SDUST 2020/数据结构/期末集合.part1
以下内容仅代表个人的想法,整理自用,如有错误欢迎指正批评
1 绪论 && 数据结构基本概念
数据结构的研究内容为:非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作
01基本概念
1. 数据(data):所有能输入到计算机中去的描述客观事物的符号。
➢数值性数据
➢非数值性数据(多媒体信息处理)
2. 数据元素(data element) 数据的基本单位,也称结点(node)或记录(record),具有完整的意义 。
3. 数据项(dataitem) 有独立含义的、不可分割的数据最小单位,也称域(field)。
以上三者之间的关系:数据>数据元素>数据项。例如:学生表>个人记录>学号、姓名....
4. 数据对象:相同特性的数据元素的集合,是数据的一个子集
5. 数据结构 : 相互之间存在一种或多种特定关系的数据元素的集合
02数据结构的两个层次
1.逻辑结构:数据元素间抽象化的相互关系,与数据的存储无关,独立于计算机,它是从具体问题抽象出来的数学模型。
划分方法有两种
①:
- 线性结构——有且仅有一个开始和一个终端结点,并且所有结点都最多只有一个直接前趋和一个后继。
- 非线性结构——一个结点可能有多个直接前趋和直接后继。
常用的线性结构有:线性表,栈,队列,双队列,数组,串。
常见的非线性结构有:二维数组,多维数组,广义表,树(二叉树等),图,堆。
②:
集合、线性结构、树形结构、图形结构
注:数据的逻辑结构 与数据元素本身的形式、内容、相对位置、个数均无关
2.存储结构(物理结构) --数据元素及其关系在计算机存储器中的存储方式。
顺序存储结构:借助元素在存储器中的相对位置来表示数据元素间的逻辑关系
链式存储结构:借助指示元素存储地址的指针表示数据元素间的逻辑关系
3.所谓逻辑结构是指反映数据元素之间的逻辑关系的数据结构,其中逻辑关系指的是数据元素前后件的关系,而他们之间的关系与他们在计算机当中的存储位置无关,实际上可以认为逻辑结构是人们为了解决问题而抽象出来的模型。知道逻辑结构是一种模型,而存储结构是实际在计算机中的存储时的结构。
03算法和算法分析
1.定义:一个又穷的指令集,为解决某一特定任务规定了一个运算序列
特性:有穷性、确定性、可行性、有输入有输出
算法的评价从四个维度来确认:正确性、可读性、健壮性(对不正确的情况作出适当的反应和处理)、高效性
2.算法效率的度量
¤ 事后统计:利用计算机内的计时功能,不同算法的程序可以用一组或多组相同的统计数据区分
缺点: ①必须先运行依据算法编制的程序
②所得时间统计量依赖于硬件、软件等环境因素掩盖算法本身的优劣
¤ 事前分析估算法
一个高级语言在计算机上运行所消耗的时间取决于:依据的算法选用何种策略 || 问题的规模 || 程序语言 || 编译程序产生及其代码质量 || 机器执行指令的速度
¤ 时间复杂度
04 时间复杂度
一般情况,算法中基本操作重复的次数是关于 问题规模n 的某个函数f(n)(频度)
算法的时间量度记作T(n)=O(f(n)),即为时间复杂度。
简单来讲,计算时间复杂度,就是根据代码,将重复次数用一个含有 问题规模n 的代数式表示出来。
①O(1)类型
如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。
eg.
x=0; for(i=0;i<1000;i++) x+=i;
②O(n^a)类型
eg1.
for(i=0;i<n;i++)
for(j=0;j<n;j++)
x+=1;
结果是 Σ(i=0—n)Σ(j=0—n)*1=n*n
eg2
if ( A > B )
{ for ( i=0; i<N*N/100; i++ )
for ( j=N*N; j>i; j-- )
A += B; }
else
{ for ( i=0; i<N*2; i++ )
for ( j=N*3; j>i; j-- )
A += B; }
选取需要时间最长的那个循环,显然是if里面的 n^5
eg3.
int func ( int n )
{ int i = 0, sum = 0;
while ( sum < n )
sum += ++i;
return i; }
③O(log an)类型
eg.
