推荐系统(9)—— 推荐系统重排序-注意力模型小结
1、阿里巴巴PRM模型
推荐系统的架构大致分为如下几个模块:召回、粗排、精排、重排,那么为什么要引入重排模块呢。在精排阶段,我们希望得到的是一个候选排序队列的全局最优解,但是实际上,通常在精排阶段,我们精排模型是针对用户和每一个候选广告(商品)输出一个分值;而每个候选之间也会相互影响。例如在360搜索广告的场景下,这些候选广告之间的广告样式会互相影响,从而影响最终的排序结果(一些图片类型的广告的点击率通常要比纯文字链广告的点击率要高),所以在360搜索广告的场景下,重排序模块主要在考虑同屏展现广告样式相关的一些信息,利用这些信息对精排候选广告队列进行一个重新的排序。
排序是推荐系统的一个核心问题,目的是给用户一个“排好序的”item list。通常这个ranking function是从labeled dataset里学到的,通过优化全局表现。这个function对每个item给一个得分。但是这个function可能是次优的,因为它是对每个item“独立”应用的,而且没有显式地考虑item之间的关系,也没有考虑用户偏好的不同。于是这篇文章就提出了PRM。这个reranking模型可以接在任何排序模型后面。它直接优化整个的推荐列表,通过“使用transformer结构来encode列表中的item信息”。其中,这个transformer用了self-attention机制,它直接对任意pair的item间的联系建了模。通过加入一个预训练好的学习用户偏好的embedding,效果还会进一步提升。
Transformer替换RNN的优势也是较为普遍认知的,1.工程上并行化更容易;2.算法上对于远距离的item关系刻画更好。由于业务场景的不同,DLMC强调的是不同query下的特征分布是不同的,比如搜索“老友记”,那相关性相比于多样性就更重要,本文强调不同用户的意图不同对推荐list的影响,比如一个没有明显购买意图的用户,推荐的多样性就变得很重要。
(1)Input Layer
Input Layer的作用比较好理解,就是对精排阶段的候选广告列表进行一个Embedding表征,得到Embedding向量之后喂给后续的Encoding Layer。Input Layer的原始输入是精排广告序列的原始特征矩阵X。在此基础上,主要引入Personalized Vector(PV)和Position Embedding(PE)。如果只将候选广告的原始特征矩阵X喂给Encoding Layer,则模型只会获取到候选商品之间的交互信息,为了引入商品-用户之间的交互信息,则引入了Personalized Vector;Position Embedding则主要是引入精排阶段ranking order的相关信息。所以最后最终的Embedding矩阵如下

