
推荐系统(11)—— 多目标排序应用实践_快手
1、推荐场景
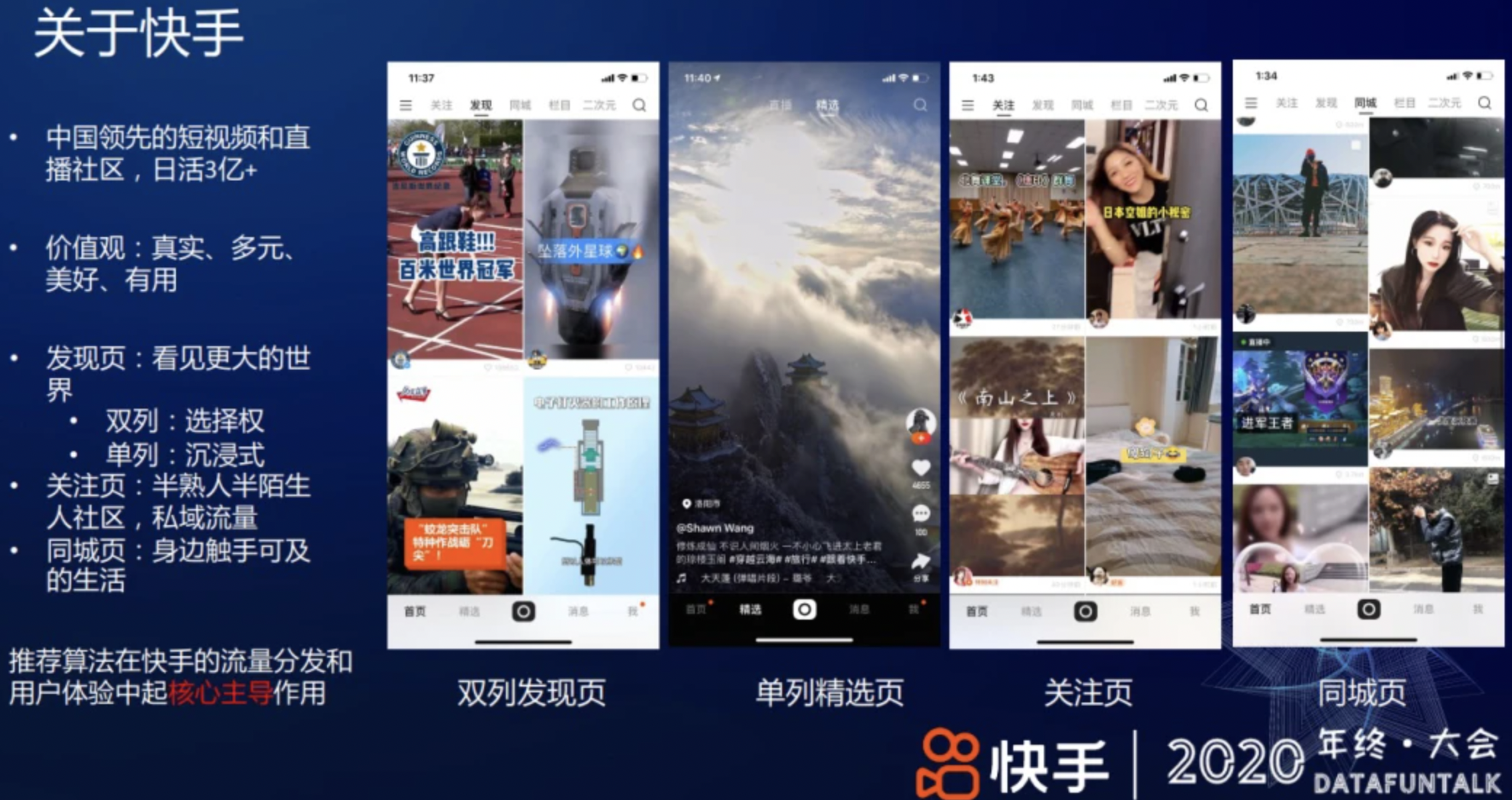
快手主要的流量形态 有 4 个页面:在这些流量分发的场景中,推荐算法是起着核心主导作用,直接决定了用户的体验。
① 发现页:致力于让用户看见更大的世界,分为单列和双列两种形态。
-
双列 点选模式,给用户提供选择的自由
-
单列 上下滑浏览,给用户沉浸式的浏览体验
② 关注页:一个半熟人半陌生人的社区,是私域流量的入口,比如和自己的好友互动,浏览关注订阅的生产者作品。
③ 同城页:带给用户身边触手可及的生活。
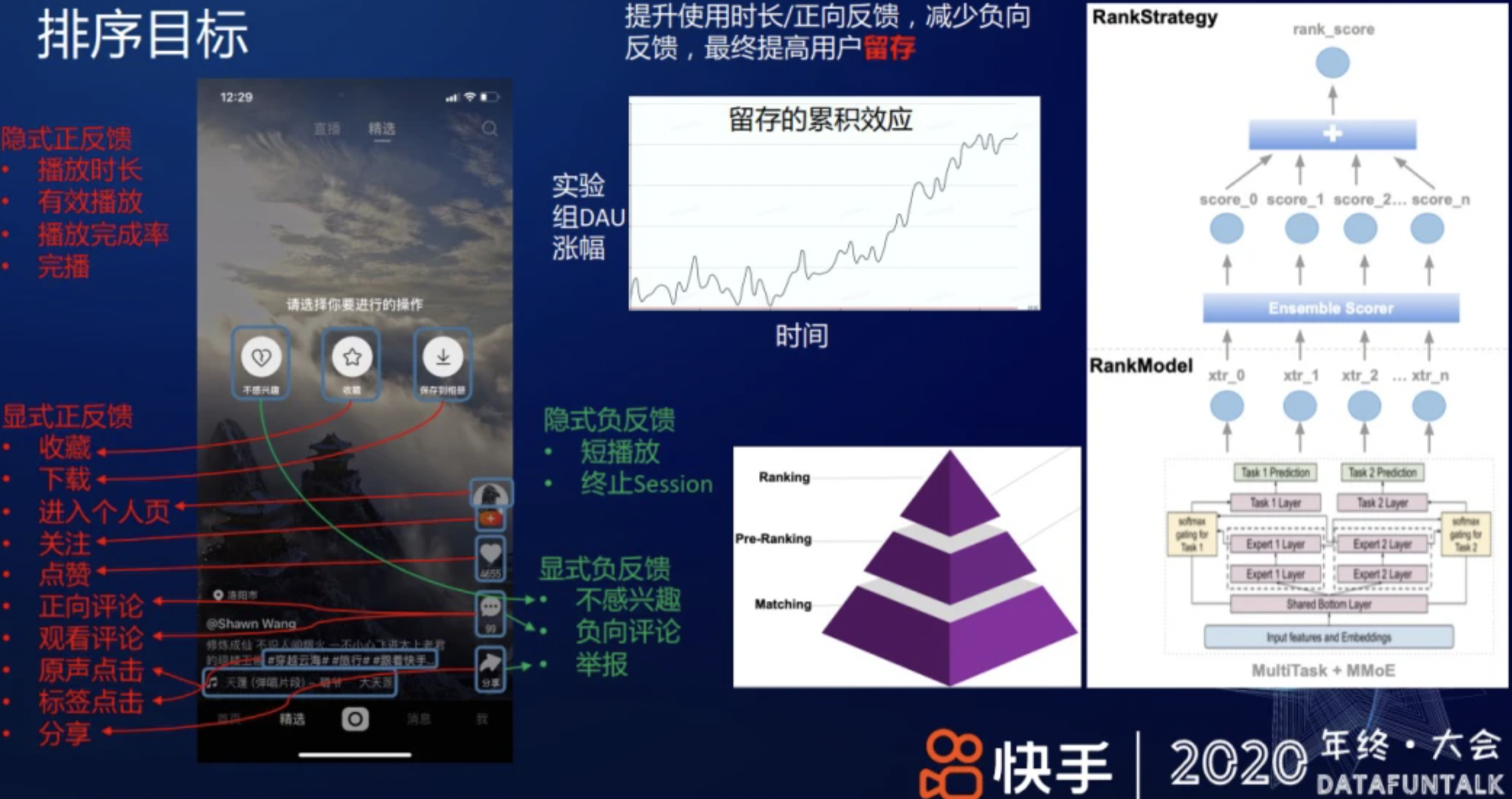
快手短视频推荐的主要优化目标是提高用户的整体的 DAU,让更多的用户持续使用快手,提升用户留存。在具体的排序建模过程,提升使用时长/正向反馈,减少负向反馈,可以提高用户留存。从上图中部曲线可见,留存提升在累计一段时间后会带来 DAU 的置信显著提升。此外,在推荐中,用户反馈分四类:
① 隐式正反馈,用户行为稠密,如用户在无意间的行为——播放时长、有效播放、播放完成率、完播、复播等;
② 显示正反馈,需要用户有意识地做出反馈,不同用户间的行为密度差异比较大,如收藏、下载、关注、点赞,发表正向评论等;
③ 隐式负反馈,用户行为稠密,如短播放、用户终止一次 session 等;
④ 显示负反馈,需要用户显式表达,如不感兴趣、负向评论、举报等。
而推荐的目标是提高正向反馈、减少负向反馈,提高用户体验。推荐分召回、粗排、精排、重排几个环节;在排序阶段,模型预估用户对内容的个性化偏好,比如,对上述各种用户反馈的预估值,然后,用机制策略将预估值融合成一个排序分,对视频排序。
2、多目标精排
