python ---lxml解析网页--(搬运)
目录
1. 什么是lxml
lxml是干什么的?简单的说来,lxml是帮助我们解析HTML、XML文件,快速定位,搜索、获取特定内容的Python库。我们知道,对于纯文本的HTML文件的查找可以使用正则表达式、BeautifulSoup等完成。lxml也是对网页内容解析的一个库。
那么为什么要用lxml呢?据听说他比较快。我没有用来做过大项目,对解析速度理解不是很深刻。我用lxml只是因为它似乎比BeautifulSoup好用。
2. 初次使用
- 安装
sudo pip3 install lxml
- 初次使用
# 导入lxml
from lxml import etree
# html字符串
html_str = """
<html>
<head>
<title>demo</title>
</head>
<body>
<p>1111111</p>
</body>
</html>
"""
# 利用html_str创建一个节点树对象
html = etree.HTML(html_str)
type(html) # 输出结果为:lxml.etree._Element
- 首次解析HTML
不用理会下面代码中出现的新的方法和各种解析的技巧。先看一下lxml如何快速方便的解析html.
# 我们现在要获得上面的html文件中的p标签的内容
p_str = html.xpath('//body/p/text()') # 返回结果为一个列表:['1111111']
上面的例子,给出一个lxml如何解析HTML文件的实例。后文中众多的知识点,只不过是讲解更多的xpath解析方法技巧。
3. xpath
我们一直再讲lxml,这里突然出现xpath是干什么的?lxml的主要功能是解析HTML,他是利用什么语法来解析HTML的呢?就是利用xpath,因此,我们需要了解如何使用xpath。
xpath将html文档看做一个有众多的节点按照特定级别组织的节点树,对于其中内容的解析,又三种主要的措施:
- 标签定位
- 序列定位
- 轴定位
很抱歉,我们又引入了新的概念。但现在我们解释这些概念是不明智的,还是先看一下如何使用。
3.2 标签定位
为了说明xpath各种定位语法,我们下面利用如下的HTML来完成讲解。
from lxml import etree
html_str = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>The Document's story</title>
</head>
<body>
<div class="table1">
<ul class="one" id="id1">
<tr>tr1</tr>
<tr>tr2</tr>
<tr>tr3</tr>
<tr>tr4</tr>
</ul>
<ol class="two" id="id2">
<td>td1</td>
<td>td2</td>
<td>td3</td>
<td>td4</td>
</ol>
</div>
<div class="table2">
<a href="www.table2_1.com"><span>table2_span</span></a>
<a href="www.table2_2.com">
<p><h2>TABLE2</h2></p>
</a>
<a href="www.table2_3.com" id="id3">
<ul class="table_one" id="id4">
<tr>tr1_a</tr>
<tr>tr2_a</tr>
<tr>tr3_a</tr>
<tr>tr4_a</tr>
</ul>
</a>
</div>
</body>
</html>
"""
html = etree.HTML(html_str)
html.xpath('//*') # 请将'//*'替换成下面表中实例列的表达式以观察各表达式的含义和作用。
先给出一张表。下表中给出了标签定位的表达式和对其作用的描述。下表中,实例列中的表达式的全部表达如下:如第一行中的命令为'//div',则全部的表达式为html.xpath('//div') 。注意,这里的html是一个lxml.etree._Element对象。(我们用HTML表示HTML文件或者其对应的字符串。)
| 表达式 | 描述 | 实例 | 解释 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点 | '//div' | 找到html树中的所有div标签 |
| / | 从根节点选取 | '/head/title' | 从根节点找到head->title |
| // | 选取任意位置的某个节点 | '//' | html中所有p标签 |
| . | 选取当前节点 | '.' | 返回当前节点对象 |
| .. | 选取当前节点的父节点 | '/html/head/..' | 返回head的父节点html |
| @ | 选取属性 | '//div[@class="one"]' | 返回具有属性class,并且class的值为"one"的节点 |
| * | 通配符 | '//div/*' | 返回所有满足条件的节点 |
| | | 一次选择多个路径 | '/html/head | //div' | 返回head节点或者div节点 |
| @* | 选取所有属性 | '//div[@*]' | 返回所有具有属性的div对象 |
3.3 序列定位
通过上面的学习,我们知道html.xpath()返回的是一个包含节点树对象的列表,对于列表中的元素,我们可以按照列表的索引进行查找,但是,如果想在xpath里面进行选择,就需要使用序列定位。
下面的代码承接上文。在给出一张表。
| 谓语 | 描述 | 实例 | 解释 |
|---|---|---|---|
| [1] | 第一个元素 | '//div[1]' | 返回第一个div对象 |
| [last()] | 最后一个元素 | '//div[last()]' | 返回最后一个div对象 |
