机器学习(十七)— SVD奇异值分解
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是很多机器学习算法的基石。本文就对SVD的原理做一个总结,并讨论在在PCA降维算法中是如何运用运用SVD的。
1、基本原理

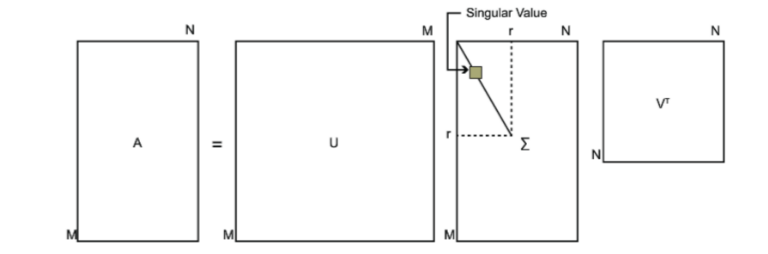
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。
对于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)

2、SVD用于PCA
注意到我们的SVD也可以得到协方差矩阵XTX最大的d个特征向量张成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵XTX,也能求出我们的右奇异矩阵V。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
在大数据时代,SVD可以并行化,但 SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
参考:http://www.cnblogs.com/pinard/p/6251584.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号