粗排/精排的个性化多任务学习模型,能预估 20 多个不同的预估值,如点击率、有效播放率、播放时长、点赞率、关注率等,那如何用它来排序呢?从多任务学习到多目标排序,中间有一个过渡,即如何把这些预估值融合成一个单一的排序分?快手推荐追求时长、点赞、关注、分享等多种目标,以及减少不感兴趣等负向反馈。
从固定参数->xgb进行预估->神经网络->端到端的网络;
(1)树模型规则 Ensemble 融合:使用 GBDT 拟合组合 label,该方法的缺点是树模型表达能力有限,且无法 online learning。
(2)DNN 类的网络模型:相当于通过学习线性加权的超参数去拟合最终的组合收益。其次,用户特征选用了一种比较轻量级的方式,比如对用户划分不同的时间窗口:过去 1 分钟、5 分钟、15 分钟、...、2 小时,每个时间窗内,对推荐给他的视频,根据用户的反馈拼接成一个向量,这些反馈包括有效播放、点赞、关注、分享、下载、观看时长等,最后,将各时间窗口对应的反馈向量和 ID 类特征一起输入到用户侧网络。

(3)端到端的 DNN 模型:
对于 Pointwise 形式,把 user_id、行为序列等都作为原始输入特征,同时,融入 pXtr 特征,使用精排模型来学习最终的组合收益。因为这种方式支持更复杂的特征抽取和网络结构,如 attention 结构,所以模型的表达能力更强。
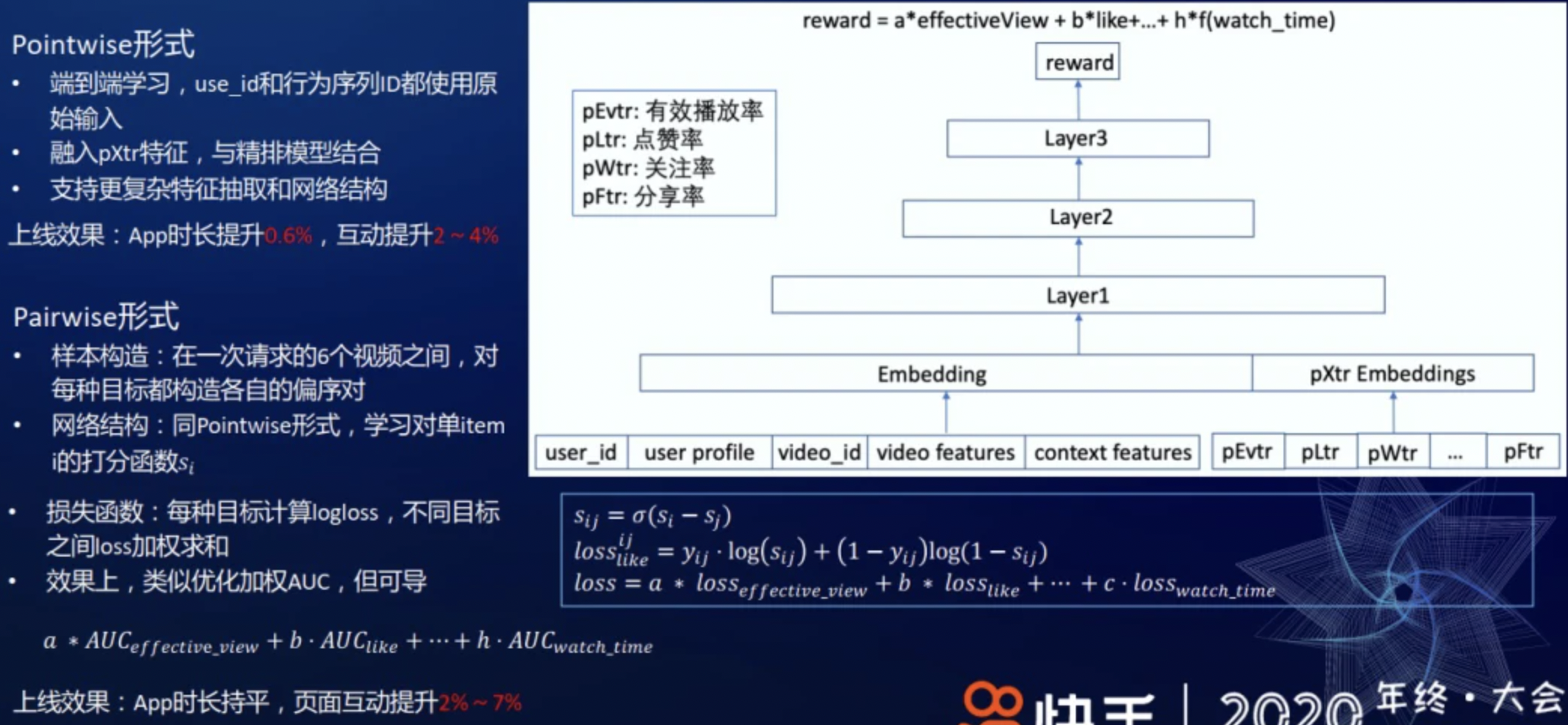
该融合方法存在的问题是不同 Score 之间含义、量级和分布差异较大;显式反馈如点赞率等在不同用户间差异巨大,难以适应统一权重;并且依赖模型预估值绝对大小,预估值分布变化时需重新调节或校准。在此基础上,尝试在各子项分内做 Normalize 的优化,如把子项分转化为序。具体地,把用户的个性化预估点赞率从小到大排序,把每个具体的值映射成它的序,再把序折合成一个分数,不同的序映射到不同的分数,这与 GAUC 目标一致。