机器学习(八)—GBDT 与 XGBOOST
RF、GBDT和XGBoost都属于集成学习(Ensemble Learning),集成学习的目的是通过结合多个基学习器的预测结果来改善单个学习器的泛化能力和鲁棒性。
根据个体学习器的生成方式,目前的集成学习方法大致分为两大类:即个体学习器之间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表就是Boosting,后者的代表是Bagging和“随机森林”(Random Forest)。
1、 GBDT和XGBoost区别
XGBOOST相比于GBDT有何不同?XGBOOST为什么快?XGBOOST如何支持并行?
- 传统的GBDT以CART树作为基学习器,XGBoost还支持线性分类器,这个时候XGBoost相当于L1和L2正则化的逻辑斯蒂回归(分类)或者线性回归(回归);
- 传统的GBDT在残差梯度方向拟合只用到一阶导数信息,XGBoost则对代价函数进行了二阶泰勒展开,得到一阶和二阶导数,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导;
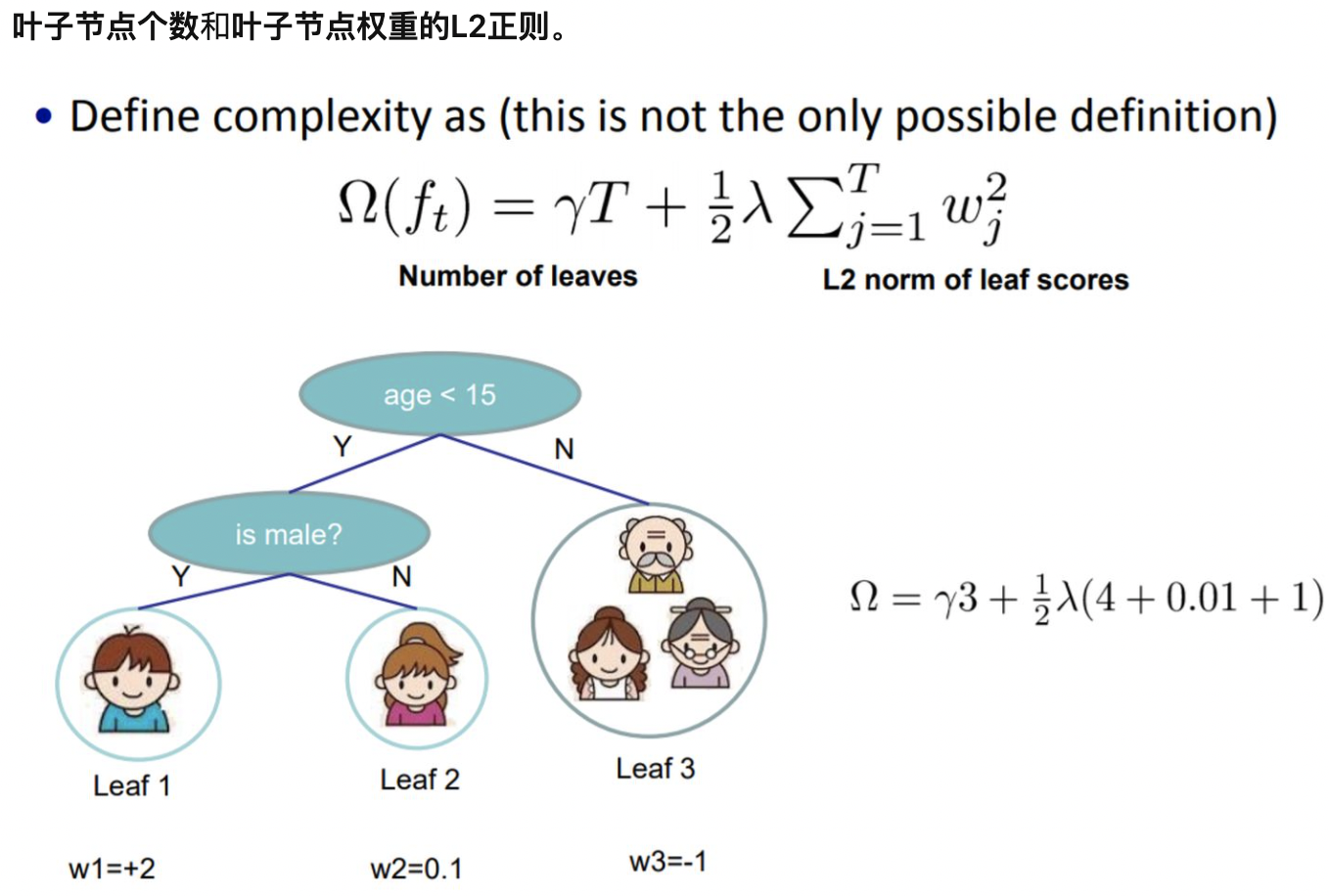
- XGBoost在代价函数中加入了正则项,用于控制模型的复杂度。从权衡方差偏差来看,它降低了模型的方差,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性;正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和;
- shrinkage(缩减),相当于学习速率(XGBoost中的eta)。XGBoost在进行完一次迭代时,会将叶子节点的权值乘上该系数,主要是为了削弱每棵树的影响,防止过拟合;
- 列抽样。XGBoost借鉴了随机森林的做法,支持列抽样(特征抽样),每次的输入特征不是全部特征,不仅防止过拟合,还能减少计算;
- 对缺失值的处理。对于特征的值有缺失的样本,XGBoost还可以自动 学习出它的分裂方向;为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形,分到那个子节点带来的增益大,默认的方向就是哪个子节点,这能大大提升算法的效率。忽略缺失值:在寻找splitpoint的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个工程技巧来减少了为稀疏离散特征寻找splitpoint的时间开销
- XGBoost工具支持并行。Boosting不是一种串行的结构吗?怎么并行 的?注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代 中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
