Java8函数式编程
Java8函数式编程
为什么要用Java8
Java8在并行处理大型集合上有很大优势。可以更好的利用多核处理器的优势。Java8可以用Lambda表达式很简便的写出复杂的处理集合的逻辑。
函数式编程
函数式编程是一种编程范式,我们常见的编程范式有命令式编程(Imperative programming),函数式编程,逻辑式编程,常见的面向对象编程是也是一种命令式编程。
命令式编程是面向计算机硬件的抽象,有变量(对应着存储单元),赋值语句(获取,存储指令),表达式(内存引用和算术运算)和控制语句(跳转指令),一句话,命令式程序就是一个冯诺依曼机的指令序列。而函数式编程是面向数学的抽象,将计算描述为一种表达式求值,一句话,函数式程序就是一个表达式。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。在函数式语言中,函数作为一等公民,可以在任何地方定义,在函数内或函数外,可以作为函数的参数和返回值,可以对函数进行组合。
Java是一门面向对象的语言,对函数式编程的支持并不全面,如果想深入理解学习函数式编程可以学习Scala、Clojure,这两种语言都是可以在jvm上运行的。
lambda表达式
Java8最大的改变就是加入了lambda表达式。什么是lambda表达式呢?
简单来说,编程中提到的 lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
比如有些函数你只会使用一次,但是你却给他定义一次,这个函数就成了污染函数,匿名函数就是用来干这个的。
举个栗子:
faculties.sort(new Comparator
@Override
public int compare(Faculty o1, Faculty o2) {
return o1.getName().compareTo(o2.getName());
}
});
为了给这个专业列表(faculties)排序,你专门写了一个匿名内部类,来实现比较大小的方法。这样看起来又臃肿又复杂,如果用lambda表达式就很简单了:
faculties.sort((f1, f2) -> f1.getName().compareTo(f2.getName()));
还可以用方法引用可以更简单:
faculties.sort(Comparator.comparing(Faculty::getName));
下面有各种不同的方法来写lambda表达式:
Runnable noArguments = () -> System.out.println("Hello World");
ActionListener oneArgument = event -> System.out.println("button clicked");
Runnable multiStatement = () -> {
System.out.print("Hello");
System.out.println(" World");
};
BinaryOperator
BinaryOperator
lambda表达式可以接受一个或者多个参数,lambda表达式可以转换成一个接口不能转化成类,转化成接口要保证接口中只有一个可以复写的方法。不然会报错。