该做法把不同量纲且分布差异巨大的分数 Normalize 到同样维度,可兼容含义差异巨大的子项分,保证各子项分权重在同一量级调节,并且隐式反馈的预估分在不同用户上做到了某种自适应调节。同时,这种序和 AUC 的预估值也是一致的,能很好地和线上模型的效果保持一致性。通过以上的方式把多种不同的打分策略融合在一起,适用于快手线上复杂的业务场景。
(4)在线自动调参

上述 Ensemble Sort 里的线性加权系数主要依赖手动调参,优点是简单轻量且可解释性好,缺点是效率低且依赖工程师经验,解决上述问题的一种方式是 Learn2Rank,即用一个模型离线学习各反馈的组合权重。
-
优点是这是一种 off-policy 方法;数据利用率高,100%的样本都可以被使用,模型的自由度和复杂度较高,比如 Learn2Rank 可以容纳 item embedding,并使用稀疏特征,可训练千亿规模的参数。
-
缺点是优化的离线 AUC 无法直接对标业务指标。因为这个过程做了很多的简化,比如从精排到最终吐给用户,中间还有重排、多样性的影响,还有后面的一些和其他如商业化/运营流量的融合等等,所以该方式难以考虑到线上复杂多模块间的完整影响。此外,线下训练数据和线上也存在不一致性。
上述离线方法都有具有和 Learn2Rank 类似的缺陷,为了解决该问题,我们这边开发了在线自动调参框架。自动在线调参的工作机制如上图左下角所示,即在基线附近探索生成 N 组参数,传给推荐系统后获得这 N 组参数对应的展现给用户的差异化排序结果,从而获得用户不同反馈,收集这些反馈日志并做 Reward 统计,最终输给 CEM/ES/BayesOpt 等调参算法产生下一组更好的参数。经过不停迭代,参数即可逐渐向一个多目标协调最优的方向前进。