XGBoost算法防止过拟合的方法有哪些?
- 在目标函数中添加了正则化。叶子节点个数+叶子节点权重的L2正则化。
- 列抽样。训练时只使用一部分的特征。
- 子采样。每轮计算可以不使用全部样本,类似bagging。
- early stopping。如果经过固定的迭代次数后,并没有在验证集上改善性能,停止训练过程。
- shrinkage。调小学习率增加树的数量,为了给后面的训练留出更多的空间。
正则项计算方式:
XGBoost的性能在GBDT上又有一步提升,而其性能也能通过各种比赛管窥一二。坊间对XGBoost最大的认知在于其能够自动地运用CPU的多线程进行并行计算,同时在算法精度上也进行了精度的提高。
由于GBDT在合理的参数设置下,往往要生成一定数量的树才能达到令人满意的准确率,在数据集较复杂时,模型可能需要几千次迭代运算。但是XGBoost利用并行的CPU更好的解决了这个问题。
其实XGBoost和GBDT的差别也较大,这一点也同样体现在其性能表现上,详见XGBoost与GBDT的区别。
通过树结构q和树叶权重w来描述一棵回归树。将树叶权重带入目标函数后,发现一旦树结构q确定了,目标函数能够唯一确定。所以模型构建问题最后转化为:找到一个合理的回归树结构q,使得它具有最小的目标函数。对于这个问题,XGBoost提供了贪心算法来枚举所有可能的树结构并找到最优的那个。
4、xgboost使用经验总结
- 多类别分类时,类别需要从0开始编码
- Watchlist不会影响模型训练。
- 类别特征必须编码,因为xgboost把特征默认都当成数值型的
- 调参:Notes on Parameter Tuning 以及 Complete Guide to Parameter Tuning in XGBoost (with codes in Python)
- 训练的时候,为了结果可复现,记得设置随机数种子。对于那些本质上是随机的过程,我们有必要控制随机的状态,这样才能重复的展现相同的结果。如果对随机状态不加控制,那么实验的结果就无法固定,而是随机的显示。
在需要设置random_state的地方给其赋值,当多次运行此段代码得到完全一样的结果,别人运行代码也可以复现你的过程。若不设置此参数则会随机选择一个种子,执行结果也会因此不同。虽然可以对random_state进行调参,但是调参后再训练集上表现好的模型未必在陌生训练集上表现好,所以一般会随便选择一个random_state的值作为参数。
- XGBoost的特征重要性是如何得到的?某个特征的重要性(feature score),等于它被选中为树节点分裂特征的次数的和,比如特征A在第一次迭代中(即第一棵树)被选中了1次去分裂树节点,在第二次迭代被选中2次…..那么最终特征A的feature score就是 1+2+….