for (int i = 1; i <= n; i *= c)
a = a + 1;
设频度f(n),则有 c^f(n)*1<=n,取等号时计算,得 f(n)=O(log cn)
同理,i执行 i/=c 的时候也是成立的:
for (int i = n; i > 0; i /= c) { a = a + 1;}
设频度f(n),则有(1/c)^f(n)*n>0,因为i是int型,取(1/c)^f(n)*n=1时计算,得 f(n)=O(log cn)
④其它类型
eg.
for(i=0; i<n; i++)
for(j=i; j>0; j/=2)
printf(“%d\n”, j);
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)
05选择
1、 数据在计算机内存中的表示是指(A) 。
A.数据的存储结构
B.数据结构
C.数据的逻辑结构
D.数据元素之间的关系
2、 树形结构中元素之间存在()关系。 一对多
3、 算法的时间复杂度取决于( )。D
A.问题的规模 B.待处理数据的初态
C.计算机的配置 D.A和B
4、以下说法正确的是( )。D
A.数据元素是数据的最小单位
B.数据项是数据的基本单位
C.数据结构是带有结构的各数据项的集合
D.一些表面上很不相同的数据可以有相同的逻辑结构
5、数据的基本单位是()。数据元素
6、下面代码段的时间复杂度是() n^0.5
x=n; //n>1 y=0; while( x≥(y+1)*(y+1) ) y++;
7、下面代码段的时间复杂度是() nlogn
for(i=0; i<n; i++) for(j=i; j>0; j/=2) printf(“%d\n”, j);
8、下面代码段的时间复杂度是() n^4
if ( A > B ) { for ( i=0; i<N*N/100; i++ ) for ( j=N*N; j>i; j-- ) A += B; } else { for ( i=0; i<N*2; i++ ) for ( j=N*3; j>i; j-- ) A += B; }
2 线性表
线性表是一种简单的线性结构,它的基本特征为:在数据元素的非空有限中:
集合中必存在唯一的“第一元素”和“最后元素”
除最后元素外,都有唯一后继;除第一元素外,都有唯一前驱
01 顺序表
如果我们知道想要访问的是顺序表中的第几个元素,我们就可以通过基地址加上偏移量来直接访问我们想要访问的数据元素,因此我们说顺序表是随机存储。
在顺序表当中存在两个域,一个是指针域用来指向基地址,另一个就是表示顺序表当前长度的域是一个整型的变量。
题目:
1、若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用顺序表存储最节省时间。T
5、在N个结点的顺序表中,算法的时间复杂度为O(1)的操作是:A
10、线性表L=(a1, a2 ,……,an )用一维数组表示,假定删除线性表中任一元素的概率相同(都为1/n),则删除一个元素平均需要移动元素的个数是()。 (n-1)/2
100+2(5-1)=108
12、将两个结点数都为N且都从小到大有序的单向链表合并成一个从小到大有序的单向链表,那么可能的最少比较次数是:N
最少次情况举例:1234 5678 只需要把5和1234比较一遍即可
02 单链表
用一组地址任意的存储单元存放线性表中的数据元素,有 元素(数据元素的映像)+指针(指示后继元素存储位置)=结点, 以"结点的序列"表示线性表,称为链表。
以线性表中第一个数据元素a1的存储地址作为线性表的地址,称作线性表的头指针;
有时为了操作方便,在第一个结点之前虚加一个"头节点",以指向头结点的指针为头指针。
定义:
typedef int ElemType; struct LNode { ElemType data; LNode *next; }; typedef LNode *LinkList;
- ElemType为对应的数据域的数据类型,不仅仅是基本的数据类型,也可以复杂的数据类型。
- next即为指向直接后继存储位置的指针
- LNode *类型我们用来指向单个节点
LinkList L;
这样就声明了一个链表L,L指向头结点(这里讨论带头结点的单链表),实际上不管是带头结点还是不带头结点,L永远都指向链表的第一个元素。
单链表初始化:
bool InitList(LinkList &L) { L = new LNode(); if(L != NULL) return true; else return false; }
