Instruction-Following Agents with Multimodal Transformer
概述
提出了InstructRL,包含一个multimodal transformer用来将视觉obs和语言的instruction进行编码,以及一个transformer-based policy,可以基于编码的表示来输出actions。
前者在1M的image-text对和NL的text上进行训练,后者跟踪了整个obs和act的历史,自回归地输出动作。
问题
- 纯语言预训练模型
- 与视觉表示是分离的,使得区分视觉相关的语义(如颜色)变得困难
- 现有的预训练的多模态模型
- 在语言理解上不如只在language上训练的预训练模型,无法完成长的详细的指令
- 视觉输入和文本输入的表示是分开学习的,一般需要另外设计一个特别的网络结构来整合这些表示
动机
用图像和文本同时训练多模态模型:a large masked autoencoding transformer jointly trained on image-text and text-only data
方法
Multimodal Representation
pretrained backbone: M3AE(Multimodal masked autoencoder),基于ViT和BERT的transformer结构
- 在image-text数据集CC12M和text-only数据集上训练得到
Language & observation
-
Language Instruction
- 编码为\(E_x\in\R^{n\times d_e}\),\(n\)是tokens数量,\(d_e\)是embedding维度
-
Image Observation\(\{c^k_t\}^K_{k=1}\)
- 分割成image patches,用linear层转化为embedding
- 得到\(E_c\in\R^{l_c\times d_e}\),\(l_c\)是patch token的数量,\(d_e\)是embedding维度
image和text拼接得到\((E_c,E_x)\in\R^{(l_c+n)\times d_e}\),输入一系列transformer块得到最终的表示\(\hat o^k_t\in\R^{(l_c+n)\times d_e}\)
过一个average pooling得到\(o_t^k\in \R^{d_e}\)
\(L\)个中间层拼接,得到\(h_t^k\in\R^d,d=L\times d_e\)
\(K\)个相机拼接,得到\(h_t=\{h_t^1,\cdots,h_t^K\}\in\R^{K\times d}\)
Proprioception & Action