Streams
Stream可以让我们在更高级别的抽象上写集合的处理代码,stream有一系列的方法来让我们使用。
现在有一需求,需要筛选出来自伦敦的艺术家,通常我们会这么写:
int count = 0;
for (Artist artist : allArtists) {
if (artist.isFrom("London")) {
count++;
}
}
用stream可以这么写:
long count = allArtists.stream()
.filter(artist -> artist.isFrom("London"))
.count();
这样看起来就清晰很多,而且效率也是差不多的,用stream不会循环两遍的,stream的方法分为eager和lazy两种,比如下面这段代码:
allArtists.stream()
.filter(artist -> {
System.out.println(artist.getName());
return artist.isFrom("London");
});
它不会打印任何东西,filter就是一个lazy的方法,那怎么区分lazy和eager方法呢?如果返回的还是一个stream那么就是一个lazy的方法,如果返回的不是stream就是eager方法。例如上面的count()方法返回的是int,那么就会被立刻执行。
collect(toList())
List
.collect(Collectors.toList());
assertEquals(Arrays.asList("a", "b", "c"), collected);
collect(toList())把一个Stream转换成List。
map
List
.map(string -> string.toUpperCase())
.collect(toList());
map可以把一种类型的stream数据转换成另一种。
filter
List
= Stream.of("a", "1abc", "abc1")
.filter(value -> isDigit(value.charAt(0)))
.collect(toList());
filter可以把filter内返回为true的的数据过滤出来。
flatMap
List
.flatMap(numbers -> numbers.stream())
.collect(toList());
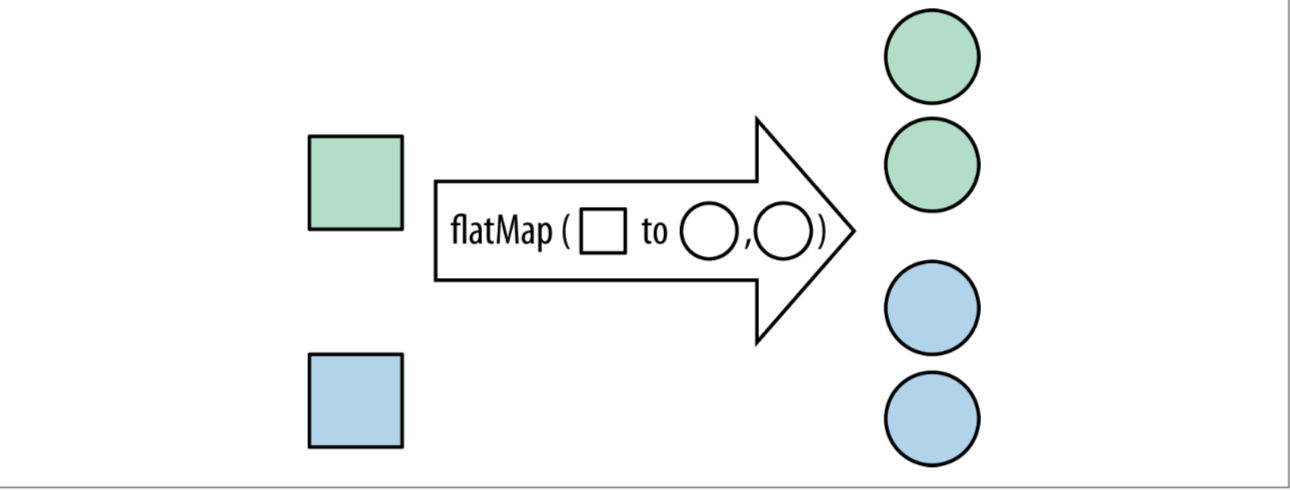
看上面的图更好理解一点,flatmap可以把stream的元素转换成stream,然后再把这些stream合成一个新的stream,而map只能把stream中的元素从一种类型转换成另一种类型。
max and min
List
在stream中找到最大值和最小值。
reduce
int count = Stream.of(1, 2, 3)
.reduce(0, (acc, element) -> acc + element);
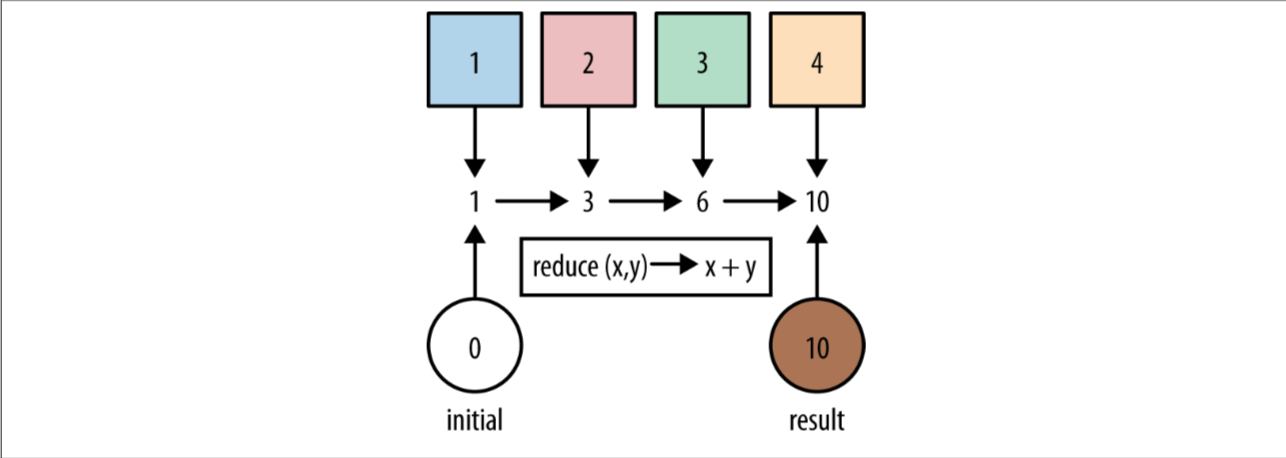
reduce会把第一个参数作为初始的acc,遍历stream的元素作为element,然后每次计算的结果会作为下次的acc.上面的代码可以拓展为:
