机器学习(三)—线性回归、逻辑回归、Softmax回归 的区别
1、什么是回归?
是一种监督学习方式,用于预测输入变量和输出变量之间的关系,等价于函数拟合,选择一条函数曲线使其更好的拟合已知数据且更好的预测未知数据。
2、线性回归
于一个一般的线性模型而言,其目标就是要建立输入变量和输出变量之间的回归模型。该模型是既是参数的线性组合,同时也是输入变量的线性组合。

最小二乘法,代价函数(平方误差代价函数,加1/2是为了方便求导):
这里使用基函数(basis function)对上面的线性模型进行拓展,即:线性回归模型是一组输入变量x的非线性基函数的线性组合。
(相当于SVM里面的核函数— 线性核、多项式核、高斯核、sigmoid核)
梯度下降法:
(1) 批处理梯度下降法:每次对全部训练数据进行求导后更新参数,能求得最优解;
(2) 增量梯度下降法:每扫描一个训练样本就更新参数,快,训练集很大时选择。
正规方程组求解(The normal equations):直接令代价函数对参数求导为0:
步长(学习率)的选择:过小,迭代次数非常高;过大,越过最小值无法收敛。0.01,0.03,0.1,0.3,1,3,10
特征值归一化:多维特征时,需要确保特征的取值范围在相同的尺度内计算过程才会收敛,常用方法有(1) (X- mean(X))/std(X);(2) (X - min) / (max - min)。
3、逻辑回归
目的:从训练数据特征学习出一个0/1分类模型。
预测函数:
优点:计算代价不高,易于理解和实现;缺点:容易欠拟合,分类精度不高
观测值的概率:
损失代价函数:
4. Softmax回归模型
当多分类问题时,logistic推广为softmax.
假设函数:
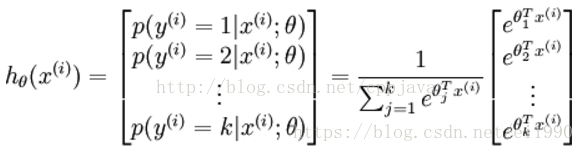
损失函数:
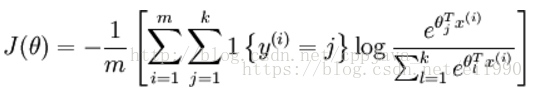
为了解决softmax回归的参数冗余带来的数值问题,可以加入权重衰减项
5. 过拟合和欠拟合如何产生,如何解决?
欠拟合:根本原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大;解决方法:增加特征维度;
过拟合:根本原因是特征维度过大,导致拟合的函数完美的经过训练集,但对新数据的预测结果差。解决方法:(1)减少特征维度;(2)正则化,降低参数值。
减少过拟合总结:过拟合主要是有两个原因造成的:数据太少+模型太复杂
(1)获取更多数据 :从数据源头获取更多数据;数据增强(Data Augmentation) :数据增强,常用的方式:上下左右翻转flip,旋转图像,平移变换,随机剪切crop图像,图像尺度变换,改变图像色差、对比度,仿射变换,扭曲图像特征,增强图像噪音(一般使用高斯噪音,盐椒噪音)等
(2)使用合适的模型:减少网络的层数、神经元个数等均可以限制网络的拟合能力;
(3)dropout
(3)正则化,在训练的时候限制权值变大;
(4)限制训练时间;通过评估测试;
(4)增加噪声 Noise: 输入时+权重上(高斯初始化)
(5)结合多种模型: Bagging用不同的模型拟合不同部分的训练集;Boosting只使用简单的神经网络;
6、逻辑回归和线性回归区别
1)线性回归要求变量服从正态分布,logistic回归对变量分布没有要求。
2)线性回归要求因变量是连续性数值变量,而logistic回归要求因变量是分类型变量。
3)线性回归要求自变量和因变量呈线性关系,而logistic回归不要求自变量和因变量呈线性关系
4)因变量不同:logistic回归是分析因变量取某个值的概率与自变量的关系,而线性回归是直接分析因变量与自变量的关系
Logistic Regression最大的特点就是将函数值收缩到[0,1]这个范围。
注意:能和逻辑斯蒂回归进行比较的就是牛逼闪闪的线性SVM了。大概意思是:直接用线性回归做分类因为考虑到了所有样本点到分类决策面的距离,所以在两类数据分布不均匀的时候将导致误差非常大;逻辑斯蒂回归回归和SVM克服了这个缺点,前者采用将所有数据采用sigmod函数进行了非线性映射,使得远离分类决策面的数据作用减弱;后者则直接去掉了远离分类决策面的数据,只考虑支持向量的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号