调参算法主要开发了离线优化使用的各种超参优方法,包括交叉熵算法(Cross-Entropy Method,CEM)、进化策略(Evolutionary Strategy,ES)、贝叶斯优化(Bayes Optimization)、高斯过程回归(Gaussian-Process Regression,GPR)。这里,主要介绍下实践中常用的 CEM 算法,右侧图例给出了该算法的工作流程:从参数初始的高斯分布出发,一般均值选为线上基线参数,方差手动设置,然后根据该高斯分布随机生成 N 组参数,每组参数都做在线 AB 测试、收集反馈、计算 Reward,选择 Reward 最好的 TopK 组参数,并统计着 K 组参数的均值和方差,并对方差做微小扰动(防止过早陷入局部最优)后得到新的高斯分布,根据新高斯分布继续采样获取新样本...经过若干次迭代,最终会收敛到一组较好的参数。该算法的优点是简洁、高效,超参很少;0 阶方法,TopK 选取只依赖 Reward 的序,不需要对 Reward 的数值大小进行建模,对噪声更近鲁棒;参数通过高斯分布扰动探索,偏离基线越多的参数选中的概率越小,线上指标相对平稳。
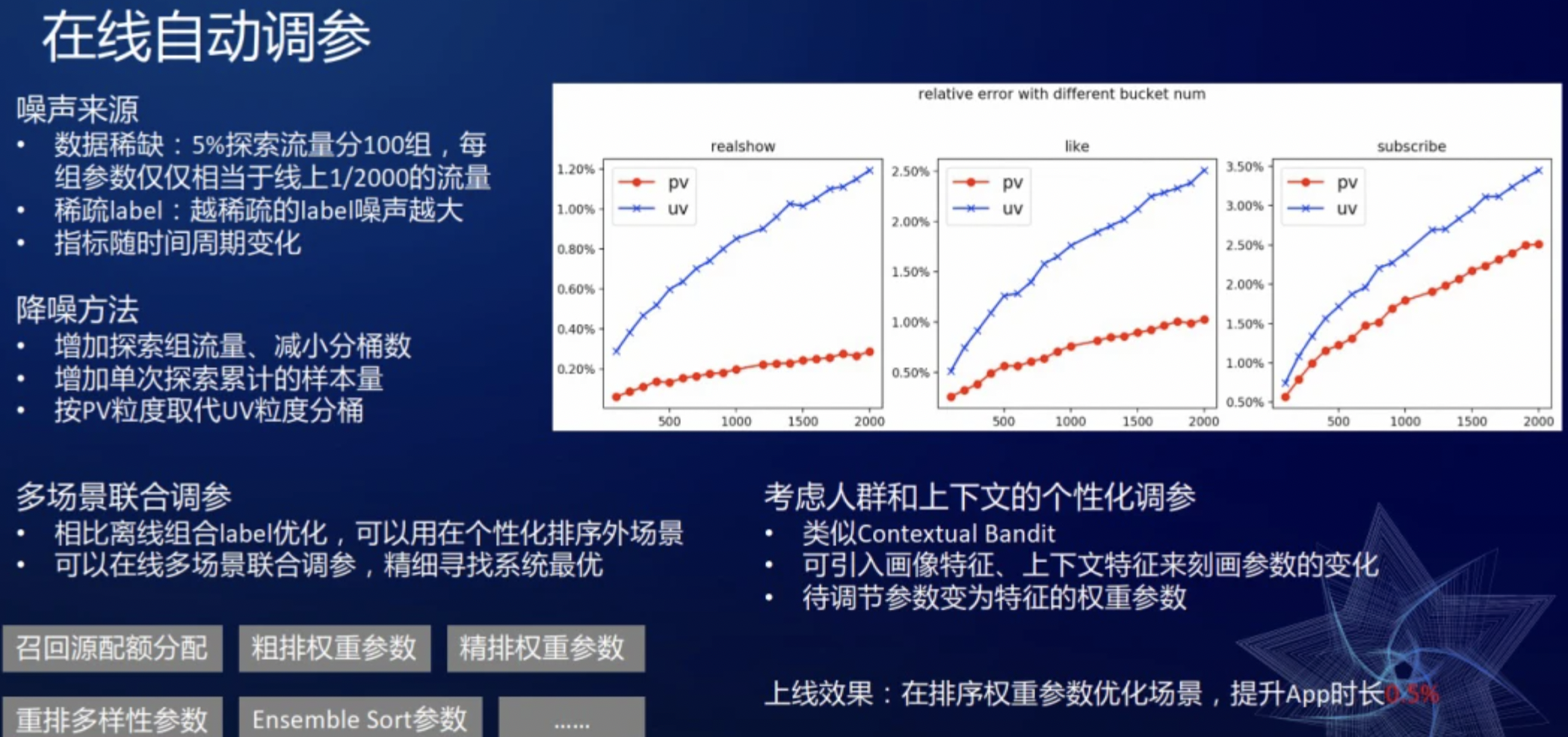
在实践中,困扰比较多的是噪声。噪声主要来源是数据稀缺和稀疏 label。比如把 5%的流量分 100 组,相当于十万量级的用户几小时的样本量只能生成一个样本点,并且每组参数只相当于线下 1/2000 的流量,这么小的流量做 AB 测试方差会比较大。上图右侧展示了“随着分组数的增加,不同互动类型的波动”,如播放量波动范围 0.4~1.2%,点赞量的波动会更大一些,因为稀数 label 的波动性可能会更大一些。