
之前开始学习scrapy,接触了AJax异步加载。一直没放到自己博客,趁现在不忙,也准备为下一个爬虫做知识储存,就分享给大家。
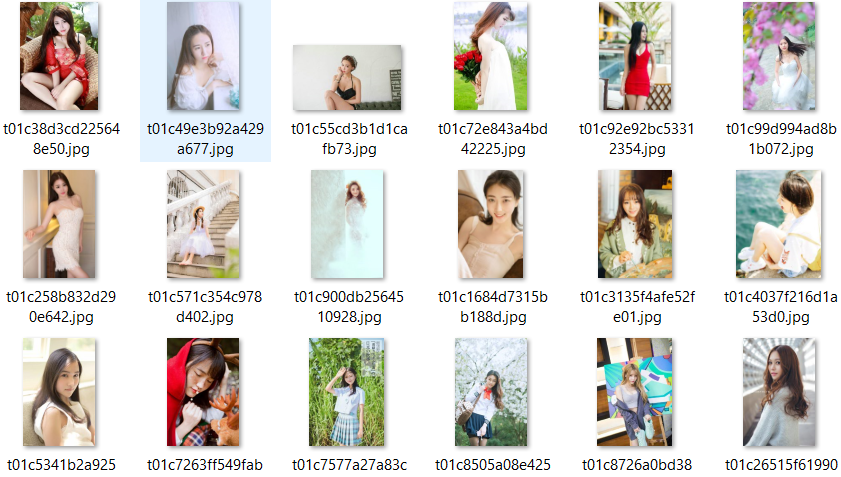
还是从爬取图片开始,先上图给大家看看成果,QAQ。
一、图片加载的方法
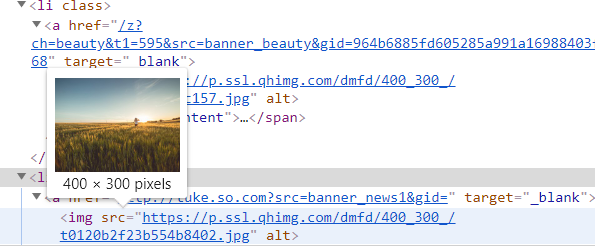
1.1:网页源码__javascript加载数据
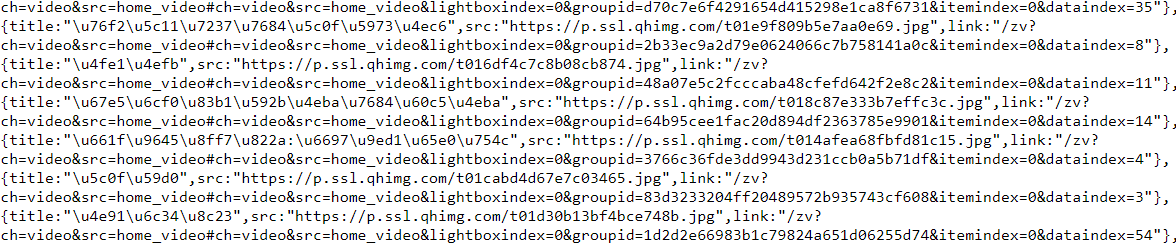
1.2:F12审查元素:滑动滑块,图片开始不断加载,
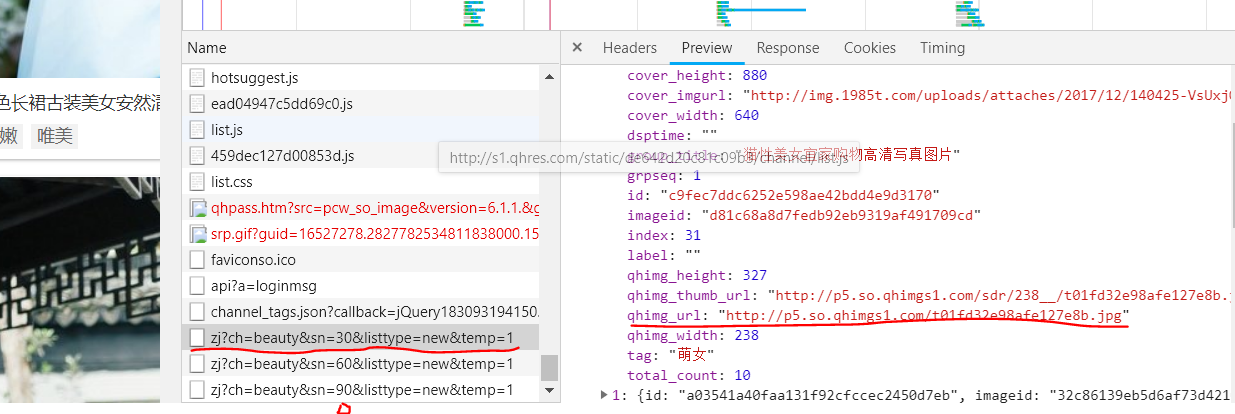
1.3:json数据:"http://image.so.com/zj?ch=beauty&sn=30&listtype=new&temp=1"

图片的URL储存在["list"]["qhimg_url"]
二、实现代码image.py.items.py,middlewares.py,settings.py,pipelines.py在我之前博客中能找到,在这里就不展示了,也可以进我的github:
# -*- coding: utf-8 -*- import scrapy from Tupian360.items import Tupian360Item import json import pdb from Tupian360.settings import USER_AGENT import random class ImageSpider(scrapy.Spider): name = 'image' allowed_domains = ['image.so.com'] pager_count = 0 headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Length': '11', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Host': 'image.so.com', 'Origin': 'image.so.com', 'Referer': 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'%pager_count, 'User-Agent': USER_AGENT, 'X-Requested-With': 'XMLHttpRequest', } old_urls = 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1' start_urls = [old_urls%pager_count] def parse(self, response): tupian = Tupian360Item() sel = json.loads(response.body.decode('utf8')) counts = sel['count'] self.pager_count += int(counts) new_url = self.old_urls%self.pager_count for link in sel['list']: tupian['image_urls'] = link['qhimg_url'] yield tupian yield scrapy.Request(new_url,callback=self.parse)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号