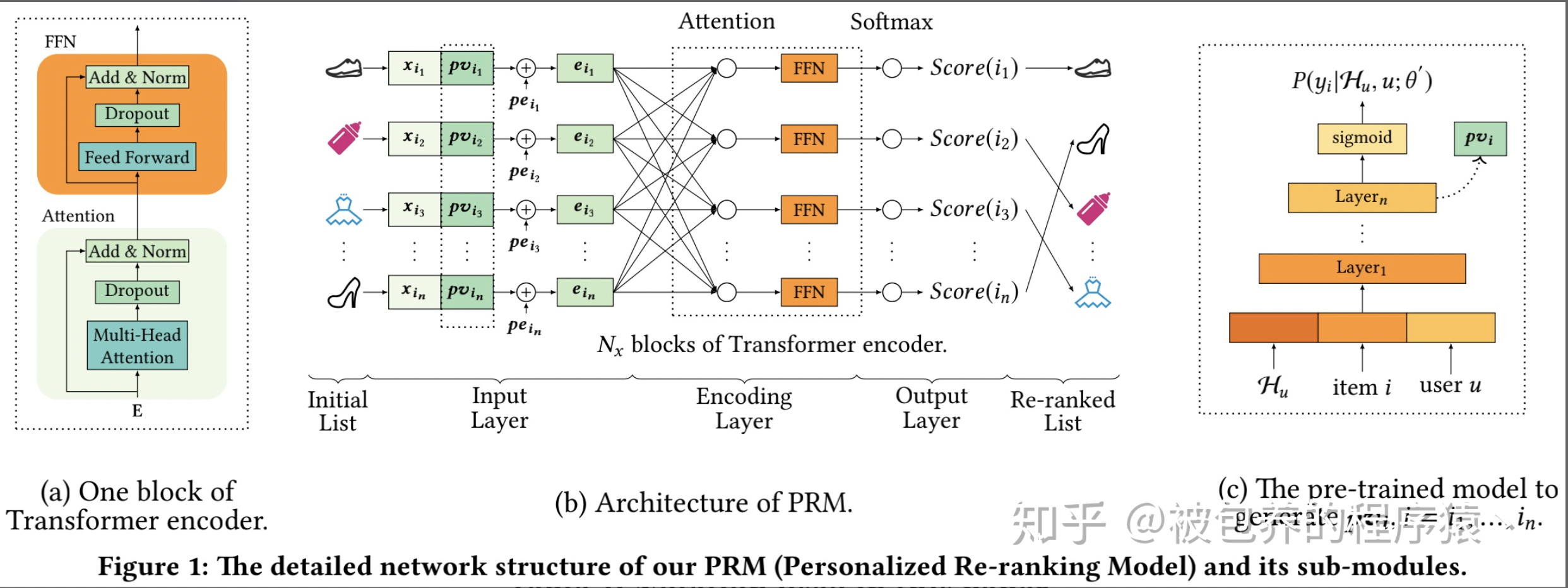
那么如何对PV进行建模呢,这里文章给出了两个办法,一种是将PV融入到PRM模型中做端到端的训练,另外一种是采用一个额外的模型进行预训练得到PV的Embedding Vector;论文采用第二种方式,可以理解为第一中方法只能挖掘用户-精排候选item之间的交互信息,但是实际上我们这里需要的是用户更加泛化通用的embedding表征,所以利用一个单独的预训练的模型(也可以用简化版的精排模型),但是我觉得采用端到端的训练方式和预训练的方式两者之间的差距还需要进一步评估,具体两者差距多少持保留态度。具体预训练模型的结构如图1右侧部分所示,就是一个简单的MLP,这里也就不做过多介绍了,值得一提的是,为了更好的表征用户个性化的信息,在这个预训练部分引入了一些用户历史行为特征、用户基础特征(年龄、性别)、item特征这三类。
这里为什么要用self-attention这种结构呢,因为在重排序阶段需要考虑的是候选广告之间的相互影响(item之间的交互信息),所以self-attention可以捕捉到精排序列中两两item之间的信息。本身这块Encoding Layer的结构就是比较简单的。同时文章也指出引入多层的Encoding Layer可以进一步捕捉到高阶的交叉信息(也就是Encoding Layer可以叠加多层)。

2、总结下DIN、DIEN、DSIN
优化流程:
- 传统深度学习在推荐就是稀疏到embedding编码,变成稠密向量,喂给NN
- DIN引入attention机制,捕获候选商品和用户浏览过的商品之间的关系(兴趣)
- DIEN在DIN基础上引入序列概念,将用户历史行为序列纳入到网络内
- DSIN将行为序列划分为session,更符合RNN概念

这样做有什么问题?
-
一个明显的问题是不同用户的行为序列长度是不同的,fixed-length信息表达不全面
-
用户最终的行为只和历史行为中的部分有关,因此对历史序列中商品相关度应有区分
2、DIN
深度学习在CTR预估领域已经有了广泛的应用,常见的算法比如Wide&Deep,DeepFM等。这些方法一般的思路是:通过Embedding层,将高维离散特征转换为固定长度的连续特征,然后通过多个全联接层,最后通过一个sigmoid函数转化为0-1值,代表点击的概率。即Sparse Features -> Embedding Vector -> MLPs -> Sigmoid -> Output。这种方法的优点在于:通过神经网络可以拟合高阶的非线性关系,同时减少了人工特征的工作量。
DIN在有限的纬度表示用户的差异化兴趣,引入局部激活单元,对特定的ad自适应学习用户兴趣表示向量。即同一用户在候选ad不同时,embedding向量不同。使用attention机制捕获ad和用户行为序列商品之间的关。
- Diversity:用户在访问电商网站时会对多种商品都感兴趣。也就是用户的兴趣非常的广泛。
- Local Activation:用户是否会点击推荐给他的商品,仅仅取决于历史行为数据中的一小部分,而不是全部。针对Diversity:
解决方式:1)针对用户广泛的兴趣,DIN用an interest distribution去表示。2)针对Local Activation:DIN借鉴机器翻译中的Attention机制,设计了一种attention-like network structure, 针对当前候选Ad,去局部的激活(Local Activate)相关的历史兴趣信息。和当前候选Ad相关性越高的历史行为,会获得更高的attention score,从而会主导这一次预测。

