深度学习—BN的理解(二)
神经网络各个操作层的顺序:
1、sigmoid,tanh函数:conv -> bn -> sigmoid -> pooling
2、RELU激活函数:conv -> bn -> relu -> pooling
一般情况下,先激活函数,后pooling。但对于RELU激活函数,二者交换位置无区别。
论文原文里面是“weights -> batchnorm -> activation ->maxpooling-> weights -> batchnorm -> activation -> dropout”。原文认为这样可以利用到激活函数的不同区间(sigmoid的两个饱和区、中间的线性区等)实现不同的非线性效果,在特定的情况下也可能学习到一个恒等变换的batchnorm,一般用这个即可。
为了activation能更有效地使用输入信息,所以一般放在激活函数之前。
tensorflow中关于BN(Batch Normalization)的函数主要有两个,分别是:
- tf.nn.moments
- tf.nn.batch_normalization
- tf.layers.batch_normalization
- tf.contrib.layers.batch_norm
应用中一般使用 tf.layers.batch_normalization 进行归一化操作。因为集成度较高,不需要自己计算相关的均值和方差。
1、tf.nn.moments计算的是哪一部分均值方差?
举例:
tf.nn.moments(x, axes, name=None, keep_dims=False);其中x是输入,axes表示在哪一维计算,输出为计算的均值和方差。
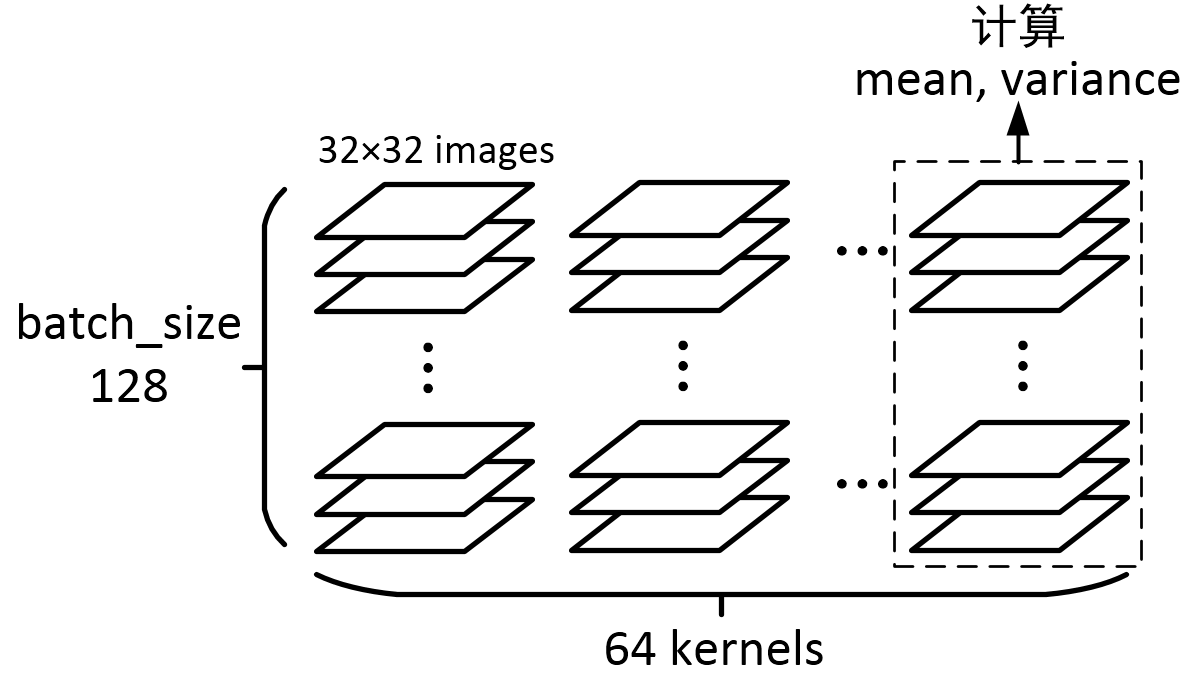
img = tf.Variable(tf.random_normal([128, 32, 32, 64])) axis = list(range(len(img.get_shape()) - 1)) mean, variance = tf.nn.moments(img, axis)
一个batch里的128个图,经过一个64 kernels卷积层处理,得到了128×64个图,再针对每一个kernel所对应的128个图,求它们所有像素的mean和variance,因为总共有64个kernels,输出的结果就是一个一维长度64的数组啦!最后输出是(64,)的数组向量。
2、 tf.layers.batch_normalization
在TensorFlow中,如果我们要使用batch normalization层,可以使用的API有tf.layers.batch_normalization和tf.contrib.layers.batch_norm,如果我们直接使用这两个API构建我们的网络,往往会出现训练的时候网络的表现非常好,而当测试的时候我们将其中的参数is_training设置为False时,网络的表现非常的差。这往往是因为我们训练的时候忽视了一个细节。
(1)方法1:
在tf.contrib.layers.batch_norm的帮助文档中我们看到有以下的文字
Note: when training, the moving_mean and moving_variance need to be updated. By default the update ops are placed in tf.GraphKeys.UPDATE_OPS, so they need to be added as a dependency to the train_op.
也就是说,我们需要在代码运行的过程中手动对moving_mean和moving_variance进行手动更新,代码如下:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
这一步非常的重要,很多人在训练的时候往往会忽略这一步,导致训练/测试时结果相差巨大。
(2)还有一个方法:需要将is_training改成True。
要注意的地方是,在做测试的时候,如果将is_training改为 False,就会出现测试accuracy很低的现象,需要将is_training改成True。虽然这样能得到高的accuracy,但是明显不合理!!
3、tf.nn.batch_normalization
自己写,用tf.nn.batch_normalization
tensorflow实现:
def batchNorm_layer(inputs, is_training, decay = 1e-5, epsilon = 1e-3): scale = tf.Variable(tf.ones(inputs.get_shape()[1:].as_list())) beta = tf.Variable(tf.zeros(inputs.get_shape()[1:].as_list())) pop_mean = tf.Variable(tf.zeros(inputs.get_shape()[1:].as_list()), trainable=False) pop_var = tf.Variable(tf.ones(inputs.get_shape()[1:].as_list()), trainable=False) if is_training: batch_mean, batch_var = tf.nn.moments(inputs, [0]) train_mean = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay)) train_var = tf.assign(pop_var, pop_var * decay + batch_var * (1 - decay)) with tf.control_dependencies([train_mean, train_var]): return tf.nn.batch_normalization(inputs, batch_mean, batch_var, beta, scale, epsilon) else: return tf.nn.batch_normalization(inputs, pop_mean, pop_var, beta, scale, epsilon)
参考:https://www.jianshu.com/p/0312e04e4e83

 浙公网安备 33010602011771号
浙公网安备 33010602011771号