
昨天晚上看了一些关于保存文件的相关资料,早早的睡了,白天根据网上查找的资料,自己再捡起来.弄了一上午就爬取出来了,开心!!!好吧,让我们开始
老规矩,先上图。大家也赶快行动起来
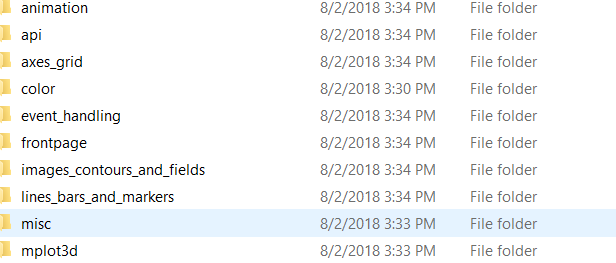
分类文件:
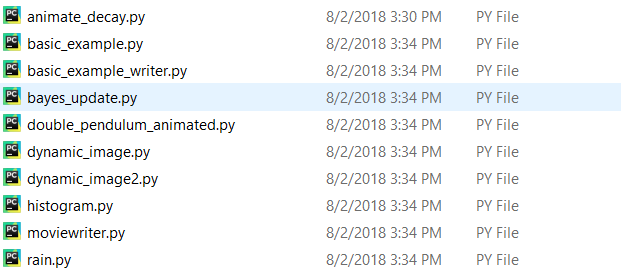
文件内coding.py
1.matlib.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from Matlib.items import MatlibItem import pdb class MatlibSpider(scrapy.Spider): name = 'matlib' allowed_domains = ['matplotlib.org'] start_urls = ['https://matplotlib.org/examples/index.html'] def parse(self, response): #le = LinkExtractor(restrict_css='div.toctree-wrapper.compound li.toctree-l2') le = LinkExtractor(restrict_css='div.toctree-wrapper.compound li.toctree-l1', deny='/index.html$') for link in le.extract_links(response): yield scrapy.Request(link.url,callback=self.parse_url) def parse_url(self,response): sel = response.css('a.reference.external::attr(href)').extract()[0] url = response.urljoin(sel) mpl = MatlibItem() #mpl['files_url'] = [url] #pdb.set_trace() mpl['files_url'] = url.encode('utf-8') #return mpl yield mpl
2.items.py
import scrapy class MatlibItem(scrapy.Item): files_url = scrapy.Field() files = scrapy.Field()
3.pipelines.py# -*- coding: utf-8 -*-
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import scrapy from scrapy.pipelines.files import FilesPipeline import urlparse from os.path import basename,dirname,join import pdb
class MyFilePipeline(FilesPipeline): def get_media_requests(self,item,info): #调用这个方法,爬虫才能保存文件!! #for file in item['files_url']: #yield scrapy.Request(file.encode('utf-8')) yield scrapy.Request(item['files_url'])
''' def file_path(self, request, response=None, info=None): #重写文件名,和路径 split_url = str(request.url).split('/') kind_name = split_url[-2] file_name = split_url[-1] return '%s/%s' % (kind_name, file_name) '''
def file_path(self,request,response=None,info=None):
path=urlparse.urlparse(request.url).path
return join(basename(dirname(path)),basename(path))
4.settings.py(其他和我之前发表的一样,大家可以去查找下)
ITEM_PIPELINES = { #'Matlib.pipelines.MatlibPipeline': 200, 'Matlib.pipelines.MyFilePipeline': 2, #'scrapy.pipelines.files.FilesPipeline': 1, }
遇到的问题:
1.matlib.py
1.url = response.urljoin(sel) :url需要解码才能在pipelines.py/scrapy.Request(item[''files_url]) 中运行下载
2.pipelines.py:
1.未重写文件名,会自动保存为checksum名,
'checksum': '715610c4375a1d749bc26b39cf7e7199',
'path': 'animation/bayes_update.py',
'url': 'https://matplotlib.org/examples/animation/bayes_update.py'}],
2.def get_media_requests(self,item,info): 调用这个函数,文件才能下载!!!看其他人重写路径的时候,没有调用这个函数,误导了我很久
如果有小伙伴,遇到了其他问题,欢迎留言,大家一起进步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号