06-服务器端命令(SQL)
SQL定义:结构化的查询语言,mysql接口程序只负责接收SQL,传送给SQL层
SQL种类
- DDL:数据库(对象)定义语言
- DCL:数据库控制语言(grant revoke)
- DML:数据(行)操作语言(update delete insert)
- DQL: 数据查询语言(show、select)
一、DDL:数据库(对象)定义语言:
DDL
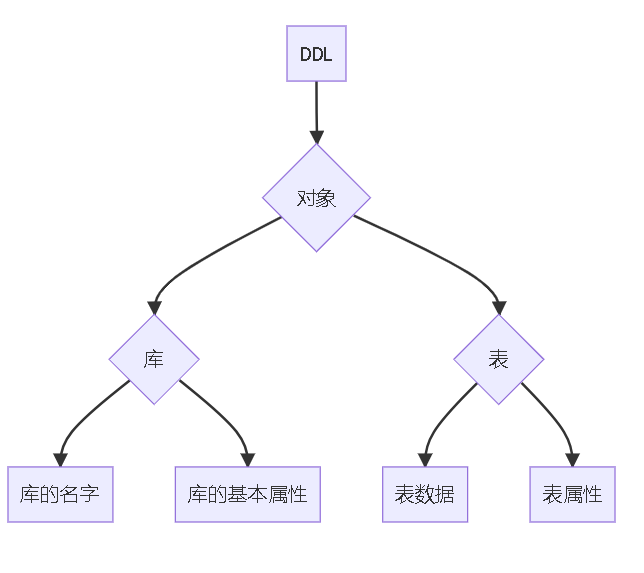
对库的操作
create database lufei;
create schema lf;
show databases;
create database llf CHARACTER SET utf8 ;
show create database llf; # 查询表的创建属性
drop database llf;
help create database;
字符集: CHARACTER SET [=] charset_name
排序规则:COLLATE [=] collation_name
改库的字符集:
ALTER DATABASE [db_name] CHARACTER SET charset_name COLLATE collation_name
mysql> alter database lf charset utf8mb4;
mysql> show create database lf;
对表的操作
- 表数据:数据行
- 表属性(元数据):表名、列名字、列定义(数据类型、约束、特殊列属性)、表的索引信息
创建:
create table t1 (id int ,name varchar(20));
查询:
show tables;
show create table t1; #查询创建语句
desc t1 # 查看列属性
show charset; #查看支持的字符集
show collation; # 查看支持的校对规则
删除
drop table t1;
修改:
- (1)在表中添加一列
alter table t1 add age int;
- (2)添加多列
alter table t1 add bridate datetime, add gender enum('M','F');
- (3)在指定列后添加一列
alter table t1 add stu_id int after id;
- (4)在表中最前添加一列
alter table t1 add sid int first;
- (5)删除列
alter table t1 drop sid;
- (6)修改列名
alter table t1 change name stu_name varchar(20);
- (7)修改列属性
alter table t1 modify stu_id varchar(20);
- (8)修改表名
rename table t1 to student;
alter table student rename to stu;
- 修改字符集
alter database oldboy CHARACTER SET utf8 collate utf8_general_ci;
alter table t1 CHARACTER SET latin1;
注意:更改字符集时,一定要保证由小往大改,后者必须是前者的严格超集。
生产中别随便改。
二、DML:数据(行)操作语言(update delete insert)
- 创建一个表
create table t1 (id int ,name varchar(20));
- 在表中插入数据
insert into t1 values(1,'zhang3'); # 插入一行数据
select * from t1;
insert into t1 values (2,'li4'),(3,'wang5'),(4,'ma6'); # 插入多行数据
insert into t1(name) values ('xyz'); # 只给某一列插入数据这里是name列
- 更新表中数据
update
update t1 set name='zhang33' ; ----会更新表中所有行的name字段,比较危险。
update t1 set name='zhang55' where id=1; ----update在使用时一般都会有where条件去限制。
- 删除数据
delete
delete from t1 ; --删除表中所有行,比较危险。一行一行删除表中数据。
delete from t1 where id=2;
truncate table t1; ---DDL 操作在物理上删除表数据,速度比较快。
三、DQL: 数据查询语言(show、select)
select 基本查询
- 语法
SELECT * FROM world.`city`;
列 库.表
- 查询中国(CHN)所有的城市信息
SELECT * FROM world.`city` WHERE countrycode='CHN';
- 查询中国(CHN)安徽省所有的城市信息。AND
SELECT * FROM world.`city` WHERE countrycode='CHN' AND District='anhui';
- 查询世界上人口数量在10w-20w城市信息 BETWEEN
SELECT * FROM world.`city` WHERE population BETWEEN 100000 AND 200000 ;
- 中国或者日本的所有城市信息 IN
SELECT * FROM world.city WHERE countrycode IN ('CHN','JPN');
- 模糊查询 LIKE
SELECT * FROM world.`city` WHERE countrycode LIKE 'CH%';
7.按照人口数量排序输出中国的城市信息(ASC\DESC)
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population ;
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population DESC; #从大到小
- LIMIT
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population DESC LIMIT 10; # 显示前10行
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population DESC LIMIT 12,10; # 从12行开始往后显示10行
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population DESC LIMIT 10 OFFSET 12; # 从12行开始往后显示10行
表连接查询
- 传统的连接写法使用where 中国所有城市信息+使用语言 (需要两个名字一样的列)
