
学习笔记四 文件读写,集合,元组,函数
一、文件读写几种模式总结:
读模式: r 打开不存在的文件会报错、不能写(不能调用write方法),可以读(能调用read方法)
写模式: w # 1、打开不存在的文件,会新建一个文件,但每次打开都会清空原有文件内容
# 2、不能读(不能调用read方法),可以写(能调用write方法)
追加模式 a # 1、打开不存在的文件,会新建,可以写(可以调用write方法)
# 2、不能读(不能调用read方法)
读写模式 r+ # 1、能写能读,但每次都是重头写入,会覆盖原有的文件内容
# 2、打开不存在文件的时候会报错
写读模式 w+ # 1、能读能写
# 2、但读不到内容,因为每次打开w先把文件内容清空
追加读模式 a+ # 1、能读能写
# 2、每次读的时候,文件指针是在文件末尾。如果需要重头读起,需要f.seek(0)将指针移到文件开始(注意在Python中,a或a+模式修改文件指针对于文件的写入没有影响,都会在结尾追加写入当文件写入数据后),在没有关闭文件前,此时写入的数据还在内存中,没有写入磁盘,当文件在其他地方打开的时候,是看不到新写入的数据,如果希望新写入的数据立即生效写入磁盘,需要用f.flush(),文件末尾用f.tell()
读取文件内容三个方法:
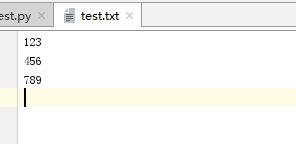 比如有文件test.txt
比如有文件test.txt
1.read():方法用于从文件读取指定的字节数,如果未给定或为负则读取所有。

2.readline():一次读取文件的一行。如果文件指针在文件开始位置,则读取的是第一行数据。

3.readlines():读取文件的所有行,并且以list形式返回
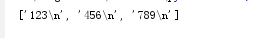
4.直接循环文件对象:当文件比较大的时候可以用此方法


文件的写操作:
1.write(str):参数必须是个字符串,写入的内容就是str
2.writelines(sequence):参数是一切可迭代的(字符串,list,元组,set,dict)的对象,其运行原理是将sequence的内容以遍历的方式依次读取写入
5.文件操作小代码:监控日志

6.文件操作小代码:修改文件
with 操作会自动调用close(),无需手动写关闭文件操作
第一种方式:全部读取文件的内容后修改其内容,将原有文件内容删除,然后将修改的内容直接复制写进去
第二种方式(推荐):创建一个新的空文件,将修改的内容写入到新文件后,再删除原有的旧文件,将新文件更名成旧文件名

二.集合
1.集合的重要属性:可以自动去重!(划重点)
2.集合初始化:s=set(),集合也是用{}括起来的形式,但不是键值对。空的集合必须用set()初始化不能用{},因为{}表示空的字典
3.集合的几种运算:
1.交集:找出集合之间相同的元素
两种方式:intersection()和&


2.并集:把2个集合合并到一起,然后去除重复
两种方式:union和|


3.差集:前面一个有,后面一个没有的
两种方式:difference和 -


4.对称差集: 只在一个集合里面出现过的,都给你整出来(除交集以外的那些元素)
两种方法:symmetric和^


4.集合元素新增:add,无返回值


5.集合元素删除:因为集合是无序的,所以无法通过指定下标来操作(没有下标这个概念)
1.pop:随机删除,返回删除的那个值,不能带任何参数
2.remove:指定元素删除,没有返回值


6.集合的遍历:


三.string模块的几个方法:


四.元组:元组也是一个有序的序列,特点是值不能修改
1.元组的初始化:一定要用逗号间隔


五.随机操作常用方法:
需要导入模块:import random
1.randint(a,b):随机一个整数,范围左闭右闭
random.randint(1,23):随机一个范围在1和23直接的整数
2.choice(seq):从一个有序的序列(不包括字典和集合)中随机选一个值返回,返回类型同返回元素的类型
3.sample(seq,n):从一个有序的序列(不包括字典和集合)中随机选n个值组成list返回
4.shuffle(list):参数只能是list,打乱一个list的顺序,无返回值
5.uniform(a,b) :a-b直接随机取小数

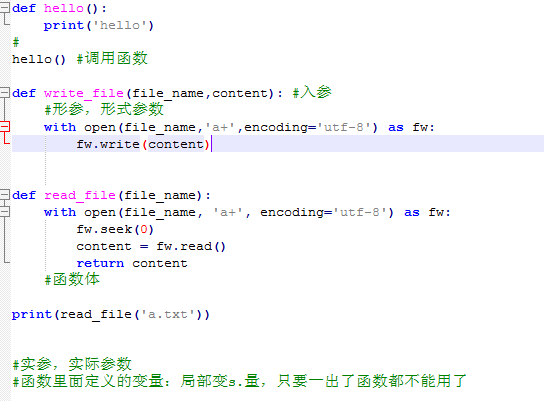
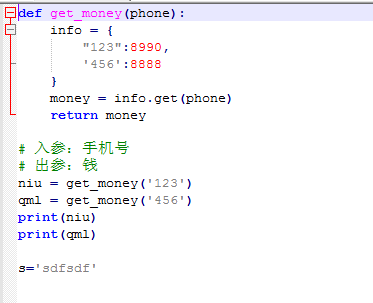
六.函数简单介绍:
函数以def定义,函数名(),:结尾,默认返回值为None,也可以自定义返回值
函数的形参:函数定义的时候括号里带的参数
函数的实参:函数调用时传入的实际参数
函数的变量:函数里面定义的变量,作用域只在函数体内,函数体外不可见
函数的返回值:返回值作为函数的一个处理结果返回给调用者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号