Base Model有一个很大的问题,它对用户的历史行为是同等对待的,没有做任何处理,这显然是不合理的。一个很显然的例子,离现在越近的行为,越能反映你当前的兴趣。因此,对用户历史行为基于Attention机制进行一个加权。Attention机制简单的理解就是,针对不同的广告,用户历史行为与该广告的权重是不同的。假设用户有ABC三个历史行为,对于广告D,那么ABC的权重可能是0.8、0.1、0.1;对于广告E,那么ABC的权重可能是0.3、0.6、0.1。这里的权重,就是Attention机制即上图中的Activation Unit所需要学习的。
将candidate与点击序列中的每个商品发生交互来计算attention分数。具体计算方法,输入包括商品和candidate的embedding向量,以及两者的外积。对于不同的candidate,得到的用户表示向量也不同,具有更大的灵活性。

几个创新点:
-
评价指标GAUC,不仅将每个用户的AUC分开计算,同时根据用户的展示数或者点击数来对每个用户的AUC进行加权处理。进一步消除了用户偏差对模型的影响。通过实验证明,GAUC确实是一个更加合理的评价指标。
-
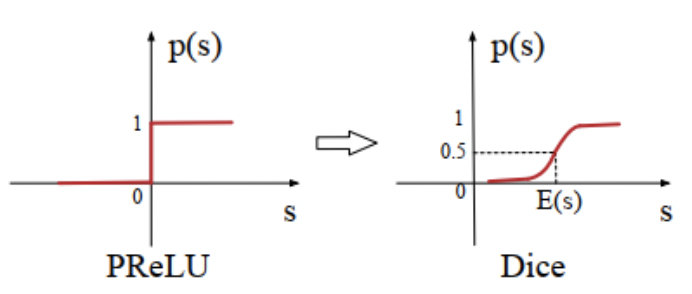
Dice激活函数,尽管对Relu进行了修正得到了PRelu,但是仍然有一个问题,即我们认为分割点都是0,但实际上,分割点应该由数据决定,因此文中提出了Dice激活函数。
-
自适应正则 Adaptive Regularization,CTR中输入稀疏而且维度高,通常的做法是加入L1、L2、Dropout等防止过拟合。但是论文中尝试后效果都不是很好。用户数据符合长尾定律long-tail law,也就是说很多的feature id只出现了几次,而一小部分feature id出现很多次。这在训练过程中增加了很多噪声,并且加重了过拟合。对于这个问题一个简单的处理办法就是:直接去掉出现次数比较少的feature id。但是这样就人为的丢掉了一些信息,导致模型更加容易过拟合,同时阈值的设定作为一个新的超参数,也是需要大量的实验来选择的。
因此,阿里提出了自适应正则的做法,即:
1.针对feature id出现的频率,来自适应的调整他们正则化的强度;
2.对于出现频率高的,给与较小的正则化强度;
3.对于出现频率低的,给予较大的正则化强度。![]()
![]()
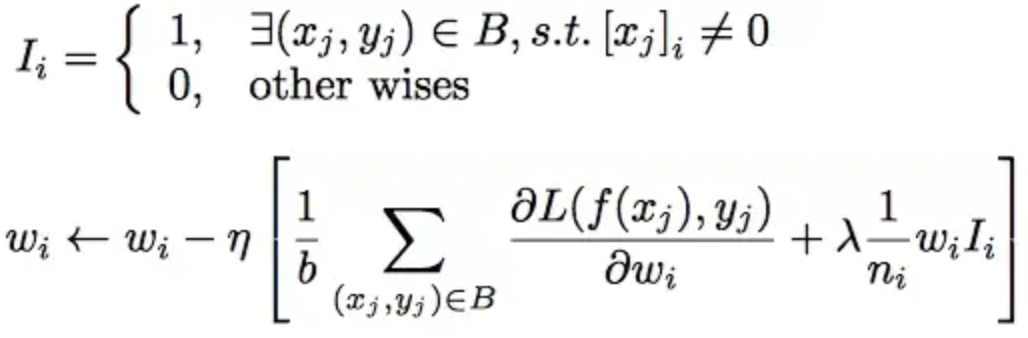