BinaryOperator
accumulator.apply(
accumulator.apply(0, 1),
2), 3);
综合
把上面的各种方法结合起来用一下:
Set
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.collect(toSet());
- 过滤出名字以The为开头的艺术家
- 取出艺术家的国籍
- 得到一个艺术家的国籍的Set(去重)
再看一个例子:
public Set
.flatMap(album -> album.getTracks())
.filter(track -> track.getLength() > 60)
.map(track -> track.getName())
.collect(toSet());
}
- 把所有专辑的曲目取出来合并成一个stream
- 过滤出大于60秒的曲目
- 把曲目的名字取出来的
- 转换成一个Set
方法引用
artist -> artist.getName()
Artist::getName
(name, nationality) -> new Artist(name, nationality)
Artist::new
方法引用是一种更简洁的写法,而且比lambda表达式更容易理解。
对数据进行分类
一种分类方法是:partiioningBy
public Map<Boolean, List
return artists.collect(partitioningBy(artist -> artist.isSolo()));
}
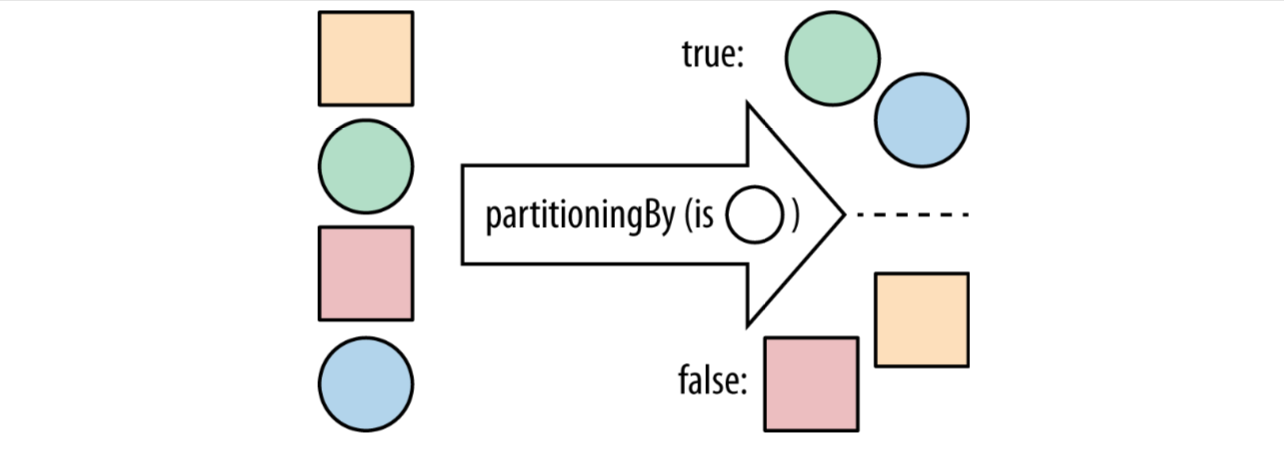
有时候我们想根据某个值对数据进行分类就可以用partitionBy,方法的返回的boolean值作为key,满足条件的值合并成list作为value。如果不想得到list还以在后面再加一个collector。
public Map<Boolean, Integer> bandsAndSolo(Stream
return artists.collect(partitioningBy(artist -> artist.isSolo(), list -> list.size()));
}
这样改一下就是把满足条件的值的数量作为value。
另一种是:groupingBy
public Map<Boolean, List
return artists.collect(partitioningBy(artist -> artist.isSolo(), artist.size()));
}

不同点在于partitioningBy只能把boolean作为key,而且永远只有两个entry,效率要高一点。而groupingBy可以把任意对象作为key。
总结
Java8加入的lambda表达式和stream库,可以让我们很方便的操作集合,聚合数据等等,熟练使用的话能很好提高编程效率,同时也提高了代码的可读性。当然它也有缺点,比如不方便debug,有一定的学习成本。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号