推荐系统(8)—— 多目标优化应用总结_1
为什么要做多目标优化?
做多目标优化一般由业务驱动,比如电商场景,肯定是希望推出去的东西用户既点击又购买并且下次还来,如果能够点赞收藏分享那就更好了,这里面涉及的优化目标就多了,比如点击率、转化率、收藏等等,在信息流场景也是一样的。所以多目标的优化是跟业务强相关的,想做一个用户喜欢、内容创作者愿意创作的优质内容平台,多目标优化是一个值得持续投入的方向。
qq 看点多目标实践
1、多目标业务应用-示例1
(1)按照参数共享的方式区分:


上图是单层多目标联合建模,下图是多层多目标联合建模。先看单层的多目标联合建模结构,可以看出从左至右各个结构的主要区别在于底层参数共享的方式,多层多目标联合建模只是在单层的基础上将共享模块从深度方向进行扩展而已。多层多目标联合建模可以根据自身业务实际情况适当采用,从个人的经验角度来说,在推荐系统中,NN网络宽比深更有效,复杂的网络交叉不见得有效。但值得一提的是,上面的PLE模型来自腾讯PCG团队。
- 1) Hard Parameter Sharing,不同的任务底层的模块是共享的,然后共享层的输出分别输入到不同任务的独有模块中,构成独立多塔结构。当两个任务相关性较高时,用这种结构往往可以取得不错的效果,但任务相关性不高时,会存在负迁移现象,导致效果不理想。
- 2) Asymmetry Sharing(不对称共享),可以看到,这种结构的MTL,不同任务的底层模块有各自对应的输出,但其中部分任务的输出会被其他任务所使用,而部分任务则使用自己独有的输出。哪部分任务使用其他任务的输出,则需要人为指定。
- 3) Customized Sharing(自定义共享),不同任务的底层模块不仅有各自独立的输出,还有共享的输出。2和3这两种结构同样是论文提出的,但不会过多的介绍。
- 4) MMoE,Google提出的多目标模型,底层包含多个Expert,引进与任务个数相同的门控网络(gating network),对多个Expert进行加权加和输出,相当于使用gating network对Expert进行过滤然后输入到各自对应的任务中。
- 5) CGC(Customized Gate Control),其实就是在Customized Sharing这种结构上引进gating network。
图中的共享模块,一般都是指NN模块,其实最底层的embedding对于各个任务是完全共享的。在embedding和NN之间,完全可以不共享NN,让各个任务直接基于embedding独立训练,效果一般会更好,考虑到embedding层维度较高,这样处理参数量更大,训练和预估性能要求更高。当两个任务相关性较高时,用这种结构一般都可以取得不错的效果,但任务相关性不高时,可能会存在负迁移现象,这时候引入共享NN模块和gating network就有用了。各个任务独立的塔用于建模任务独立的信息,任务间引入共享NN,用于建模任务间的联系,各个任务都会影响底层embedding的更新,可以通过gating network来控制各个任务对底层参数的影响程度。
(2)按照样本空间不一致的处理方式来分:
多目标联合建模主要包括目标转换和梯度block两种。样本空间不一致指不同任务使用的训练样本不一样,但是却需要在同一个模型当中建模,比如训练点击模型使用全量的有效曝光样本,而训练时长模型却只需要点击样本。
