A Survey on Large Language Model based Autonomous Agents
挑选了自己感兴趣的部分整理了一下。
A Survey on Large Language Model based Autonomous Agents
北大高林学院的一篇综述,从Construction, Application, Evaluation三个方面介绍了用LLM搭建的Agents,里面讲到的多智能体互动的工作比较多。综述最后还简单介绍了相关领域的未来挑战。以下将LLM-based Autonomous Agent简称为LLM-AA.
1 LLM-AA Construction
对LLM-AA的构建需要解决两个问题,一个是如何对agent的结构进行设计,另一个是基于结构如何强化agent的智能,可以对应为结构设计和数据应用两个板块。
1.1 Architecture Design
作者将LLM-AA的结构总结为下面的模式,由4部分组成。
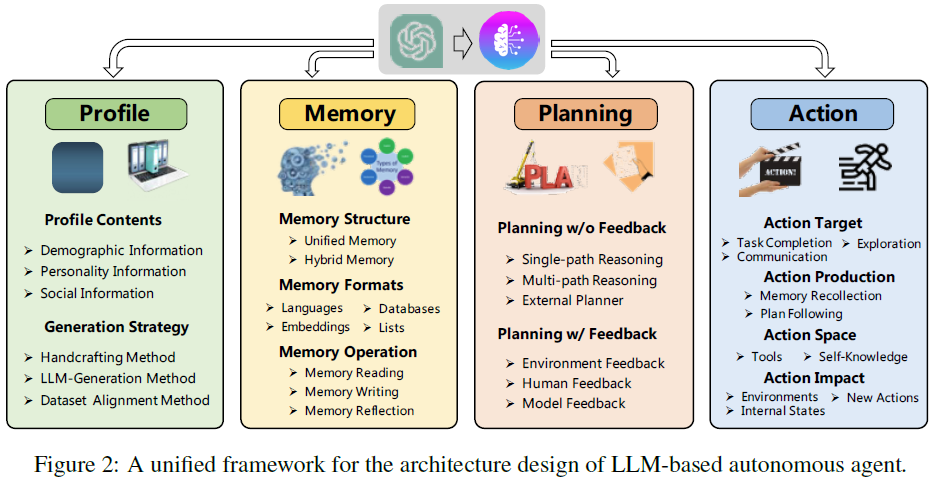
1.1.1 Profile
主要是对agent角色的定义。
在生成策略上,第一个Handcrafting方法是最常用的,例如:Generative Agent, MetaGPT, ChatDev, Self-collaboration, PTLLM, IPIP-NEO, BFI。LLM-Generation是指通过制定一定的生成规则,让LLM来生成大量agent的Profile,Dataset的方法则根据数据集(例如人口统计)中的一些特征(种族、性别、年龄)等等来对profile进行相应设计,期望达到模拟实际的目的。另外两个方法作者只分别给了一个例子。
1.1.2 Memory
作用是储存agent从环境获取的信息并且在未来的动作中加以利用,可以帮助agent积累经验、进行自我进化,并且行为更加稳定、合理、有效。作者根据认知心理学当中的理念,将memory分为短期和长期两种,并且认为短期记忆就是指agent对环境的感知(观测)信息,而长期记忆则指储存在数据结构中的经过提炼或不提炼的经历。
结构
- Unified Memory 是把长短期记忆放在一起,例如用一个可以更新的Prompt来表示,相关工作:RLP, SayPlan, CALYPSO, DEPS
- Hybrid Memory 则是明确地将两种记忆分开储存,相关工作:AgentSims, GITM, Reflexion, SCM, SimplyRetrieve, MemorySandbox。作者提到没有单独使用长期记忆的方法,并且表示这是因为短期记忆是agent感知世界的基础,不可或缺。
形式
- NL 形式的好处在于:比较灵活和易于理解;为agent行为提供了足够的语义信息,相关工作:Reflexion, Voyager。
- Embedding 形式可以提高记忆检索和读取的效率,相关工作:MemoryBank, GITM, ChatDev。
- Database 形式使用SQL之类的数据库,优点方面也是使用起来efficiently并且comprehensively,相关工作:ChatDB, DB-GPT。
- Structured List 形式也是在检索使用比较高效,相关工作:GITM, RET-LLM。
个人认为其实只有自然语言形式和结构化形式,分别发扬了语义信息丰富和使用方便快捷的优点。此外还有一些别的没有这么典型的形式,例如代码形式等等。
操作
-
memory reading 需要解决如何获取有价值信息的问题,一般有3个指标:recency, relevance, importance. 可以形式化为:
\[m^* = \arg\min_{m\in M} \alpha s^{rec}(q,m)+\beta s^{rel}(q,m)+\gamma s^{imp}(m) \]三种指标函数都有各种实现方法,其中\(s^{rel}\)采用的方法有:LSH, ANNOY, HNSW, FAISS, etc.