申请成功也就是L不指向空返回true,反之申请不成功L指向空返回false。
单链表中按位置查找元素:
ElemType GetElem(LinkList L, int pos) { int j = 1; L = L->next; //有头结点 while(L && j < pos) //顺指针查找,直到L指向第pos个元素 { L = L->next; j++; } if(!L || j > pos) //不存在第pos个元素 return -1; //错误返回值视情况而定 return L->data; //返回被查元素 }
单链表中按数值查找元素:
int LinkFind(LinkList L, ElemType e) { int j = 1; L = L->next; while(L && L->data != e) { L = L->next; j++; } if(!L) return -1; return j; //返回的是该数的位置 }
单链表元素插入:
bool ListInsert(LinkList &L, int pos, ElemType e) //在第pos的位置插入元素e { int j = 0; while(L && j < pos - 1) { L = L->next; j++; } if(!L || j > pos - 1) return false; LNode *s = new LNode(e);
//s=(LinkList)malloc(sizeof(LNode)) s->next = L->next; L->next = s; return true; }
单链表元素删除:
bool ListDelete(LinkList &L, int pos) { int j = 0; while(L && j < pos - 1) { L = L->next; j++; } if(!L || j > pos) return false; LNode *p = L->next; L->next = L->next->next; delete p; return true; }
bool Ldelete (LinkLinst &L,int pos,int &e) { int j=0; LNode *p=L; while(p->next&&j<pos-1) { p=p->next; j++; } if(!(p->next)||j>i-1) return false; LNode *q; q=p->next; e=q->data; p->next=q->next; free(q); return true; }
- 如果删除失败成功true,否则返回false。
- 要删除第i个结点我们首先要获取第i个结点的直接前驱,也就是第i-1一个结点。
- 将ai-1的next指针指向ai的下一个结点(L->next = L->next->next)即跨过了ai,相当于删除。同时必须要清空ai所占的内存,于是用结点指针p指向ai方便删除。
题目:
1、设h为不带头结点的单向链表。在h的头上插入一个新结点t的语句是:
t->next=h; h=t;
2、在单链表中,若p所指的结点不是最后结点,在p之后插入s所指结点,则执行
s->next=p->next; p->next=s;
3、带头结点的单链表h为空的判定条件是:
h->next == NULL;
4、(neuDS)在单链表中,增加一个头结点的最终目的是为了
5、以下关于链式存储结构的叙述中,(C)是不正确的。
A.结点除自身信息外还包括指针域,因此存储密度小于顺序存储结构
B.逻辑上相邻的结点物理上不必邻接
C.可以通过计算直接确定第i个结点的存储地址
D.插入、删除运算操作方便,不必移动结点
6、不带表头附加结点的单链表为空的判断条件是头指针head满足条件
head==NULL
7、对于一非空的循环单链表,h和p分别指向链表的头、尾结点,则有:
p->next == h
8、在双向循环链表结点p之后插入s的语句是:
s->prior=p; s->next=p->next; p->next->prior=s; p->next=s;
p所指的结点,相应语句为:C.可以通过计算直接确定第i个结点的存储地址 D.插入、删除运算操作方便,不必移动结点
12、某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用什么存储方式最节省运算时间?
A.只有表尾指针没有表头指针的循环单链表 B.只有表尾指针没有表头指针的非循环双链表
