今天学习了很多,还是想给大家讲一讲正题:scrapy的动态加载AJax的网页爬取:selenium。让我们开始
三: 针对大型电商网站:京东网,因为比较有代表性,爬出来有点小成就。先给大家看下效果图。好让大家有点动力QAQ

一: 查看一下京东网加载商品的原理
1.1:将该网页加载的所有商品信息放入<li class="seckill_mod_goods">...</li>

1.2:获取网页源码,可以清楚的知道--无法在源码中找到商品信息所在的<li>...</li>标签

1.3: 那么现在问题来了,这些商品信息是从哪里加载出来的呢?那就是这次要将的Ajax动态加载信息,可以打开网页的审查元素,点击network,f5刷新,可以找到script类型的脚本
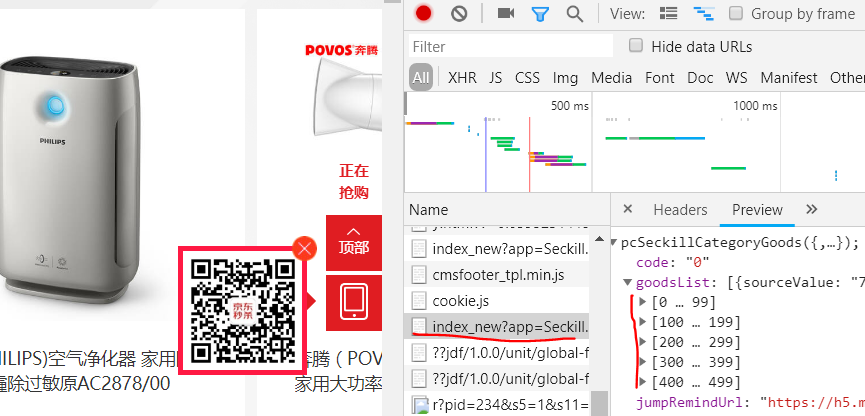
就是上图用红线画出来的script文件,查看中有[0..499]500个商品信息
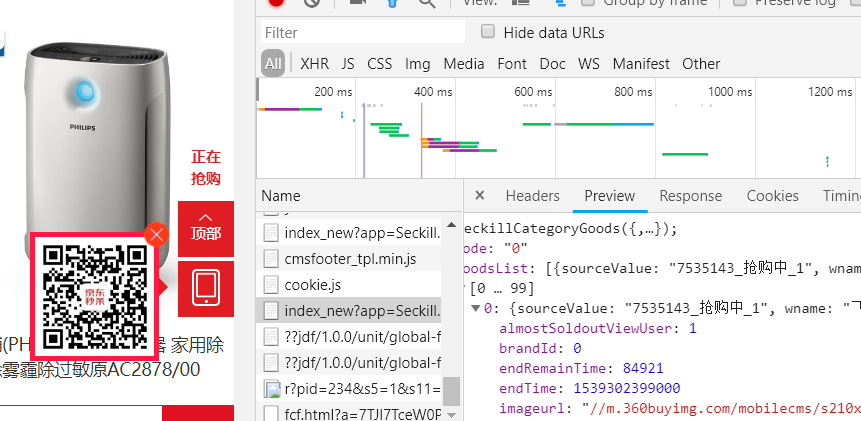
二: 了解了基本原理,再来看看源代码,就能很容易知道原理了__selenimu.py
#-*- coding:utf-8 -*- import time from selenium import webdriver import pdb from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys from lxml import etree import re from bs4 import BeautifulSoup chrome_options = Options() chrome_options.add_argument('--headless') driver = webdriver.Chrome(chrome_options=chrome_options) # 请求京东页面 driver.get( "https://miaosha.jd.com/category.html?cate_id=19") time.sleep(3) img_list = [] # 逐渐滚动浏览器窗口,令ajax逐渐加载 for i in range(1,200): js = ("var q=document.documentElement.scrollTop=" + str(300 * i)) # 谷歌 和 火狐 driver.execute_script(js) time.sleep(0.3) # 拿到页面源码 html = etree.HTML(driver.page_source) all_img_list = [] # 得到所有图片 img_group_list = html.xpath("//*[@class='seckill_mod_goods_link_img']/@src") # 收集所有图片链接到列表 for img_group in img_group_list: img_of_group = re.findall(r'.*q70\.jpg$',img_group) all_img_list.append(img_of_group) with open('vip.txt', 'w') as f: #pdb.set_trace() for img_list_item in all_img_list: if img_list_item[0]: f.write(img_list_item[0]+'\n') else: driver.quit() # 退出浏览器 driver.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号