
机器学习(三十一)— 常见问题笔记(1)
1、Embedding 和 One Hot 编码区别?
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 2)作为监督性学习任务的输入。
- 3)用于可视化不同离散变量之间的关系。
在深度神经网络中你如果直接接入onehot,那么你需要训练的参数维度也是爆炸式增长的,这个在深度模型中是一个困扰。所以在保留相同信息的基础上使用embedding作为输入是一个可靠的选择。
2、GBDT的核心思想?
用加法模拟,更准确的说,是多棵决策树来拟合一个目标函数。每一棵决策树拟合的是之前迭代得到的模型的残差。求解时,对目标函数使用一阶泰勒展开,用梯度下降法训练决策树。XGBoost的核心思想:在GBDT的基础上,目标函数增加了正则化项,并且在求解时做了二阶泰勒展开。
3、为什么很多时候用正太分布来对随机变量建模?
现实世界中很多变量都服从或近似服从正太分布。中心极限定理指出,抽样得到的多个独立同分布的随机变量样本,当样本数趋向于正无穷时,它们的和服从正太分布。
4、说出计算用户之间相似度的三种方式?
(1)Jaccard相似度:杰卡德相似度(Jaccard similarity coefficient),也称为杰卡德指数(Jaccard similarity),是用来衡量两个集合相似度的一种指标。Jaccard相似指数被定义为两个集合交集的元素个数除以并集的元素个数。
(2)余弦相似度:将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并求得夹角之间的余弦值,此余弦值就可以用来表征,这两个向量之间的相似性。夹角越小,余弦值越接近于1,则越相似。
5、实际在使用softmax的过程中有哪些需要注意的呢?

6、为什么归一化能加快梯度下降法求优化速度?
归一化后的数据有助于在求解是缓解求解过程中的参数寻优的动荡,以加快收敛。对于不归一化的收敛,可以发现其参数更新、收敛如左图,归一化后的收敛如右图。可以看到在左边是呈现出之字形的寻优路线,在右边则是呈现较快的梯度下降。
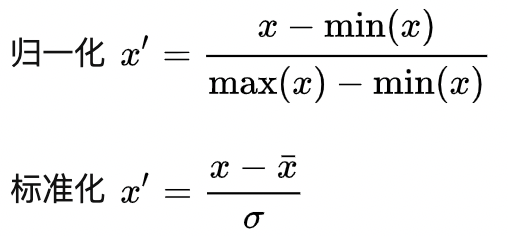
7、AUC为啥对正负样本比例不敏感?
这个问题的本质原因,在于横轴FPR只关注负样本,与正样本无关;纵轴TPR只关注正样本,与负样本无关。所以横纵轴都不受正负样本比例影响,积分当然也不受其影响。
正是因为AUC不敏感,所以我们才要采用AUPRC。作为一个机器学习模型,我们希望它对不平衡数据越不敏感越好;而作为一个评价指标,我们想尽可能地放大模型对于数据不平衡的敏感性,所以希望它对不平衡越敏感越好。
8、广告场景ctr预估为什么要保距?
对于常见的推荐问题而言,并不是太关注模型输出概率的绝对值大小而更关注的相对大小,即排序。
广告等ctr预估模型中,由于最终的排序还要乘以bid,因此对于ctr的准确度要求非常高,总结而言,ctr预估不仅要保序,即正负样本排序好,还需要保距,即pctr之间的比值关系与真实ctr的比值也基本相等,这也是ctr预估中最难的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号