model.summary()
打印信息如下
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0 _________________________________________________________________
第九步:训练模型
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
运行结果
Epoch 96/100
20/20 [==============================] - 95s 5s/step - loss: 1.4625e-05 - accuracy: 1.0000 - val_loss: 1.9852 - val_accuracy: 0.7500
Epoch 97/100
20/20 [==============================] - 95s 5s/step - loss: 1.4207e-05 - accuracy: 1.0000 - val_loss: 1.9879 - val_accuracy: 0.7500
Epoch 98/100
20/20 [==============================] - 96s 5s/step - loss: 1.3850e-05 - accuracy: 1.0000 - val_loss: 1.9903 - val_accuracy: 0.7510
Epoch 99/100
20/20 [==============================] - 95s 5s/step - loss: 1.3508e-05 - accuracy: 1.0000 - val_loss: 1.9930 - val_accuracy: 0.7490
Epoch 100/100
20/20 [==============================] - 96s 5s/step - loss: 1.3158e-05 - accuracy: 1.0000 - val_loss: 1.9955 - val_accuracy: 0.7500
关于过拟合问题
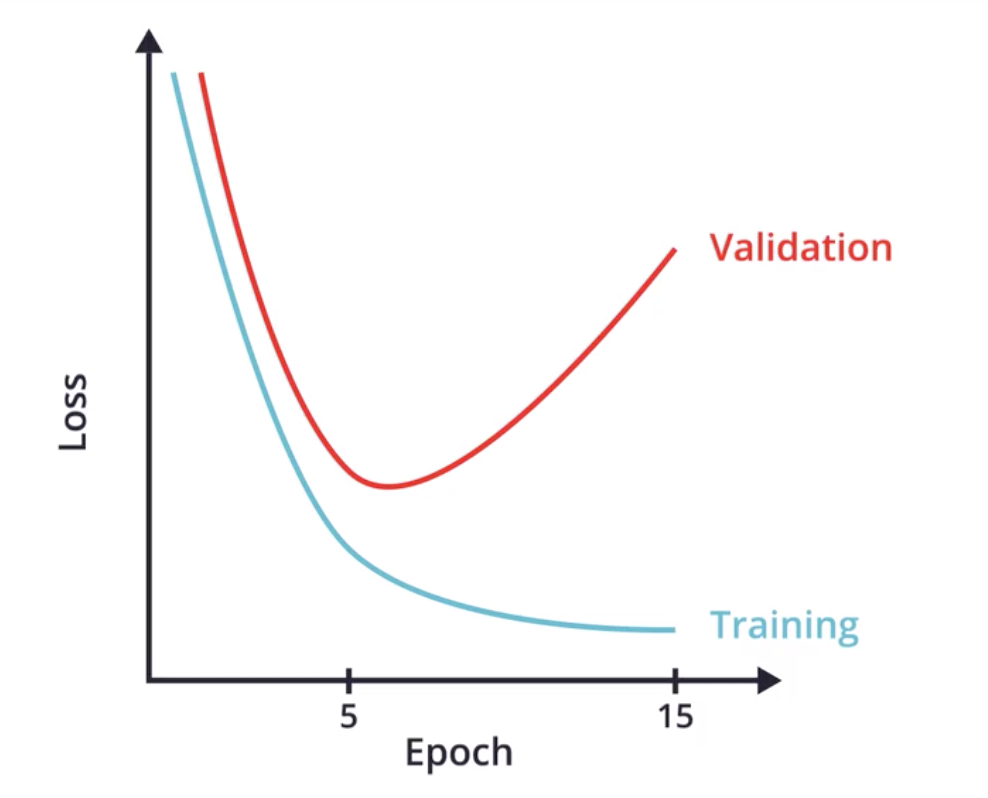
|
第十步:可视化模型
acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.savefig('./foo.png') plt.show()
运行结果
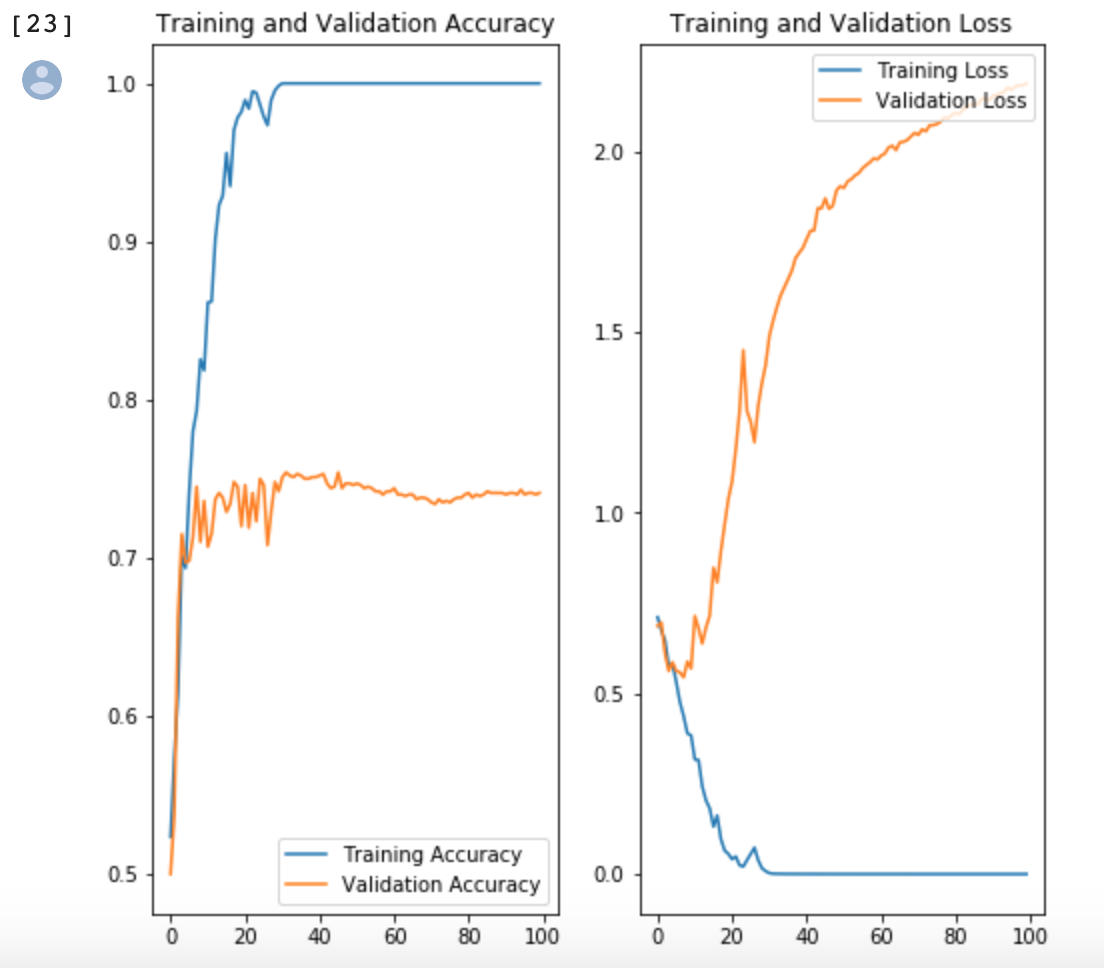
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号