Stochastic Gradient Descent收敛判断及收敛速度的控制
要判断Stochastic Gradient Descent是否收敛,可以像Batch Gradient Descent一样打印出iteration的次数和Cost的函数关系图,然后判断曲线是否呈现下降且区域某一个下限值的状态。由于训练样本m值很大,而对于每个样本,都会更新一次θ向量(权重向量),因此可以在每次更新θ向量前,计算当时状况下的cost值,然后每1000次迭代后,计算一次average cost的值。然后打印出iteration和cost之间的关系。
1、不同曲线图代表的含义及应对策略
可能会看到的曲线图有如下几种:
情况1

这样的曲线说明算法已经收敛。
如果我们使用小一点的学习率α,那么可能最终会训练到比较好的θ向量(红色线)

但是小的学习率也意味着更长的训练时间。
情况2
如果我们不是1000次迭代计算并打印一次,而是5000次迭代后才计算并打印一次。那么曲线可能会更加平滑一些(绿色线)。

情况3
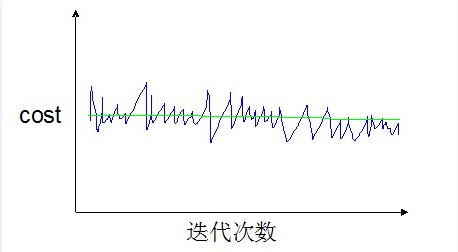
如果我们得到的曲线(1000次迭代并打印)是波动很剧烈,并且没有显示任何下降趋势,如下图:

那么有两种可能,一噪声太剧烈而无法看出算法收敛的趋势;二算法没有收敛。
这种情况下,我们可以调整打印的步长(比如5000次迭代才计算并打印一次),那么可能会得到两种不同的曲线(如下两幅图所示)。
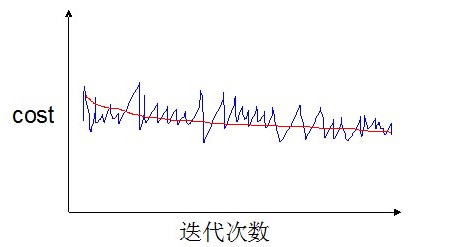
如果得到得是类似这条红色的曲线,那么说明算法已经收敛或已经表现出收敛的趋势了。如果得到的是如下图所示的绿色的线,说明算法没有收敛。
情况4
还有一种情况,就是曲线不但没有呈现下降的趋势,反而出现了上升的趋势,如下图:
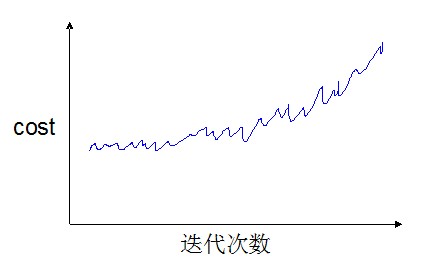
这说明学习率α设置得过大,需要调小学习率。
2、学习率的设置
当学习率比较小的时候,可以训练出更优的权重向量。但是较小的学习率也意味着更长的训练时间,而且如果是非凸问题则还有可能会陷入局部解中。那么,如果使用动态递减的学习率(即在学习开始之初,学习率较大,然后根据迭代次数的增加,学习率逐渐减小)也许会好一些。这样我们可以用一个式子来按照迭代次数调整学习率,例如:

常量1和常量2的目的是为了保证学习率在一个正常的范围内(不至于当循环次数很高或很低时,学习率会变得过大或过小)。
通过调整学习率(手工或如上式自动调整),就可以控制算法收敛的速度。
Reference:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号