一般来说,做attention的时候,需要对所有的分数通过softmax做归一化,这样做有两个好处,一是保证权重非负,二是保证权重之和为1。但是在DIN的论文中强调,不对点击序列的attention分数做归一化,直接将分数与对应商品的embedding向量做加权和,目的在于保留用户的兴趣强度。例如,用户的点击序列中90%是衣服,10%是电子产品,有一件T恤和一部手机需要预测CTR,那么T恤会激活大部分的用户行为,使得根据T恤计算出来的用户行为向量在数值上更大,相对手机而言。
3、DIEN
DIN在捕获顺序行为之间的依赖关系方面很弱,以前的方法不能挖掘行为背后真正的用户兴趣。此外,用户的兴趣是不断发展的,捕捉兴趣之间的动态关系对于兴趣的表达是非常重要的。用户兴趣多样性,导致兴趣漂移(interest drifting phenomenon):在相邻的访问中,用户的意图可能非常不同,用户当前行为可以依赖很久之前的用户行为。同时,一个用户对不同目标项的点击行为受不同兴趣部分的影响。dien主要在din基础上优化兴趣演化层,在注意力机制新颖嵌入序列机制中,使用兴趣状态和目标项计算相关性,AUGRU强化了相对兴趣对兴趣演化的影响,弱化了兴趣漂移导致的非相对兴趣效应,在DIN基础上考虑序列信息。
创新点:1)从显式用户行为中提取潜在的兴趣;2)对兴趣演化过程建模;
- 由于兴趣的多样性,兴趣可以漂移。兴趣漂移对行为的影响是用户可能在一段时间内对各种书籍感兴趣,而在另一段时间内需要衣服;
- 尽管兴趣可能相互影响,但每个兴趣都有自己的发展过程,例如书籍和衣服的发展过程几乎是独立的。我们只关注与目标项目相关的演化过程;
改进点:
- 设计了兴趣抽取层,并通过计算一个辅助loss,来提升兴趣表达的准确性;
- 设计了兴趣进化层,来更加准确的表达用户兴趣的动态变化性;
dien首先通过embedding层对所有类别的特征进行转换。其次,DIEN通过两个步骤来捕捉兴趣进化:1)兴趣提取层根据行为序列提取兴趣序列;2)兴趣进化层对与目标项目相关的兴趣进化过程进行建模。然后将最终兴趣的表示和embedding向量ad、用户画像、上下文连接起来。将该向量输入MLP进行最终预测。
相对于base模型和DIN,只对用户行为序列User behavior sequence的处理做了调整。这里包含了3个部分,最底层是Behavior Layer,用于将用户浏览过的商品转换成对应的embedding,并且按照浏览时间做排序,中间层是兴趣提取层Interest Extractor Layer,最上层是兴趣发展层Interest Evolving Layer,我们重点介绍上面两个Layer。