相应地,降噪方法包括:增加探索组的流量、减少分桶数;增加每次累计的样本量,如从两个小时的累计样本量增加到四个小时的累计样本量;用 PV 粒度替换 UV 粒度分桶,因为一个组 UV 可能就几百万,而每个用户每天会有几十刷,使用 PV 样本量就翻很多倍,所以使用 PV 的方差也更小,图中红线给出了按 PV 采样分桶得到的方差,可以看到,方差都更小些。
除个性化排序场景外,我们也在其余更多场景尝试了超参优化方法,比如,召回源配额分配时,主要调控召回源的数量多少、耗时及总收益的最大化;粗排和精排的排序权重参数;Ensemble Sort 的排序权重;重排的多样性权重参数等。在线多场景联合调参,精细寻找系统最优。此外,考虑人群和上下文的个性化和场景化调参,比如通过一个广义线性模型来根据特征计算参数,类似 Contextual Bandit;引入用户画像特征,比如年龄、年龄段、性别;还有上下文特征,比如一天的上午、中午、晚上 来刻画这些参数的变化。这样,需要调节的参数 就从个性化的权重参数 变成了各个特征的权重。
3、重排
介绍完精排,接下来介绍重排序相关部分。相比精排,重排序最大的特点是需要考虑视频之间彼此的影响,即用户可能因为看了 A 视频对 B 视频可能会促进、也可能会有损,比如看了一个风景的视频,紧接着再看一个风景的视频,它的效用就会降低,而如果看一个差异较大的互补的视频,有可能会提高它的效用。
(1)首先,采用类似 Learn2Rank 的学习方案:对精排层返回的 Top6 视频做 Rerank,使用 transformer 进行建模,刻画视频间相互影响:把 6 个视频做特征抽取后,经过 transformer 层的 encoder 得到 embedding 表示,再经过评估层得到输出,损失函数采用 Weighted Logloss。实践中,前序视频对后序视频的播放和效用有影响,比如在上下滑场景,看了前面的视频可能会对后面的视频有影响,但看了后面的视频不会对前面的视频有影响。