17、如果对线性表的运算只有2种,即删除第一个元素,在最后一个元素的后面插入新元素,则最好使用()。B
A.只有表头指针没有表尾指针的循环单链表 B.只有表尾指针没有表头指针的循环单链表
C.非循环双链表 D.循环双链表
18、与单链表相比,双链表的优点之一是()
A.插入、删除操作更加简单 B.可随机访问
C.可以省略表头指针或表尾指针 D.顺序访问相邻结点更加灵活
03 对比
顺序表的优点是查找方便,根据下标迅速定位,因此时间复杂度是1;但是插删的时候需要移动元素,因此时间复杂度是N
链表的优点是插删方便,直接通过指针指向地址,不需移动其他元素
在表的最后一个结点之后插入一个新结点或删除最后一个结点,最节省运算的方式是 带有尾指针的单循环 或 带有表头的双循环
04 程序
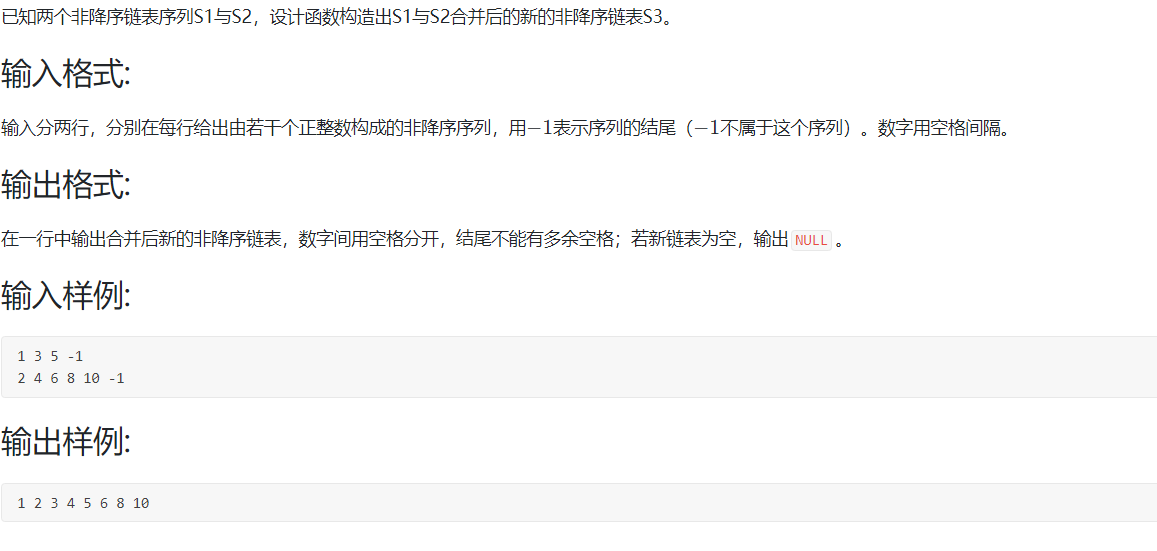
#include<bits/stdc++.h> using namespace std; typedef struct LNode //链表 { int data; struct LNode *next; } LNode,*List; void CreatList(List &s) //创建链表(输入数值) { LNode *p,*q; s=(LNode*)malloc(sizeof(LNode)); q=s; int x; while(scanf("%d",&x)!=EOF) { if(x==-1) { return ; } p=(LNode*)malloc(sizeof(LNode)); p->next=NULL; p->data=x; q->next=p; q=p; } } List Plus(List s1,List s2) //合成:返回一个新链表 { List S; S=(LNode*)malloc(sizeof(LNode)); S->next=NULL; LNode *z=S; s1=s1->next; s2=s2->next; while(s1!=NULL&&s2!=NULL) { if(s1->data<=s2->data) //合成新链表:取小数输入 { z->next=s1; z=s1; s1=s1->next; } else { z->next=s2; z=s2; s2=s2->next; } } if(s1 != NULL) z->next = s1; if(s2 != NULL) z->next = s2; return S; } void PrintfList(List s) //输出链表 { if(s->next==NULL) { printf("NULL"); return ; } s=s->next; while(s!=NULL) { if(s->next==NULL) { printf("%d",s->data); } else { printf("%d ",s->data); } s=s->next; } } int main() { List s1,s2,S; CreatList(s1); CreatList(s2); S=Plus(s1,s2); PrintfList(S); }
05 主要函数总结
typedef struct LNode//定义 { int data; LNode *next; } LNode,*LinkList; void CreatList(LinkList &L)//正序输入创建 { L=(LinkList)malloc(sizeof(LNode)); LNode *p=L; LNode *num; int x; while(scanf("&d",&x)!=EOF) { if(x==-1) return ; num=(LinkList)malloc(sizeof(LNode)); num->next=NULL; num->data=x; p-next=num; num=p; } } void CoutList(LinkList L)//输出链表元素 { if(L->next==NULL) { printf("NULL"); return ; } L=L->next; while(L!=NULL) { if(L->next!