1)目标转换方法以阿里巴巴提出的ESMM模型为典型代表。CTR任务使用有效曝光样本训练,而CVR任务使用点击样本训练,通过将CVR和CTR任务的输出相乘得到CTCVR这个辅助任务,此时CTCVR和CTR两个任务就可以使用统一的点击样本进行训练了。

2)梯度block对样本空间不一致问题的处理方式为:对不参与特定目标训练的样本的反传梯度置0,比如在点击时长两目标任务中,时长任务应该只使用点击样本训练的,但是输入为全量样本,所以在时长任务中,对于未点击样本,将其反传梯度置0,相当于这部分样本不参与梯度修正,同时时长任务在做Batch内的梯度平均的时候除以点击样本数而不是batch_size。
(3)模型迭代思路,部分全量多目标模型及背后原因
我们线上的多目标模型解决样本空间不一致问题采用的是梯度block的方式,对于时长任务和完播率任务,对其未点击样本反传梯度置0处理。当前已经迭代了五期,从最初的Hard Parameter Sharing结构,到引入Gating network,然后是引入共享NN模型,整体收益, pv 2.0+%,时长 3+%,节省机器400 +台, 并迁移模型至视频、小说等多业务。
- 一期:点击、时长、完播率三塔三目标模型,共享embedding,样本空间不一致通过梯度加权处理
- 二期:各任务学习率差异化调优
- 三期:完播率任务损失函数mse至logloss升级
- 四期:自适应加权多目标模型,引入MMOE模型的gating network
- 五期:CGC多目标模型,多任务间引入共享模块
1)多目标一期模型结构如下,共享embedding,点击、时长、完播率任务独立三塔结构。

2)二期通过对三个任务学习率进行调整,使点击任务学习率更高,时长和完播率任务相对较低,调整学习率相当于调整各任务loss的比例,直接影响各任务对embedding更新的作用程度,因为三个任务NN部分是相互独立的,所以调整学习率不会相互影响各自的NN网络。为什么要调大点击模型的学习率呢?即,为什么要增大点击模型在embedding更新中的影响力呢?因为点击模型的EMB共享可以弥补时长和完播率模型未能学习未点击样本造成的训练和预估样本分布偏差问题,因为必定会给时长和完播率任务带来增益,但是时长和完播率模型的更新却给点击率模型的样本造成了一定的扰动,相当于点击样本被多次训练了,从而造成点击模型点击样本和未点击样本的分布差异变大。通过增大点击率的学习率,相当于给点击模型加权了,这样可以减小由于时长和完播率更新造成的点击样本和未点击样本之间的差距
3)三期就调整了完播率任务的损失函数,使用logloss替换了原来的mse。Logloss也可以用于回归任务的,千万不要定势思维,觉得回归任务就只能使用mse,二分类任务就只能使用logloss,不管是分类任务还是回归任务,使用任何loss都可以,只要这个loss能够衡量预估和真实目标的差距,并且能够在梯度更新的过程当中顺畅的后向传播就行,因为我们的目标只是通过后向传播更新参数使得差距缩小罢了。但是提醒一下,回归任务一般是使用mse, 分类任务一般使用logloss, sigmoid输出结果如果接mse,那么后向传播的时候就不会那么顺畅,容易梯度消失,自己可以梯度推导看看。完播率任务使用logloss的原因为,完播率的label分布接近U字形,即接近0和1的样本比较多,就是说用户要么点了一下就退出了,要么就看完了,大部分样本符合这个行为模式。Logloss天然适合拟合这种数据分布,主要是离散点的概率分布,比如二分类,要么0要么1,logloss就可以方便的拟合01的概率。