- Proprioception \(o_t^P\in \R^4\)用linear上采样得到\(z_t\in\R^4\times d\)
- Action 映射到\(f_t\in \R^d\)
Transformer-based Policy
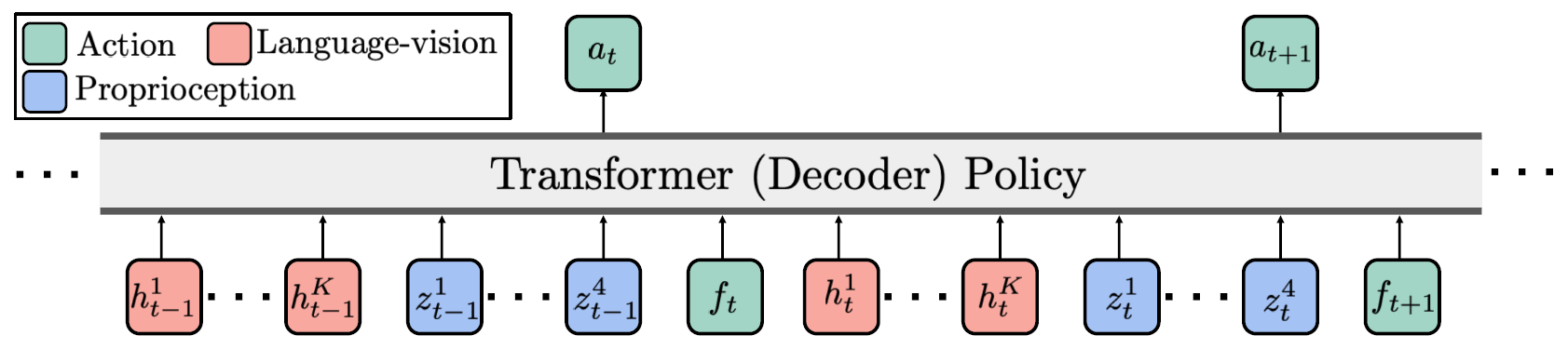
context-conditional policy(上下文调制的策略),上下文长度为4,即\(4(K+5)\)个embedding
用behavioral cloning来训练policy,loss function:
实验
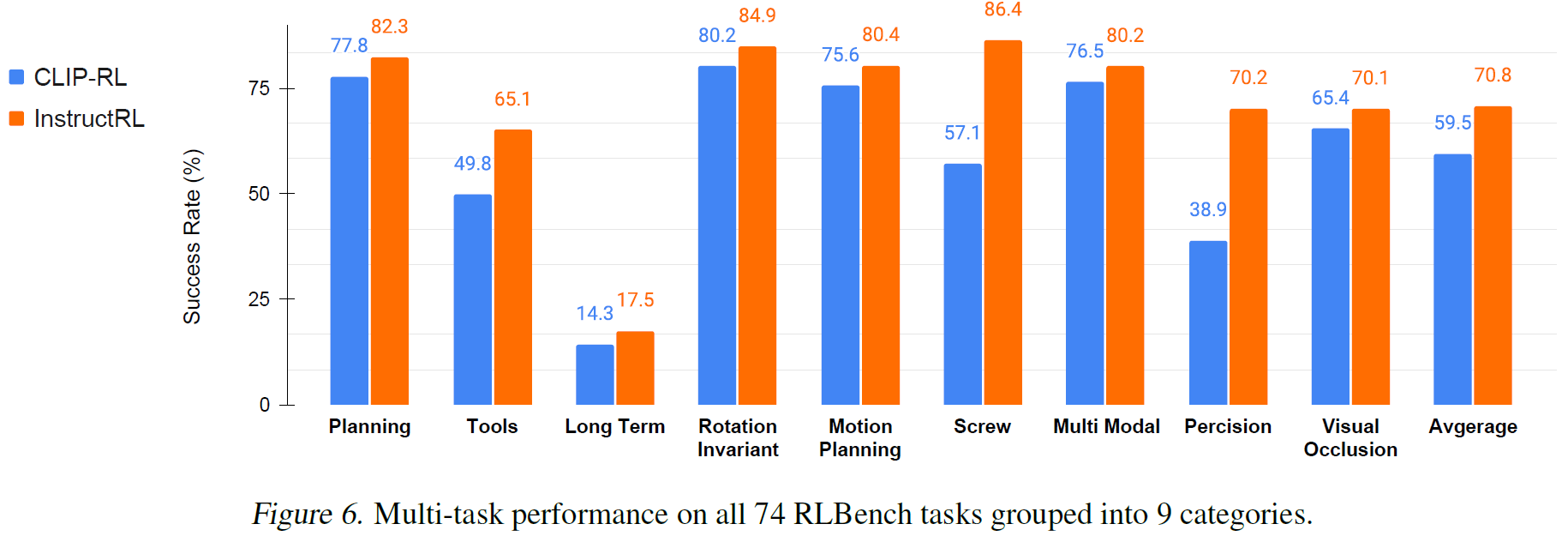
benchmark:RLBench 74个task,每个task有100个demonstration,task分为9个类型
每个episode会对物体的形状、颜色、位置进行随机;
模型训练100K个iteration,每个task测500个ep的成功率
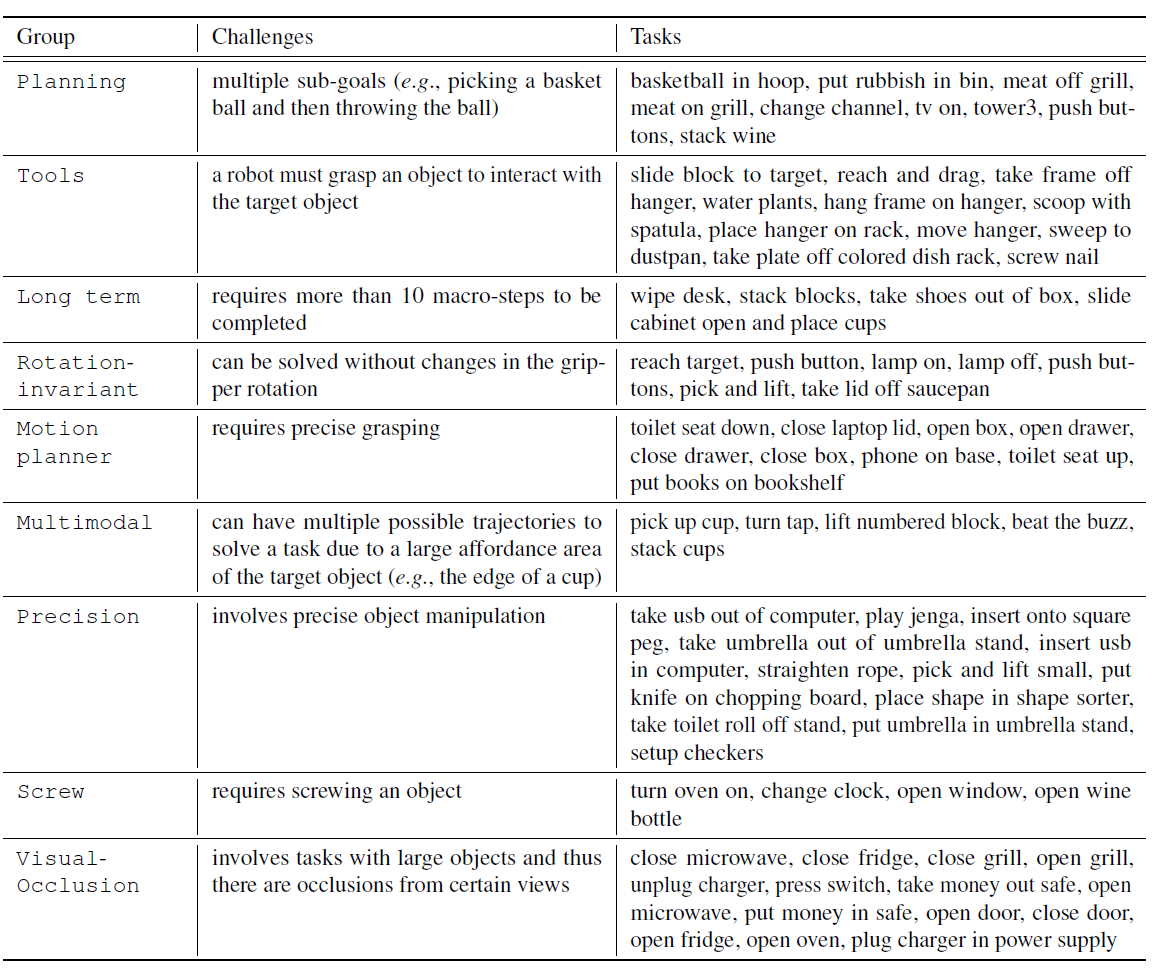
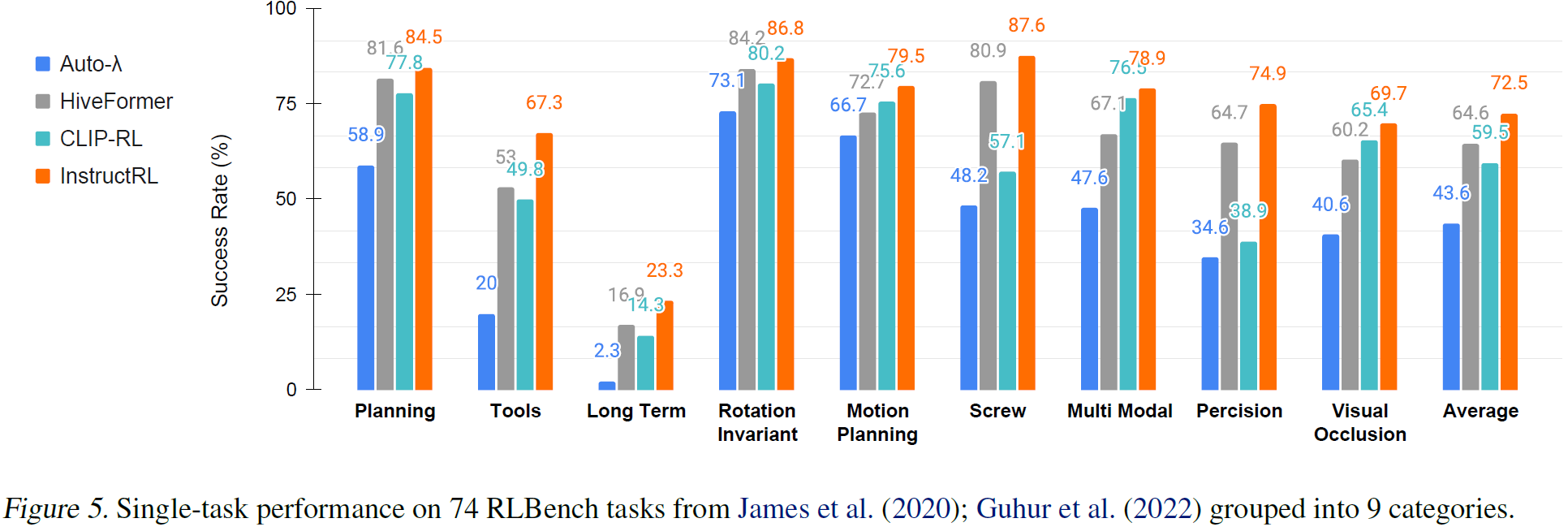
对比实验
两个baseline:
- Hive-Former 预训练的语言模型
- CLIP-RL 预训练的视觉语言模型

消融实验