-
memory writing 需要解决两个问题:处理与已有记忆相似的新的记忆;记忆容量有限;
-
memory reflection 模拟人类对记忆的总结和梳理,一方面节约记忆容量,另一方面是提高自身智能和运行效率
1.1.3 Planning
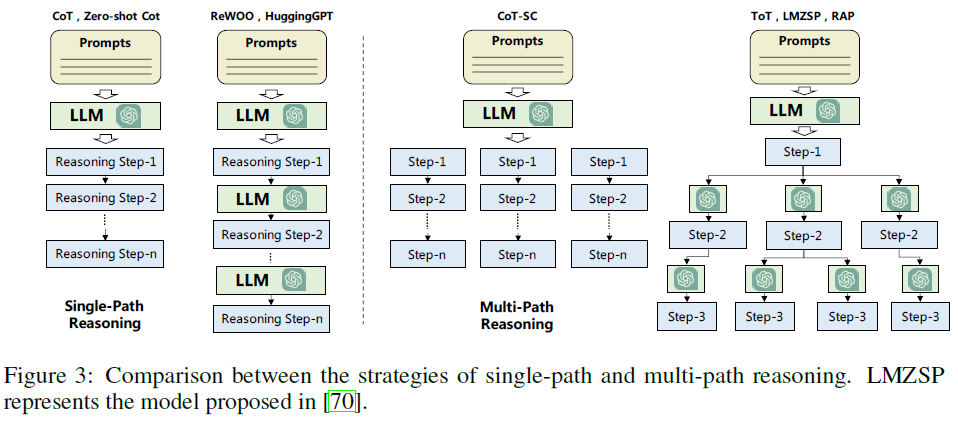
without feedback
- single-path reasoning
- Chain of Thought(CoT) 在prompt中插入reasoning步骤,引导LLM以step-by-step的方式进行plan和act
- Zero-shot-CoT 在prompt中加入"think step by step"之类的字眼来鼓励step-by-step
- Re-Prompting 检查每个step的结果是否满足了某些先决条件,并据此在prompt中加入修正错误的信息来重新生成plan
- ReWOO agents生成plan并各自获取obs,并将他们组合到一起得到最终结果
- HuggingGPT 将task分解为sub-goals,然后根据Huggingface来分别解决
- multi-path reasoning 生成最终plan的reasoning steps被分成多个树状结构的路径
- Self-consistent CoT(Cot-SC) 让CoT生成多个reasoning路径和相应的答案,把出现次数最多的答案作为最终答案
- Tree of Thoughts(ToT) 将planning tree的每个节点作为一种“thought”,用LLM对其进行评估,采用BFS或者DFS对planning-tree进行搜索
- RecMind 利用planning过程中丢弃的信息进行新的reasoning steps
- GoT 将ToT当中的结构拓展到图结构
- AoT 在prompt中插入算法示例来提升reasoning效果
- Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. 在每个planning step中生成多个可能的steps,根据他们和可采纳action之间的距离来进行选择
- Generating executable action plans with environmentally-aware language models 在prompt中加入和queries相似的examples,提升了上一个工作的性能
- RAP 建立了一个world model并通过蒙特卡洛树搜索来模拟其benefits,最终plan通过累加多次MCTS来得出
- Externeal Planner
- LLM+P 首个将task描述翻译为PDDL并采用相应planner的工作,生成的plan会被翻译回NL形式
- LLM-DP 将obs,world state,target objective 整合到PDDL中
- CO-LLM 表示LLM生成high-level plan可以,生成low-level control不行,设计了一个外部的low-level planner
with feedback 环境反馈、人类反馈、模型反馈
- Environmental Feedback
- ReAct 用thought-act-observation来构建prompt
- Voyager 用intermediate progress of program, execution error 和 self-verification results来生成plan
- Ghost 把环境的state、动作的成功或失败信息作为feedback
- SayPlan 把一个scene graph simulator对agent动作的影响和状态转移的估计作为feedback
- DEPS 在feedback中给出更多信息(任务失败的原因),使得LLM可以更好地plan
- LLM-Planner 根据执行过程中出现的object mismatch和不可行的plan来动态地更新生成的plan
- Inner Monologue 提供三种feedback:task是否成功;被动场景描述;主动场景描述;前两个组分由环境生成。
- Human Feedback 一种主观信号。可以让agent与人类的价值和喜好对齐,也有利于减轻幻觉问题
- Inner Monologue agent 可以主动向人类征求关于场景描述的反馈,并将人类反馈加入prompt中;事实上这个工作是将环境和人类的feedback结合起来使用的
- Model Feedback "internel feedback from the agents themselves" 一般是利用预训练的模型来生成feedback
- Self-refine: Iterative refinement with self-feedback 包含三个关键结构:输出、反馈、调整(refinement),agent的输出交给LLM进行评价和指导(如何做出调整),重复这个过程直到满足特定的条件
- SelfCheck agent可以在各种stage对自己的reasoning steps进行研究和评估,通过比较输出结果来进行纠错
- InterAct 用不同的LM作为冗余角色,例如checker或者sorter,来辅助main LM避免错误和低效率的动作
- ChatCoT 用一个评估模块作为model feedback,改善其reasoning过程
- Reflexion agetn根据自己的memory生成一个plan,然后evaluator将agent的轨迹作为输入给出反馈结果,特别之处还在于feedback不是一个scalar而是更detailed verbal feedback
1.1.4 Action
2 LLM-AA Application
3 LLM-AA Evaluation
主要有两种方式:主观subjective评估和客观objective评估
- subjective:人类标注,图灵测试
- objective:
- metrics 任务成功率、与人类的相似度、运行效率;
- protocols 真实世界模拟(games或者simulators)、社会评估(agent在模拟社会中的交互能力)、多任务评估(泛化能力);
- benchmarks 这部分就比较多了,眼熟的有ALFWorld、TRPG、Minecraft等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号