SELECT ci.id,ci.name,ci.countrycode,ci.population,cl.language # 需要查询的信息
FROM
city AS ci , countrylanguage AS cl # 在那个表中查询 AS设置别名
WHERE
ci.countrycode='CHN' #查询个条件
AND
ci.`CountryCode` = cl.`CountryCode` # 两个表具有相同值的列
- 查询青岛这个城市,所在的国家具体叫什么名字 JOIN ON
SELECT ci.name ,ci.countrycode,ci.population ,co.name # 需要查询的列
FROM city AS ci # 哪个表和设置别名
JOIN
country AS co # 关联到那个表和设置别名
ON ci.countrycode=co.code #两个表具有相同值的列
AND
ci.name='qingdao'; # 查询的条件
group by +聚合函数(avg()、max()、min()、sum())
- 查询中国的总人口数量
SELECT countrycode ,SUM(population) FROM city
WHERE countrycode = 'chn'
GROUP BY countrycode;
- union 用来替换 or 、in()
SELECT * FROM world.city
WHERE countrycode IN ('CHN','JPN');
改写为:
SELECT * FROM world.city WHERE countrycode='chn'
UNION # 连接两个sql 查询的列需要一样
SELECT * FROM world.city WHERE countrycode='jpn'
一、简单查询
1、 查询并去重
#例一
select distinct post from employee;
#例二
select distinct sex,age from employee;
# distinct #去掉重复的查询结果
2、四则运算
# 将薪水列乘以12算出年薪
select salary*12 as id from employee;
3、查询结果进行拼接
#将emp_name和salary列查询的结果做拼接
select concat(emp_name,'---',salary) as id from employee;
#concat_ws 拼接,第一个值是拼接符,次数是|
select concat_ws('|',emp_name,salary) as id from employee;
4、查询出结果然后插入到另外一张表
* INSERT INTO t2(id,NAME) SELECT id,username FROM t1;
#将t1表的数据查出来插入到t2表
5、case语句条件判断查询显示
case 语句 将查出来的数据根据条件重新显示
SELECT
(
CASE
WHEN emp_name = 'jingliyang' THEN
emp_name
WHEN emp_name = 'alex' THEN
CONCAT(emp_name,'_BIGSB')
ELSE
CONCAT(emp_name, 'SB')
END
) AS new_name
FROM
employee;
二、 where 约束
1、 比较运算符
>< >= <= <> !=
select salary from employee where salary >10000;
2、范围
- between 80 and 100 值在80到100之间
- in(100,200)匹配100或200的 not in(100,200) 不是100和200的
#一万到两万
select salary from employee where salary between 10000 and 20000;
#一万或者两万
select salary from employee where salary in (10000,20000);
3、like 'e%' 模糊查询
- 通配符可以是%或_,
- %表示任意多字符
- _表示一个字符
# 名字里有j字母的
select emp_name from employee where emp_name like '%j%';
# i后边有一个任意字符
select emp_name from employee where emp_name like '%i_';
4、 逻辑运算符:
- 在多个条件直接可以使用逻辑运算符 and or not
# 薪资不是一万或者两万并且年龄是18岁的
select * from employee where salary not in (10000,20000) and age=18;
# 薪资不是一万或者两万或者年龄是18岁的
select * from employee where salary not in (10000,20000) or age=18;
6、regexp #正则匹配,只能匹配字符串数据类型
SELECT * FROM employee WHERE emp_name REGEXP '^ale';
三、分组聚合
解释:把重复的数据项去重,形成不同的组,比如男和女分成两组男生一组女生一组
- 分组 group by 通常与聚合函数一起使用,但求出来的值只是和分组字段进行对应,并不和其他任何字段对应
- group_concat 显示组中所有数据,只能看,程序中不能拿出来
SELECT post,group_concat(emp_name) FROM employee GROUP BY post; #显示一个岗位的所有人
- 聚合函数
- count 计数,计算有多少条数据
- max 求最大值
- min 求修小值
- sum 求和
- avg 求和
例子:
# count
SELECT sex,count(id) FROM employee GROUP BY sex; #求男生女生各有多少人
select office,count(id) from employee group by office; # 每个办公司有多少人
# max 一个组的最大值
SELECT post,MAX(salary) FROM employee GROUP BY post;
select office,max(salary) from employee group by office; #每个办公司工资最多是多少
# min 一个组的最小值
SELECT post,Min(salary) FROM employee GROUP BY post;
select office,max(salary) from employee group by office; #每个办公司工资最少是多少
# sum 求和
SELECT post,sum(salary) FROM employee GROUP BY post; #每个岗位的薪资总和
