推荐系统—实用分析技巧
0、参考链接
https://mp.weixin.qq.com/s/-c0fYyv9tCdBdiKbG7NPIg
1、问:指标上不去,rank加特征能够提升吗?
分析办法:把rank分数分成若干区间,每个区间统计真实的ctr,更*一步,可以拆分成多个桶,比如按照某个特征拆分成 A,B两组,单独统计每组的真实ctr。
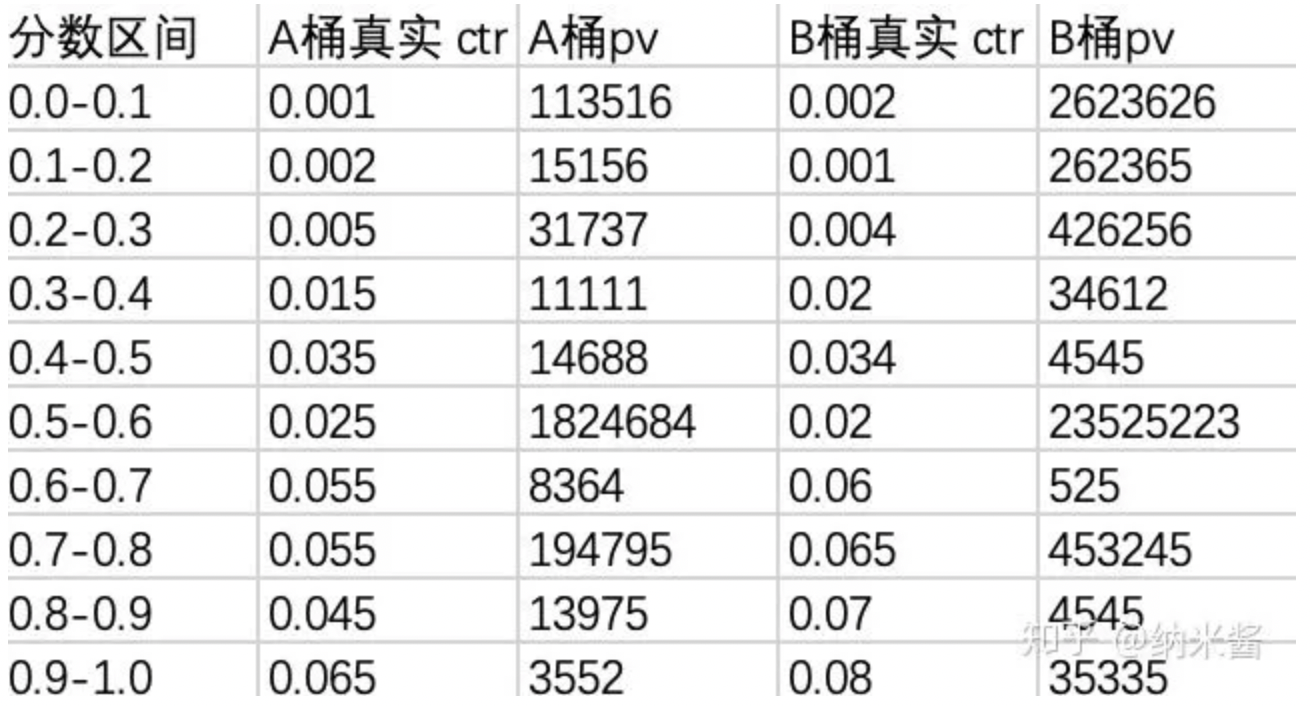
(1)rank分数单调递增,ctr没有单调递增
特征没做好线上线下的统一,也有可能是你模型没拟合好线上的分布。
这个原因多半是你线上线下分布不一致导致的,道理很简单,如果你的rank真的拟合好了分布,没理由高分数区间段的ctr会低于低分数区间。这个不一致,有可能是你特征没做好线上线下的统一,也有可能是你模型没拟合好线上的分布。总之这种情况,你先别急着加特征,先把线上线下特征梳理一下,看看分布是否一致,或者模型训练是不是有问题。
这个不一致,有可能是你特征没做好线上线下的统一,也有可能是你模型没拟合好线上的分布。总之这种情况,你先别急着加特征,先把线上线下特征梳理一下,看看分布是否一致,或者模型训练是不是有问题。
(2)rank 分数单调递增,ctr 单调递增,但是增长非常慢
模型缺特征,尤其是缺乏活跃用户的特征。
比如说0.9-1.0区间的ctr 仅仅比0.3-0.4区间的 ctr 高一丁点。这个原因才是你模型缺特征,尤其是缺乏活跃用户的特征,通常活跃用户,系统 rank 为了指标,会使用很重的行为画像作为特征,很容易放大历史点击记录,更加倾向于把他们排上去,如果你高估了该用户的点击倾向,就会导致分数给的很高,但是现实用户不怎么点的现象;
这个也会触发新的问题,也就是常说的离线AUC很高,但是线上没效果,道理都一样,你模型仅仅是把正负样本的间隔拉开了,并没有真正改善用户看到的内容和布局,才导致高分段ctr不见增长。
(3)rank分数单调递增,ctr也单调递增,但是 A,B两组的ctr比值差异过大
分纬度、分桶,检查哪个纬度的建模不足。
