
推荐算法(1)——推荐算法的经典套路
0、参考文献
https://mp.weixin.qq.com/s/XD6qFpt8FdLTy2PcrLiTIA
1、 推荐算法套路
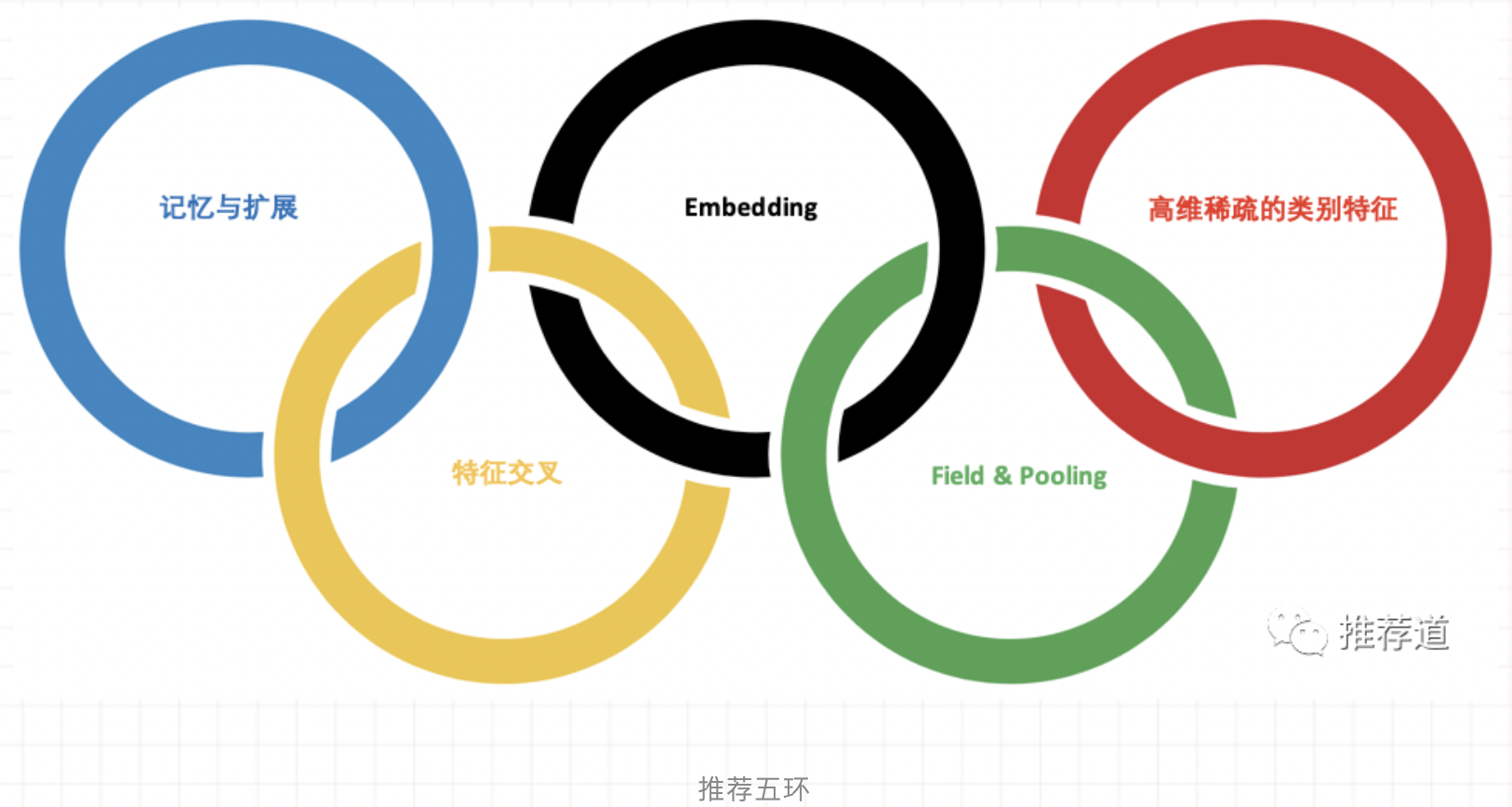
(1)排序模型一般都衍生自Google的Wide & Deep模型,有一个浅层模型(LR或FM)负责记忆,DNN负责扩展
(2)特征一般都采用类别特征。画像、用户历史天然就是高维、稀疏的类别特征。对于实数型特征,比如用户、物料的一些统计指标,在我的实践中,也通过分桶,先离散化成类别特征,再接入模型
(3)每个类别特征经过Embedding变成一个向量,以扩展其内涵。
(4)属于一个Field的各Feature Embedding需要通过Pooling压缩成一个向量,以减少DNN的规模
(5)多个Field Embedding拼接在一起,喂入DNN
(6)DNN通过多层Fully Connection Layer (FC)完成特征之间的高阶交叉,增强模型的扩展能力。
2、关键点
- 记忆与扩展是推荐算法两大经典、永恒的主题。如何实现扩展?靠的是Embedding和特征之间的交叉。
- Embedding化“精确匹配”为“模糊查找“,大大提升了推荐算法的扩展能力,是”深度学习应用于推荐系统“的基石。
- 高维、稀疏的类别特征是推荐系统中的一等公民。为了弥补单个类别特征表达能力弱的问题,需要Embedding扩展其内涵,需要交叉扩展其外延。
- 高维特征空间直接接入DNN,会引发参数规模的膨胀。为解决这一难题,Field & Pooling应运而生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号