但作为一个组合收益,需要前后组合决定总收益。比如把五个爱看的视频和五个不太爱看的视频放在一起,如果前五个全是爱看的,而后面五个全是不爱看的,可能用户翻到第七个视频时,就会退出;但如果把爱看和不爱看的夹杂着放,有可能用户能看完十个视频,可能还会从之前五个不爱看的视频里探索出一个新的兴趣,即这种组合的收益会有更大的提升空间。对于离线效果评估,我们对比统计了“做 transformer 后推荐结果的 AUC”和“DNN 基线,即精排模型给出排序结果的 AUC”,从上图左下角表格可见:在不同位次上,从第 1 位到第 6 位,随着位次增加 AUC 逐渐提升。即考虑前序视频对后序视频的影响,能改善后序视频的推荐体验。
(2)强化学习

具体做法是从精排后的 Top50 里选出 Top10,通过序列决策的过程,从前向后依次贪心的选择动作概率最大的视频。比如上图左上角表示的过程:有 4 个候选集 a、b、c 和 d,先选出排序分最大的 b,把它作为一个上下文特征;然后选出第二大的 c,然后把选出的 b 和 c 作为上下文特征;再选第三个视频......选择视频时,reward 会兼容相关性、多样性及一些约束项。根据序列决策的思想,上图右侧给了一个 LSTM 网络结构来建模前序视频对后序视频的影响。DNN 网络同时输出 Policy 和状态值函数 Value,这里 Policy 是通过 Softmax 计算选择每个候选视频(Action)的概率后,选择概率最大的视频。Policy 具体实现上,在挑选每个位置的视频时,把前序视频的作用编码成一个 embedding 向量,对候选集的每个视频做预估和 softmax 变换,最后会选择最大的。
参考文献:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号