# avg 平均值
SELECT post,avg(salary) FROM employee GROUP BY post; #每个岗位的平均值
注意:更具谁分组可以求这个组的总人数,最大值,平均值,求和,但是这个求出来的值只是和这个分组字段对应,并不和其他字段对应,这个时候查出来的其他字段都不生效
四、having 过滤语句在分组聚合后是用的
在having条件中可以使用聚合函数,但在where不行,
适合去筛选符合条件的某一组数据
select post,avg(salary) from employee group by post having avg(salary)>10000; #求岗位的平均薪水大于一万的岗位
五、排序
1、 order by 排序 默认是升序,desc降序
# 薪资从大到小排序
select * from employee order by salary desc;
#年龄从小到大排序,在年龄相同的清空下在根据薪资从大到小排序
select * from employee order by age, salary desc;
2、 limit 取某几条数据
默认是limit 0,3 意思是从一条数据开始取,取三条数据
如说是 limit 2,2 意思是从三开始取,取两条数据
注意:limit 2 offit 3 和limit 3,2的意思是一样的
select * from employee order by age limit 3; #年龄最小的前三个人
select * from employee order by age limit 3,2; #从第四条数据开始取值,取两条
六、 多表查询
- 所谓连表
- 总是在连接的时候创建一张大表,里边存放的是两张表的迪科尔积,再根据条件进行筛选
select * from employee,department where department.id=dep_id; #一般不用
# inner join 内连接
select * from 表1 inner join 表2 on 条件
SELECT * FROM employee INNER JOIN department ON department.id=employee.dep_id
SELECT * FROM employee AS t1 INNER JOIN department AS t2 ON t2.id=t1.dep_id ;
#外连接
# 左外连接 left join.....on... 优先显示左外连接
SELECT * FROM employee AS t1 left JOIN department AS t2 ON t2.id=t1.dep_id ;
# 右外连接 right join ....on.... 优先显示右表数据
SELECT * FROM employee AS t1 right JOIN department AS t2 ON t2.id=t1.dep_id ;
#全外连接 两张表的数据都会显示出来 full join 其他数据库支持 mysql不支持 但是可以通过union关键字实现把左外连接和右外连接两条语句连接到一起
SELECT * FROM employee AS t1 left JOIN department AS t2 ON t2.id=t1.dep_id
union
SELECT * FROM employee AS t1 right JOIN department AS t2 ON t2.id=t1.dep_id
例子:
1、查询技术部有多少人
select t2.name from department as t1 inner join employee as t2 on t1.id=t2.dep_id where t1.name='技术' ;
2、查询年龄大于25岁的员工以及所在部门
select t1.name,t2.name,t2.age from department as t1 inner join employee as t2 on t1.id=t2.dep_id where t2.age>25 ;
3、求每一个部门多少人
select d.name,count(e.id) from department d left join employee e on e.dep_id=d.id group by d.name;
4、求每个部门多少人并且将人生从高到底排序
select d.name,count(e.id) as a from department d left join employee e on e.dep_id=d.id group by d.name order by a desc;
七、子查询
把查询到的结果交给外层sql作为条件进行查询
1、 查询平均年龄在25岁以上的部门
select * from department where id in (select dep_id from employee group by dep_id having avg(age)>25);
select * from employee where age >(select avg(age) from employee); 大于平均年龄的人
2、查询技术部员工的姓名
# 思路,先查部门id再根据部门id查询员工姓名
select name from employee where dep_id in (select id from department where name='技术');
3、查询没有人的部门
select * from department where id not in (select distinct dep_id from employee);
3、查询所有大于平均年龄的人信息
#先得到平均年龄,然后再更加平均年龄做筛选
select * from employee where age>(select avg(age) from employee);
4、查询大于部门平均年龄人的名字和年龄
# 思路先查询每个部门的平均年龄,然后和员工表做连表查询(连表子查询)
select name,age from employee as t1 inner join (select dep_id,avg(age) as a from employee group by dep_id) as t2
on t1.dep_id=t2.dep_id where age>a;
带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。
而是返回一个真假值。True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
SELECT * FROM employee
WHERE EXISTS
(SELECT id FROM department WHERE id=200);
注意:如果一个问题既可以使用连表查询解决,也可以使用子查询解决,推荐使用连表查询,因为效率高
八、综合练习
1、查询男生、女生的人数;
