CTF自学

刷了刷CTF,记录一下模糊的和不会的知识点[平台:ctfhub: https://www.ctfhub.com/ 攻防世界:https://adworld.xctf.org.cn/]
robots协议:网络爬虫排除标准 它是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt 是基于人文道德规范建立的标准,不具备强制性(有点类似于readme.md?)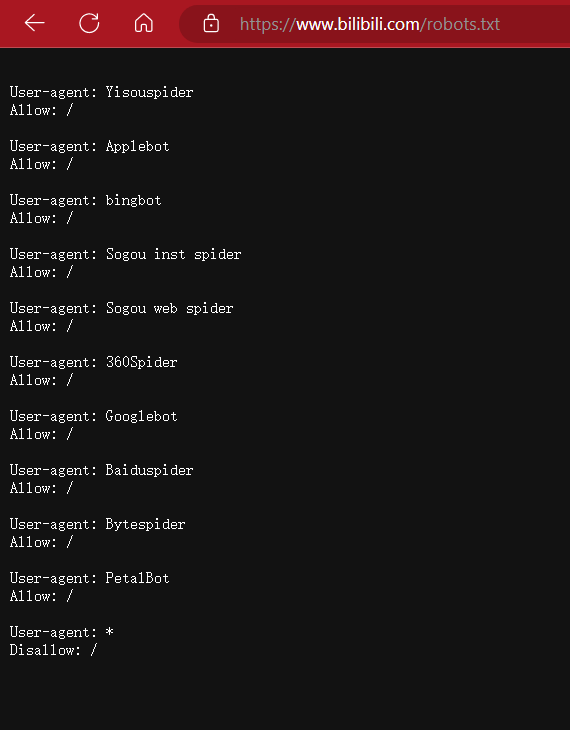
index.php 备份文件后缀:通常备份文件的后缀名为.bak 所以 index. php 的备份文件名为 index. php.bak
cookie:是web服务器为了识别用户身份而设置的一小段文本文件(一小段数据) 可通过Burpsuite爬取网页中的数据包 深入理解Cookie - 简书 (jianshu.com)
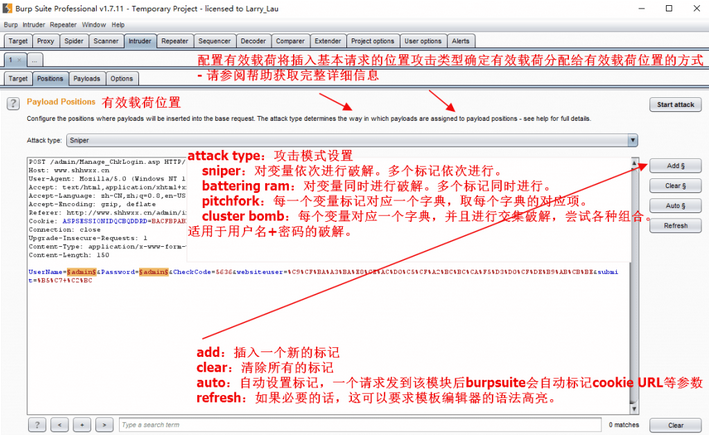
php:
base64编码:特征是尾部可能会有等于号
caesar cipher(凯撒加密):

gif隐写:可以使用101editor打开gif图片 若gif图片无法在图片管理器中打开考虑图片是否文档开头中缺少GIF8[GIF文件头:47 49 46 38 39 61]
HTTP请求方式:

利用curl可以发送http请求获取服务器上的文件。它和F12的区别是F12 中的源代码通常是经过浏览器解析和渲染后的结果,它经过了 HTML、CSS 和 JavaScript 的处理,以便在浏览器中呈现页面。这意味着所看到的源代码包含了经过处理后的结果。而 curl返回的内容是服务器直接返回的原始内容,不经过任何处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号