兴趣提取层引入了一个有监督学习,强行将RNN输出隐层与商品embedding发生交互,输入是按照时间步排列的商品embedding向量,假设第t个时间步输入e(t),GRU输出隐单元h(t),令下一个时间步的输入向量e(t+1)作为正样本,随机采样负样本 ,且
,h(t)与正负样本向量分别做内积,定义辅助loss如图5所示。
是CTR任务的loss函数,将CTR的loss和辅助loss相加作为整个网络的loss进行优化。
是超参,平衡两个loss的权重。辅助loss有几个好处,当GRU处理较长序列的时候有助于降低反向传播的难度,对于商品embedding的学习也有助益。再用一句话总结下,兴趣提取层的作用是挖掘行为序列中商品之间的联系,对用户的兴趣进行提取和表达。

有了用户的兴趣表示,兴趣发展层的作用就是捕获与candidate相关的兴趣发展模式,如图4中红色区域所示,这里使用了第2个GRU。将candidate的embedding向量与第1个GRU的输出隐向量发生交互,生成attention分数,具体计算公式如图7所示。其中, 是隐向量,
是candidate的表示向量,W是需要训练的参数矩阵。需要注意的是,与DIN不同,这里的attention分数采用softmax做了归一化。 文中将attention分数与update gate相乘,替换原始的update gate,称为AUGRU,其中A指的是Attention,U指的是Update gate。
提取层利用辅助损失提取每个兴趣状态。在兴趣演化层,AUGRU对与目标项目相关的兴趣演化过程进行建模。最终兴趣状态
与剩余特征的嵌入向量串联起来,输入MLR进行最终的CTR预测。
我们看一下DIEN这个结构有什么问题。GRU是串行计算结构,要按照时间步一步一步进行计算。DIEN有两个GRU,第2个GRU还要基于第1个GRU的结果来做attention,所以第2个GRU必须要等到第1个GRU全部计算完成才能开始计算,两个GRU单元无法并行计算,所以可能存在时延大的问题,序列越长,时延可能就越长。文中介绍说工业场景输入的序列长度是50,累积两个GRU的时延,相当于序列长度为100的时延。最后关于DIEN再提出我的一点想法。兴趣提取层是否是必要的,是否可以砍掉?我自己的感觉是可以砍掉,直接将商品embedding输入给兴趣发展层,通过兴趣发展层来提取与candidate相关的兴趣发展模式,而且兴趣发展层本身也是一个GRU,也可以直接挖掘商品之间依赖关系。不过具体效果如何,还是需要通过试验来验证。
4、DSIN
用户行为在每个会话中都是高度同构的,但跨会话是异构的。DSIN进一步做出优化,在每个会话中的行为是相近的,而在不同会话之间差别是很大的。dsin指出用户同一session下浏览商品的相似性和不同session浏览商品差异性,在self-attention做local activation又加入BI-LSTM做改进。
改进点:
- 将用户的连续行为自然地划分为会话,然后利用带有偏置编码的self attention网络对每个会话进行建模;
- 应用BI-LSTM捕捉用户不同历史会话兴趣的交互和演变;
- 设计了一个局部的活动单元,将它们与目标项聚合起来,形成行为序列的最终表示形式;

- 会话划分层:用户情景的分割存在于时间间隔大于30分钟的相邻行为之间。
-
会话兴趣提取层:同一会话中的用户行为密切相关。此外,用户在会话中的随意行为也使得原有会话展示发生偏差。捕捉同一会话中行为之间的内在关系并减少这些不相关行为的影响,paper在每个会话中都采用了多头注意机制并对自我注意机制做了一些改进。
-
会话兴趣交互层:用户会话兴趣与上下文兴趣具有顺序关系,对动态演变进行建模可以丰富会话兴趣的表示。
-
会话兴趣激活层:与目标项关联更密切的用户会话兴趣对用户是否单击目标项影响更大,用户会话兴趣的权重需要重新分配到目标项。注意机制在源和目标之间进行软对齐,是一种有效的权重分配机制。

比起DIEN中对User Behaviors 部分分了三层去处理,在DSIN中有四层!第一层是Session Division Layer,第二层是Session Interest Extractor Layer,第三层是Session Interest Interacting Layer,第四层是Session Interest Activating Layer。先来说Session是什么,我们注意到用户的兴趣很广泛,但在一个较短的时间内还是比较专注的,兴趣会聚焦于一点,我们就把这较短的时间段称为一个Session,比起DIN和DIEN把行为序列全打包到一起,在DSIN中把行为序列划成一个个Session再分别处理会更符合我们的直觉。
- 第一层的Session Division Layer就是把行为序列划成一个个Session,通常把间隔30分钟以上的不同行为item划归成不同的Session,
- 第二层的Session Interest Extractor Layer就是提取出每个Session的兴趣,毕竟我们刚才说了在每个Session中用户的兴趣通常会聚焦于一点。每个Session中兴趣聚焦于一点,不同的Session之间兴趣聚焦于不同的点上,但如同DIEN所说,兴趣的转变总有个较为自然的转变过程,
- 第三层的Session Interest Interacting Layer就是捕捉Session间兴趣演化的过程。一如DIN,DIEN中所说,用户的兴趣总是广泛的,我们要推荐给用户的item总是只能对应用户的一部分兴趣,所以需要使用attention mechanism 提取出用户兴趣中与要推荐的item相关联的部分,
- 第四层即是Session Interest Activating Layer。对用户行为特征处理完后再与其它平平无奇的特征拼接完后就可以送入全链接网络进行训练了。那么总的网络结构就是这样,下面我们一层一层来细说。
参考文献:https://www.cnblogs.com/gongyanzh/p/12133984.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号