SELECT gender,count(sid) as total from student GROUP BY gender;
2、查询姓“张”的学生名单;
SELECT * FROM student WHERE sname like '张%'
3、课程平均分从高到低显示
SELECT t1.cname,t2.ach FROM course as t1 INNER JOIN (SELECT course_id,AVG(num) as ach FROM score GROUP BY course_id ) as t2 on t1.cid=t2.course_id
4、查询有课程成绩小于60分的同学的学号、姓名;
select DISTINCT t1.sid,t1.sname from student as t1 INNER JOIN score as t2 on t1.sid=t2.student_id where t2.num<60
5、查询至少有一门课与学号为1的同学所学课程相同的同学的学号和姓名;
select sid,sname from student where sid in (select DISTINCT student_id from score where course_id in (select course_id from score where student_id=1) and student_id !=1)
6、查询出只选修了一门课程的全部学生的学号和姓名;
select sid,sname from student as t1 INNER JOIN
(select student_id,count(student_id) as avgs from score GROUP BY student_id HAVING avgs = 1) as t2 on t1.sid=t2.student_id
7、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
select course_id,max(num),MIN(num) from score GROUP BY course_id
8、查询课程编号“2”的成绩比课程编号“1”课程低的所有同学的学号、姓名
select sid,sname from student as stu right JOIN
(select t1.student_id from (select * from score where course_id=2) as t1
INNER JOIN
(select * from score where course_id=1) as t2 on t1.student_id=t2.student_id where t1.num<t2.num) as tmp
on
stu.sid=tmp.student_id
9、 查询“生物”课程比“物理”课程成绩高的所有学生的学号
select sid,sname from student as stu right JOIN
(select t1.student_id from (select * from score where course_id=(select cid from course WHERE cname='生物')) as t1
INNER JOIN
(select * from score where course_id=(select cid from course WHERE cname='物理')) as t2 on t1.student_id=t2.student_id where t1.num<t2.num) as tmp
on
stu.sid=tmp.student_id
10、查询平均成绩大于60分的同学的学号和平均成绩;
select student_id,avg(num) as avgs from score GROUP BY student_id HAVING avgs>60
11、查询所有同学的学号、姓名、选课数、总成绩;
select t1.sid,sname,count(student_id) as 选课数 ,sum(num) as 总成绩
from student as t1 LEFT JOIN score as t2 on t1.sid=t2.student_id GROUP by student_id ORDER BY sid
12、查询姓“李”的老师的个数;
select count(*) from teacher WHERE tname like '李%'
13、查询没学过“张磊老师”课的同学的学号、姓名;
select sid,sname from student where sid not in
(select student_id from score t2 INNER JOIN
(select t2.cid from teacher as t1 INNER JOIN course as t2 on t1.tid=t2.teacher_id WHERE tname='张磊老师') as t4 on t2.course_id=t4.cid)
14、查询学过“1”并且也学过编号“2”课程的同学的学号、姓名;
select t1.student_id from (select student_id from score where course_id=1) as t1 INNER JOIN
(select student_id from score where course_id=2 ) as t2 on t1.student_id=t2.student_id
15、查询学过“李平老师”所教的所有课的同学的学号、姓名;
select sid,sname from student as t1 INNER JOIN
(select student_id,count(student_id) as number from score as t1 INNER JOIN
(select cid from course as t1 INNER JOIN (select tid from teacher where tname='李平老师')
as t2 on t1.teacher_id=t2.tid) as
t2 on t1.course_id=t2.cid GROUP BY
student_id HAVING number=(select count(*) from course as t1 INNER JOIN (select tid from teacher where tname='李平老师')
as t2 on t1.teacher_id=t2.tid)) as t2 on t2.student_id=t1.sid
本文来自博客园,作者:EJW,转载请注明原文链接:https://www.cnblogs.com/ejjw/p/17930496.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号