=NULL) printf("%d ",L->data); else printf("%d",L->data); } } bool Ldelete(LinkList &L,int pos,int &e)//删除位置为pos的值 { int j=0; while(L&&j<pos-1) { j++; L=L->next; } if(!L||j>pos-1) return false; LNode *p; p->next=L->next; L->next=p->next; e=p->data; free(p); return true; } int GetElem(LinkList L,int pos,int &e)//获取位置为pos的值 { int j=0; while(L&&j<pos-1) { j++; L=L->next; } if(!L||j>pos-1) return -1; LNode *p; p->next=L->next; L->next=p->next; e=p->data; return e; } int GetPos(LinkList L,int &pos,int e)//获取第一个值为e的位置 { int j=1;//算位置:从1开始 while(L&&L->data!=e) { j++; L=L->next; } if(!L||j>pos-1) return -1; return j; } List MergeList(LinkList L1,LinkList L2)//取交集 { List L; L=(LinkList)malloc(sizeof(LNode)); L->next=NULL; LNode *p=L; L1=L1->next; L2=L2->next; while(L1!=NULL&&L2!=NULL) { if(L1.data<L2.data) L1=L1.next; else if(L1.data>L2.data) L2=L2.data; else { p->next=L1; p=L1; L1=L1->next; L2=L2->next; } } return L; } List Plus(List s1,List s2) //取并集 { List S; S=(LNode*)malloc(sizeof(LNode)); S->next=NULL; LNode *z=S; s1=s1->next; s2=s2->next; while(s1!=NULL&&s2!=NULL) { if(s1->data<=s2->data) //合成新链表:取小数输入 { z->next=s1; z=s1; s1=s1->next; } else { z->next=s2; z=s2; s2=s2->next; } } if(s1 != NULL) z->next = s1; if(s2 != NULL) z->next = s2; return S; }
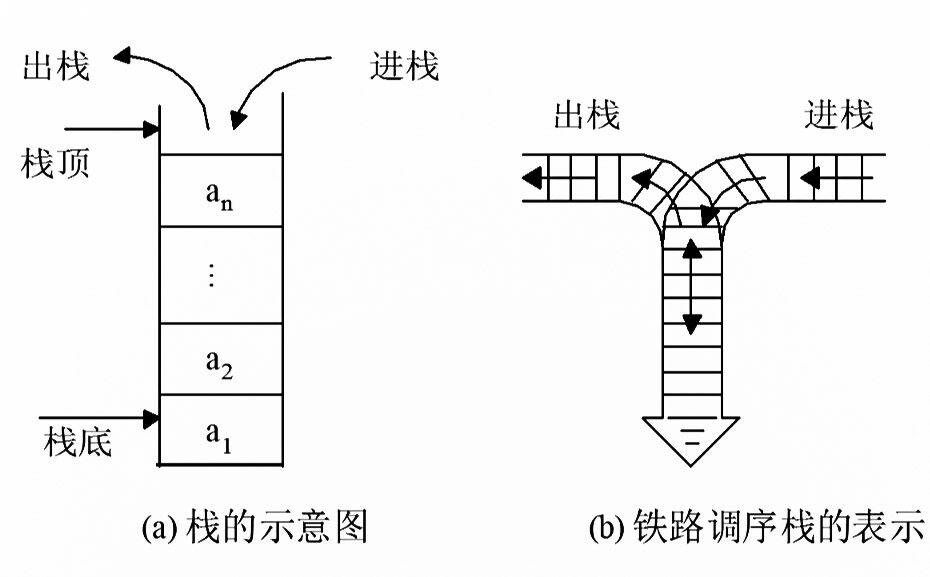
3 栈
栈作为一种限定性线性表,是将线性表的插入和删除运算限制在表的一端进行。栈是一种后进先出的线性表。
通常将表中允许进行插入、删除操作的一端成为栈顶(Top),因此栈顶的当前位置是动态变化的,由一个栈顶指针的位置指示器指示;
表的另一端为固定的一端,成为栈底(Bottom)。
01选择:
1、给定一个堆栈的入栈序列为{ 1, 2, ⋯, n },出栈序列为{ p1, p2, ⋯, pn }。如果p2=n,则存在多少种不同的出栈序列?
n-1
这里的入栈指可以间断穿插出栈
p2=n,即第二个出栈的数据元素是n,那么第一个出栈的数据元素则可以是{1,2,⋯,n-1}中的任何一个,所以存在的不同的出栈序列一种有n-1种。
2、设一个堆栈的入栈顺序是1、2、3、4、5。若第一个出栈的元素是4,则最后一个出栈的元素必定是:
1或者5
注意考虑周全
3、栈顶指针为ST的链栈中删除一个结点且用X保存被删结点的值,则执行:
X= ST->data; ST = ST->next;
4、设栈S和队列Q的初始状态均为空,元素a、b、c、d、e、f、g依次进入栈S。
若每个元素出栈后立即进入队列Q,且7个元素出队的顺序是b、d、c、f、e、a、g,则栈S的容量至少是:
至少是 3
5、假设有5个整数以1、2、3、4、5的顺序被压入堆栈,且出栈顺序为3、5、4、2、1,那么为了获得这样的输出,堆栈大小至少为:
4
6、若元素a、b、c、d、e、f依次进栈,允许进栈、退栈操作交替进行,但不允许连续三次进行退栈工作,则不可能得到的出栈序列是:D
A.3 2 1 5 4 B.5 1 2 3 4 C.4 5 1 3 2 D.4 3 1 2 5
8、若一个栈的入栈序列为1、2、3、…、N,其输出序列为p1、p2、p3、…、pN。若p1=N,则pi为:
ooops按此顺序入栈,则有多少种不同的出栈顺序可以仍然得到ooops?