5、参数调整
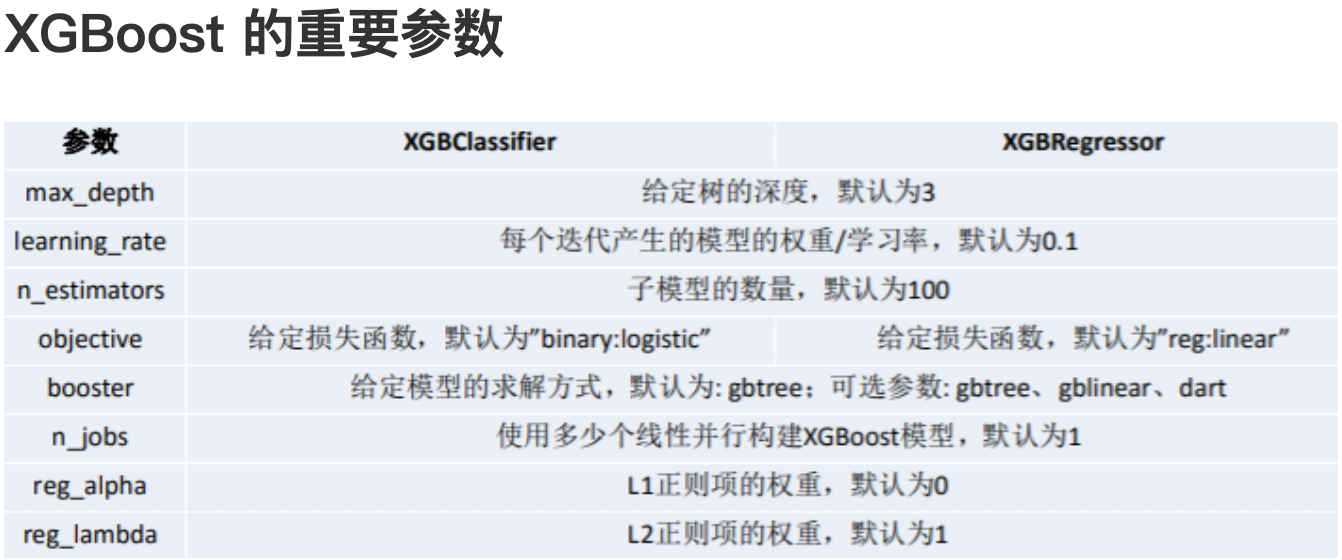
(1)通用参数:
- booster:我们有两种参数选择,
gbtree和gblinear。gbtree是采用树的结构来运行数据,而gblinear是基于线性模型。 - silent:静默模式,为
1时模型运行不输出。 - nthread: 使用线程数,一般我们设置成
-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程。
(2)Booster参数:
-
n_estimator: 也作
num_boosting_rounds,这是生成的最大树的数目,也是最大的迭代次数。 -
learning_rate: 有时也叫作
eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。我们一般使用比默认值小一点,0.1左右就很好。 -
gamma:系统默认为
0,我们也常用0。在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点。所以树生成的时候更不容易分裂节点。范围:[0,∞] -
subsample:系统默认为
1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1,0.5代表平均采样,防止过拟合. 范围:(0,1],注意不可取0。 -
colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:
0.5-1范围:(0,1] -
colsample_bylevel:默认为1,我们也设置为1.这个就相比于前一个更加细致了,它指的是每棵树每次节点分裂的时候列采样的比例
-
max_depth: 系统默认值为
6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。设置为0代表没有限制,范围:[0,∞] -
max_delta_step:默认
0,我们常用0.这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。 -
lambda:也称
reg_lambda,默认值为0。权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。这个参数在减少过拟合上很有帮助。 -
alpha:也称
reg_alpha默认为0,权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。 -
scale_pos_weight:默认为
1,在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
(3)学习目标参数objective [缺省值=reg:linear]
reg:linear– 线性回归
reg:logistic– 逻辑回归binary:logistic– 二分类逻辑回归,输出为概率binary:logitraw– 二分类逻辑回归,输出的结果为wTx
(4)评估方式
eval_metric [缺省值=通过目标函数选择]
-
rmse: 均方根误差 -
mae: 平均绝对值误差 -
logloss: negative log-likelihood -
error: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。 error@t: 不同的划分阈值可以通过 ‘t’进行设置 -
merror: 多分类错误率,计算公式为(wrong cases)/(all cases) -
mlogloss: 多分类log损失 -
auc: 曲线下的面积 -
ndcg: Normalized Discounted Cumulative Gain -
map: 平均正确率
一般来说,我们都会使用xgboost.train(params, dtrain)函数来训练我们的模型。这里的params指的是booster参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号