比如 A,B表示上午和下午,如果这两个时间段,同一个分数区间的ctr差异过大,说明模型对时间这个维度的建模不足,需要进一步改善。数学很好证明:假设模型分布是q(y|A), q(y|B),真实的线上分布是 p(y|A),p(y|B),A,B处于同一个分数段,数学上等价于:q(y|A) = q(y|B),由于你假设你模型正确拟合了真实分布,也就是 q(y|A) = p(y|A), q(y|B) = p(y|B),但是现实上 A,B的ctr并不相等,P(y|A) != p(y|B),故此,你模型正确拟合A,B两个条件分布的假设不成立。
这种分组copc的技巧,是一种前期快速判断rank的不足之处,精准化打击系统,对于不见兔子不撒鹰的主,有理由推动对方更快地推进业务迭代;
(4)rank分数单调递增,ctr单调递增,各种维度分组下的ctr比值也接**稳
恭喜你,到达这一步,表示你 rank 几乎没事情可做了,你剩下要做就是优化召回,在策略上引导你rank往新的产品思路上走,在更加高的层面带动系统往良性地方发展(黄赌毒方向)。
2、问:PV增大,但是CTR跌的很厉害
答:数学上,PV增加CTR就会跌,但一般都会是常数,如果PV增加CTR跌太厉害,你就需要警惕你的投放人群了。
3、问:如何统计曝光次数少的 item 的热度
答:一般来说,很多item的曝光次数可能只有数十次,高热度的item曝光可能是上万,甚至百万次,曝光过低的item,只要产生少数几次点击,其ctr就有可能非常高,甚至吊打高热item的点击率,统计学上针对这种问题,一般是采取 wilson ctr纠正,但是现实来说,wilson ctr非常不靠谱,曝光低的item,大概率是你精准投放人群导致的,并不满足wilson ctr随机投放的基本假设。确切来说,我们要分人群去统计相对的ctr,消除投放人群的bias。方法:假设item A被投放给N个人,曝光200次,产生10次点击,同时,这N个人当中,高热item B给他们曝光了100000次,产生 900 次点击。所以,A和B 在同一批人群当中的 ctr 分别是:(10 / 200, 900 / 100000),一般我们认为高热的 item 都是无关个性化的,比如热点新闻,促销商品,黄色暴力内容,大家都爱点,高热item的点击率和投放人群的关系不是很大,几乎人人都会点,可以作为CTR本底。扣除这种ctr表示,相比大众货,用户更喜欢点那些item,用这种相对的ctr作为item热度的衡量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号