| [last()-1] | 倒数第二个元素 | '//div/ul[1]/tr[last()-1]' | 返回所有div对象中第一个ul对象下面的倒数第二个tr对象 |
| [position()❤️] | 最前面的两个元素 | '//tr[position()❤️]' | 返回前两个tr对象 |
| [@lang] | 所有拥有属性lang的元素 | '//div[@class]' | 返回具有calss属性的div |
| [@lang='en'] | 所有lang='en'的元素 | '//div[@class="en"]' | 返回class属性值为en的div对象 |
3.4 轴定位
同上。
| 轴名称 | 描述 | 实例 | 解释 |
|---|---|---|---|
| child | 当前节点的所有子元素 | '//div[1]/child:😗' | 第一个div的所有子节点 |
| parent | 当前节点的父节点 | '//div[1]/parent:😗' | 第一个div的父节点 |
| ancestor | 当前节点的所有先辈 | '//div[1]/ancestor:😗' | 第一个div的所有祖先节点 |
| ancestor-or-self | 当前节点及其所有先辈 | '//div[1]/ancestor-or-self:😗' | .. |
| descendant | 当前节点的所有后代 | '//div[1]/descendant::ul' | 第一个div的子孙节点中的ul对象 |
| descendant-or-self | 当前节点及其所有后代 | '//body/descendant-or-self' | .. |
| preceding | 文档中当前节点开始标记之前的所有节点 | '//body/preceding:😗' | .. |
| following | 文档中当前节点结束标记之后的所有节点 | '//body/following:😗' | .. |
| preceding-sibling | 当前节点之前的所有同级节点 | '//div/preceding-sibling:😗' | .. |
| following-sibling | 当前节点之后的所有同级节点 | '//div/following-sibling:😗' | .. |
| self | 当前节点 | '//div[0]/self:😗' | 返回当前节点 |
| attribute | 当前节点的所有属性 | '//div/attribute:😗' | 返回所有属性值 |
| namespace | 当前节点的所有命名空间 | '//div/namespace:😗' | 返回命名空间 |
4. 实例
我们已经学了很多的xpath语法。现在可以完成一个小小的综合练习,用以巩固我们的学习。
我们的需求:到tiobe上面抓取最后欢迎的语言top20,并对这些语言的使用情况最简单的可视化。
上代码,如有需要请看代码中的注释。
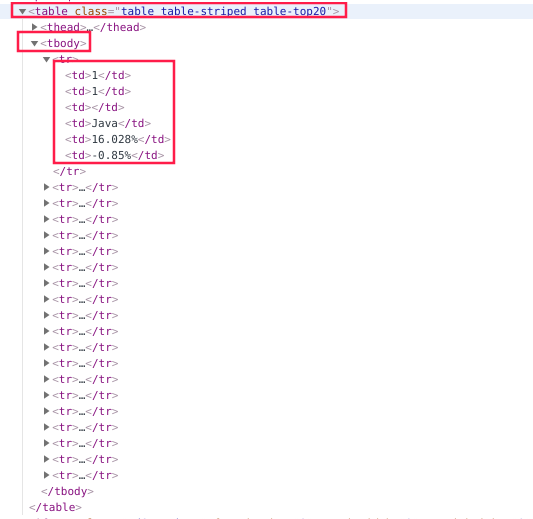
网页内容定位如下:
# 导入所需要的库
import urllib.request as urlrequest
from lxml import etree
# 获取html
url = r'https://www.tiobe.com/tiobe-index/'
page = urlrequest.urlopen(url).read()
# 创建lxml对象
html = etree.HTML(page)
# 解析HTML,筛选数据
df = html.xpath('//table[contains(@class, "table-top20")]/tbody/tr//text()')
# 数据写入数据库
import pandas as pd
tmp = []
for i in range(0, len(df), 5):
tmp.append(df[i: i+5])
df = pd.DataFrame(tmp)
# 查看数据
df.head(2)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | Java | 16.028% | -0.85% |
| 1 | 2 | 2 | C | 15.154% | +0.19% |
原始数据存在一些问题:
- 数据列名称含义不明,要给列添加有意义的名称['Aug 2019', 'Aug 2018', 'Name', 'Rating', 'Change']
- 最后两列为字符串,需要转换成float格式
# 数据处理
df.columns = ['Aug 2019', 'Aug 2018', 'Name', 'Rating', 'Change']
# 处理最后两列数据
df['Rating'] = [float(istr.replace('%', '')) for istr in df['Rating']]
df['Change'] = [float(istr.replace('%', '')) for istr in df['Change']]
# 再次查看数据
df.head()
| Aug 2019 | Aug 2018 | Name | Rating | Change | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | Java | 16.028 | -0.85 |
| 1 | 2 | 2 | C | 15.154 | 0.19 |
| 2 | 3 | 4 | Python | 10.020 | 3.03 |
| 3 | 4 | 3 | C++ | 6.057 | -1.41 |
| 4 | 5 | 6 | C# | 3.842 | 0.30 |
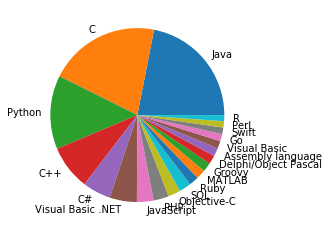
# 绘制图像
import matplotlib.pyplot as plt
plt.pie(df['Rating'], labels=df['Name'])
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号