A.X= ST->data;
B.X= ST; ST = ST->next;
C.X= ST->data; ST = ST->next;
D.ST = ST->next; X= ST->data;
C.d c e b f a D.a f e d c b
A.线性表用指针,堆栈和队列用数组
B.堆栈和队列都是插入、删除受到约束的线性表
C.线性表和队列都可以用循环链表实现,但堆栈不能
D.堆栈和队列都不是线性结构,而线性表是
C:堆栈也可以是循环的
front和rear的值分别为0和4。当从队列中删除两个元素,再加入两个元素后,front和rear的值分别为多少?m的数组表示,且用队头指针front和队列元素个数size代替一般循环队列中的front和rear指针来表示队列的范围,(front+size-1)%m02判断
1、所谓“循环队列”是指用单向循环链表或者循环数组表示的队列。 F
理解一:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。存储在其中的队列称为循环队列
理解二:队列中含有front和rear两个指针,不同于单向链表
循环队列指的是后者,用数组表示的队列,利用求余数运算使得头尾相接
2、在用数组表示的循环队列中,front值一定小于等于rear值 F
大于小于等于都有可能
3、不论是入队列操作还是入栈操作,在顺序存储结构上都需要考虑"溢出"情况 T
03程序
04栈与递归的实现(跳过)
在定义一个过程或者函数时出现调用本过程或本函数的成分,称之为递归。若调用自身,称为直接递归;调用其它,称为间接递归
何时使用递归:
①定义是递归的,如求Fibonacci数列、求阶乘
②数据结构是递归的,如之前的链表类型的定义
③问题的求解的方法是递归的,如Hanoi问题:
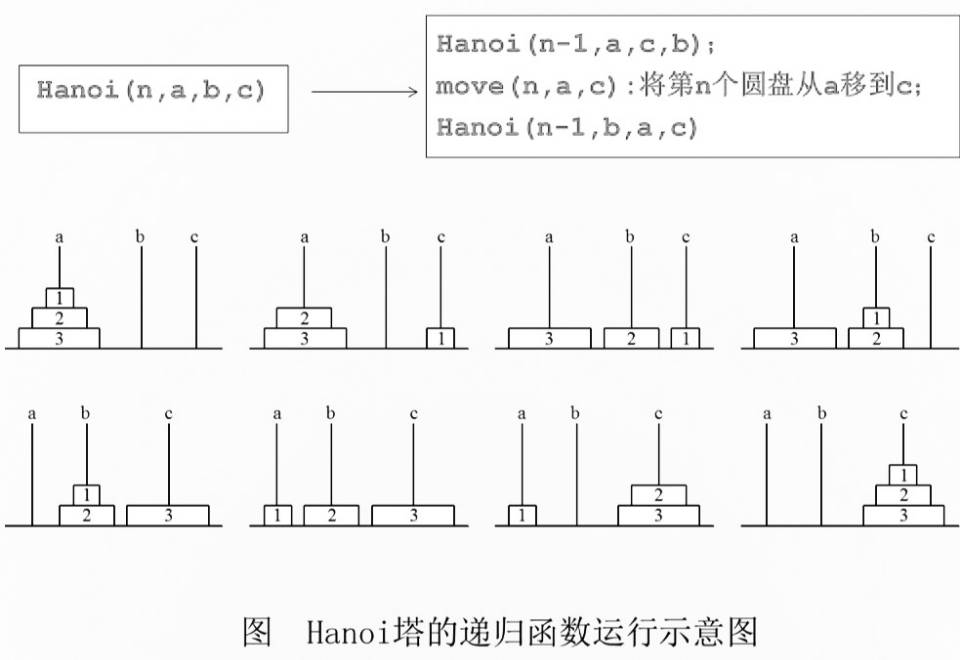
void Hanoi(int n,char x,char y,char z) { //将塔座x上按直径由小到大且至上而下编号为1至n //的n个圆盘按规则搬到塔座z上,y为辅助塔座 if(n==1) move(x,1,z); else { Hanoi(n-1,x,z,y); //将x'上编号为1至n-1的圆盘移到y,z作辅助塔 move(x,n,z);//将编号为n的圆盘从x移到z Hanoi(n-1,y,x,z); //将y上编号为1至n-1的圆盘移到z,x作辅助塔 } }
05 主要函数总结
#define STACK_INIT_SIZE 100 #define STACKINCREMENT 10 typedef char SElemType ; typedef struct { SElemType *base; SElemType *top; int stacksize; } STACK; int Pop(STACK &S) //出栈 { if(S.top==S.base) return 0; *S.top,S.top--; return 1; } int Push(STACK &S,char e) //入栈 { if(S.top-S.base>=S.stacksize) { S.base = (SElemType*)realloc(S.base,(S.stacksize+STACKINCREMENT)*sizeof(SElemType));; if(!S.base) { return -1; } S.top=S.base+S.stacksize; S.stacksize+=STACKINCREMENT; } *S.top++=e; return 1; } int StackEmpty(STACK& S) //判断是否栈空 { if(S.base == S.top) return 1; return -1; } int Gettop(STACK S,SElemType &e) //返回栈顶元素 { if(S.top==S.base) return 0; e= *(S.top-1); return 1; } int InitStack(STACK &S) //建立空栈 { S.base=(char *)malloc(STACK_INIT_SIZE*sizeof(char)); if(!S.base) exit(-1); S.top=S.base; S.stacksize=STACK_INIT_SIZE; return 1; }
附 期中题目
01选择
1、在双向循环链表结点p之后插入s的语句是:A
A.s->prior=p; s->next=p->next; p->next->prior=s; p->next=s;
B.s->prior=p; s->next=p->next; p->next=s; p->next->prior=s;
C.p->next=s; s->prior=p; p->next->prior=s ; s->next=p->next;
D.p->next->prior=s; p->next=s; s->prior=p; s->next=p->next;
2、判断一个循环队列QU(最多元素为MaxSize)为空的条件是()。C
A.QU.front == (QU.rear + 1) % MaxSize
B.QU.front != QU.rear
C.QU.front == QU.rear
D.QU.front != (QU.rear + 1) % MaxSize
在循环队列中,如果队列中有元素,则首尾指针不会指向同一个结点,如果首尾指针指向同一个结点,则说明队列中没有元素,因此为空。
3、通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着( )。C
A.数据元素所包含的数据项的个数要相等
B.数据在同一范围内取值
C.不仅数据元素所包含的数据项的个数要相同,而且对应数据项的类型要一致
D.每个数据元素都一样
4、数组A[1..5,1..6]每个元素占5个单元,将其按行优先次序存储在起始地址为1000的连续的内存单元中,则元素A[5,5]的地址为:1140

5、下面代码段的时间复杂度是()。O(n2)
x=0; for( i=1; i<n; i++ ) for ( j=1; j<=n-i; j++ ) x++;
(n-1)+(n-2)+(n-3)+.........+(n-n)
6、由两个栈共享一个向量空间的好处是( )。C
A.减少存取时间,降低下溢发生的机率
B.节省存储空间,降低下溢发生的机率
C.节省存储空间,降低上溢发生的机率
D.减少存取时间,降低上溢发生的机率
7、某队列允许在其两端进行入队操作,但仅允许在一端进行出队操作。若元素a、b、c、d、e依次入此队列后再进行出队操作,则不可能得到的出队序列是:B
A.d b a c e
B.d b c a e
C.e c b a d
D.b a c d e
02判断
1、假设模式串是abababaab,则KMP模式匹配算法中的next[j] = 0 1 1 2 3 4 5 6 2 T
2、在用数组表示的循环队列中,front值一定小于等于rear值。 F
rear在对max取余之后会从零开始,但这时front并不是零。所以会出现front>rear,( >,=,<三种情况都有可能出现)。
3、对于某些算法,随着问题规模的扩大,所花的时间不一定单调增加。 T
4、链表的每个结点都恰好有一个指针。 F

 浙公网安备 33010602011771号
浙公网安备 33010602011771号