完播率的logloss升级,−(ylog(p)+(1−y)log(1−p)),公式里用的y是真实值吗?比如完播率0.2用的就是0.2。
4)四期引入了MMOE当中的gating network,模型结构如下,其实就是相当于将MMOE当中的Expert网络去掉了,同时,gating network网络的输出通过sigmoid转换为0~1的概率值,而不是通过原论文当中使用softmax,输出任务间归一化后的概率值。使用sigmoid的原因是,softmax容易产生polarization issue(极化现象),就是部分任务网络在训练一段时间后出现梯度消失的现象,因为softmax会放大不同任务间权重差距,造成赢者通吃的局面,而在我们的模型当中,点击任务的影响要比时长和完播率大得多,使得时长和完播率这两个任务权重接近0。原论文解决这个问题是使用的dropout方法,我看了下具体操作还挺复杂的,但是使用sogmoid完全可以避免这个问题,因为各个任务之间的权重完全没必要进行归一化,只需要有相对的大小就行了,但是多个gating network的权重进行相加得到最后的权重的时候需要做一个任务内的归一化,不然容易产生梯度爆炸问题。我们试过直接使用MMOE模型,即在embedding与上层NN之间加入多个Expert专家网络,效果和只使用gating network差不多,但是训练速度和预估性能都会有比较明显的下降,所以最终只使用了gating network。
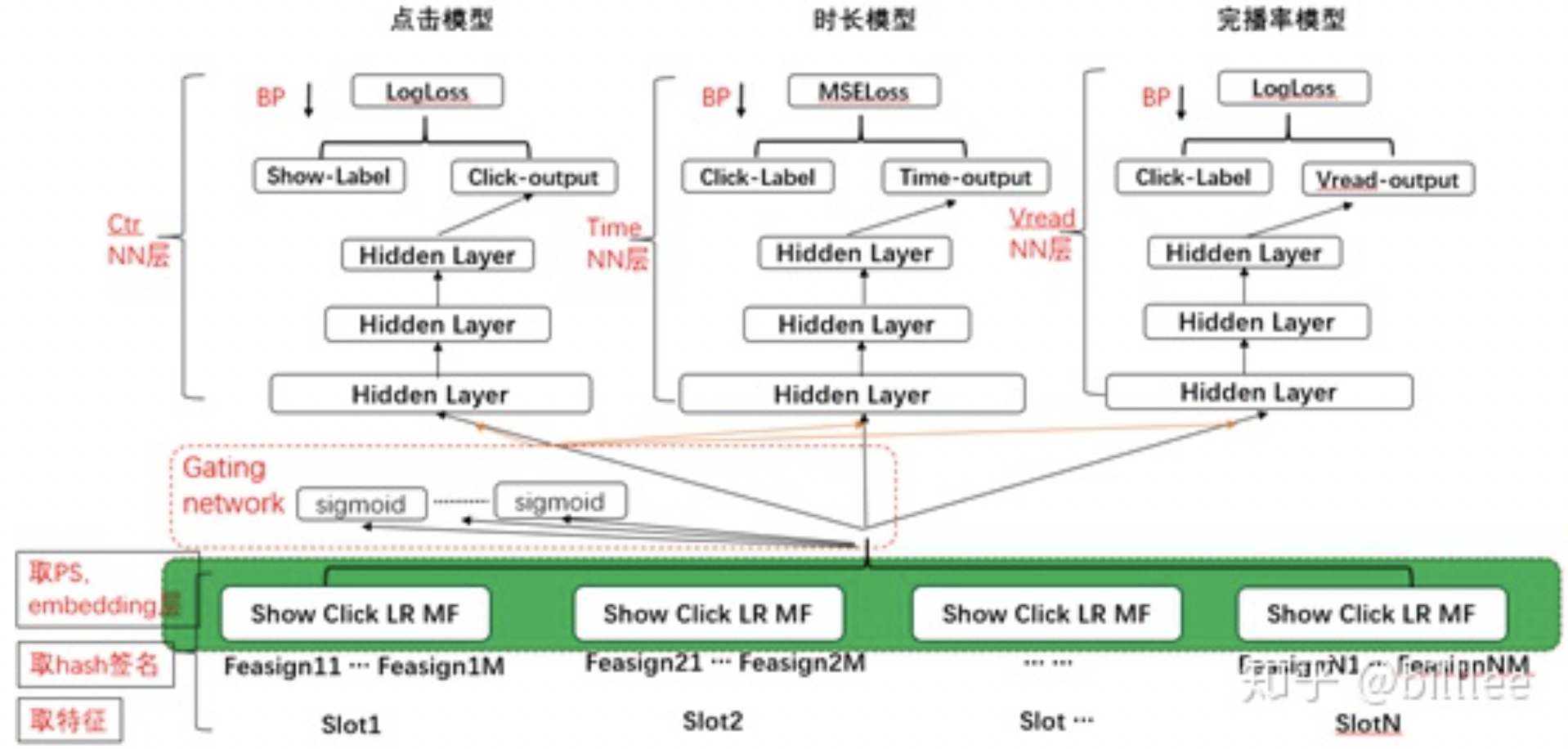
5)五期借鉴CGC网络思想,在各个任务之间引入共享的NN模块,这个思路还是很值得借鉴的,多个任务同时更新embedding,那么上层NN除了抽取各个任务独有信息,包含共享信息也是很正常的,注意这里思路还可以继续拓展,模型结构如下:

6)多目标联合优化讨论
有的同学觉得一个模型最好做一件事情,点击模型就做点击模型的事情,时长模型就做时长模型的事情,这样迭代确实更加纯粹,出了问题也更好排查,迭代更加灵活,比如样本加权这种操作最好别用,这种思路我是部分赞同的,分开迭代,任务更细,各司其职。但是多任务联合训练也有其显著的好处,首先短期来看线上是有明显收益的,不排除未来这种联合训练方式会造成迭代困难,但是单一目标单独迭代就不会遇到同样的迭代瓶颈了吗?比如加特征,其实很难想象在单一模型当中有效的特征会在多目标联合训练当中无效,比如改网络结构,单一模型当中具备的灵活性是完全可以存在于多目标联合模型的。Youtube时长加权排序模型,MMOE模型,ESSM模型,这些模型结构能够成为经典范式,应该也是综合考量过模型单独迭代和联合迭代的利弊吧。说到底,还是需要结合各自业务的实际情况选择迭代方向。不过说实话,个人从业经验确实还不够丰富,也许等到了某一阶段,便能够理解有些同学的坚持了。所以如果有丰富业务经验的同学看到了这里,觉得对于模型的单独迭代还是联合迭代有过来人的理解,希望不吝赐教,跟大家分享一下你的看法。对于下步联合多目标的迭代,当前还有几个Idea,有的已经开始在做了,有的已经规划了,后面如果有机会,会继续跟大家分享。需要指出的是,模型单独迭代中的有效操作大可继续在联合多目标优化中尝试。
参考文献:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号