【持续更新】创新实训
前言
智谱AI发布了最新的代码模型CodeGeeX2-6B( https://mp.weixin.qq.com/s/qw31ThM4AjG6RrjNwsfZwg ),并已在魔搭社区开源。
CodeGeeX2作为多语言代码生成模型CodeGeeX的第二代模型,使用ChatGLM2架构注入代码实现,具有多种特性,如更强大的代码能力、更优秀的模型特性、更全面的AI编程助手和更开放的协议等。
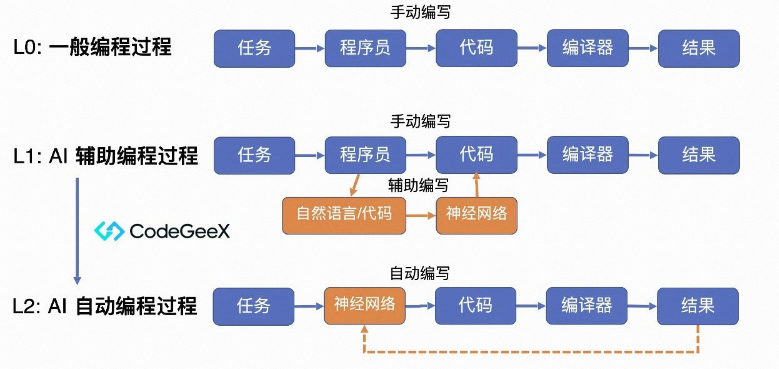
我们的工作
随着互联网+的生态模式和人工智能的产业化发展,程序设计已成为计算机专业乃至工科学生的必备技能之一。学生学习程序设计,不仅能提高代码水平能力,学会如何写代码,如何写好代码,而且能锻炼学生在今后面对项目开发等实际应用场景时解决问题的能力。因此,很多同学在刚刚接触到编程时往往需要练习一些简单的程序设计题目。如大一时的高级程序设计、C++程序设计等课程,老师在讲课之余往往会布置一些程序设计的习题,让同学自己去练习,在亲身实践中巩固知识,增进对编程的理解。但软件学院至今没有自己的在线评测系统,老师布置习题时往往只能选用PTA等现有平台,PTA等平台手动添加题目不便,题目往往都是经典案例,很容易就能在网络上找到相关解法,不利于同学们独立思考、独立解题。同时教师在授课的过程中往往无法根据教学进度和学生们的实际掌握程度添加适合学生练习的题目。如果学院有一个自行研发的在线评测系统,有助于教师更灵活自由地开展各种教学活动,如使用该平台可以进行上机实操的期中考试。
然而,与其他传统学科不同,程序设计可能出现的错误千变万化,有时十分隐晦。这也使得其入门门槛较高,且常常需要耗费讲师和助教大量的时间和精力帮助初学者 debug。在这样的问题背景下,我们想要获得一个AI助手,让它帮助学生进行代码纠错,从而方便了教师教学的同时提高了学生的学习效率。微软推出的 Copilot 是一款通过理解用户输入的代码注释或部分代码片段、自动生成或补全代码的AI助手。它的问世说明了大模型具备相当不错的修改和续写代码的能力。我们希望可以通过微调,得到一个更加高效的、主要面向初学者的代码纠错工具。为了生成更具教育意义的代码,我们决定使用数百道经典例题和他们相应解法的 规范代码 对 CodeGeeX2-6B 进行微调。
架构设计: 设计一个分布式系统,包括前端、后端和纠错大模型组件。
前端: 开发一个基本需求功能齐全同时对用户友好的网页界面,主要包括用户提交代码、查看纠错结果以及提供反馈信息等功能。前端会将用户的代码发送给后端,等待后端程序的处理并接受后端发送过来的纠错信息和反馈信息,并将信息以合适的方式显示在前端告知用户。
后端: 构建一个高性能的服务器端应用程序,负责接收用户提交的代码,并对代码进行评测,若评测通过,程序将会返回给前端代码通过(AC)信息。若评测无法通过,则将其发送给纠错大模型进行处理,并接受纠错信息和反馈信息,一并将这些信息发送给前端。
纠错大模型: 选择和集成一个强大的代码纠错大模型,用于自动分析和纠正用户提交的代码中的错误。这里的大模型我们选择使用清华大学开源的ChatGLM-CodeGeeX2(https://github.com/THUDM/ChatGLM-6B)。在该模型的基础上,选用程序设计试题的专门数据,进行 Fine-turning 的训练(即微调)
阶段一:需求分析和规划阶段,明确项目目标和功能需求。
阶段二:在线评测平台的开发和优化阶段,实现上述关于平台的绝大部分功能。
阶段三:模型开发应用和优化阶段,调整应用的 LLM 模型,并将其嵌入系统中。
阶段四:测试阶段。
阶段五:上线运营和持续优化阶段,将平台上线运营,并持续优化功能和性能。
Universal OnlineJudge 部署流程
安装 docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo systemctl start docker # 启动 docker 服务
sudo docker --version # 检查 docker 是否正常安装
sudo docker pull universaloj/uoj-system
sudo docker run --name uoj -dit -p 80:80 --cap-add SYS_PTRACE universaloj/uoj-system
有如下维护命令:
docker start uoj # 启动 uoj 容器
docker stop uoj # 暂停 uoj 容器
docker restart uoj # 重启 uoj 容器
docker exec -it uoj /bin/bash # 进入 uoj 容器的终端
docker commit uoj uoj_back:tag # 将 uoj 容器保存为标签为 tag 的 uoj_back 镜像
docker ps -a # 查看所有的容器
docker images # 查看所有的镜像
docker rm uoj # 删除 uoj 容器(慎用)
docker rmi uoj_back:tag # 删除标签为 tag 的 uoj_back 镜像,
数据恢复命令:
docker commit uoj uoj_back:20170101 # 例行备份
docker commit uoj uoj_back:20170201 # 例行备份
docker commit uoj uoj_back:20170301 # 例行备份
# 3月15日,黑恶势力破坏了 uoj,uoj 容器已经无用,必须恢复
docker stop uoj
docker rm uoj # 删除uoj容器
docker run --name uoj -dit -p 80:80 --cap-add SYS_PTRACE uoj_back:20170301
# 创建新的 uoj 容器,使用3月1日的备份
源码进度分析
代码分析
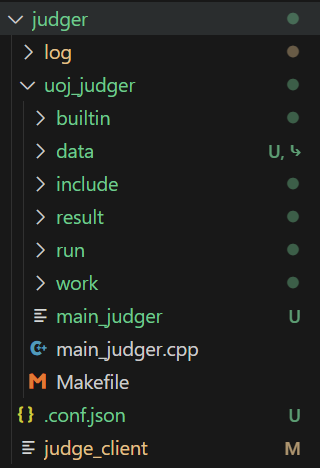
- data 是存储测试数据和配置文件的目录,其中包含解压后的文件和压缩包(作为备份)
- include 是测试相关的工具方法,
- result 暂存评测结果
- work 正在评测的题目包含的数据,每当有评测请求时,将所有测试数据拷贝到对应文件目录中
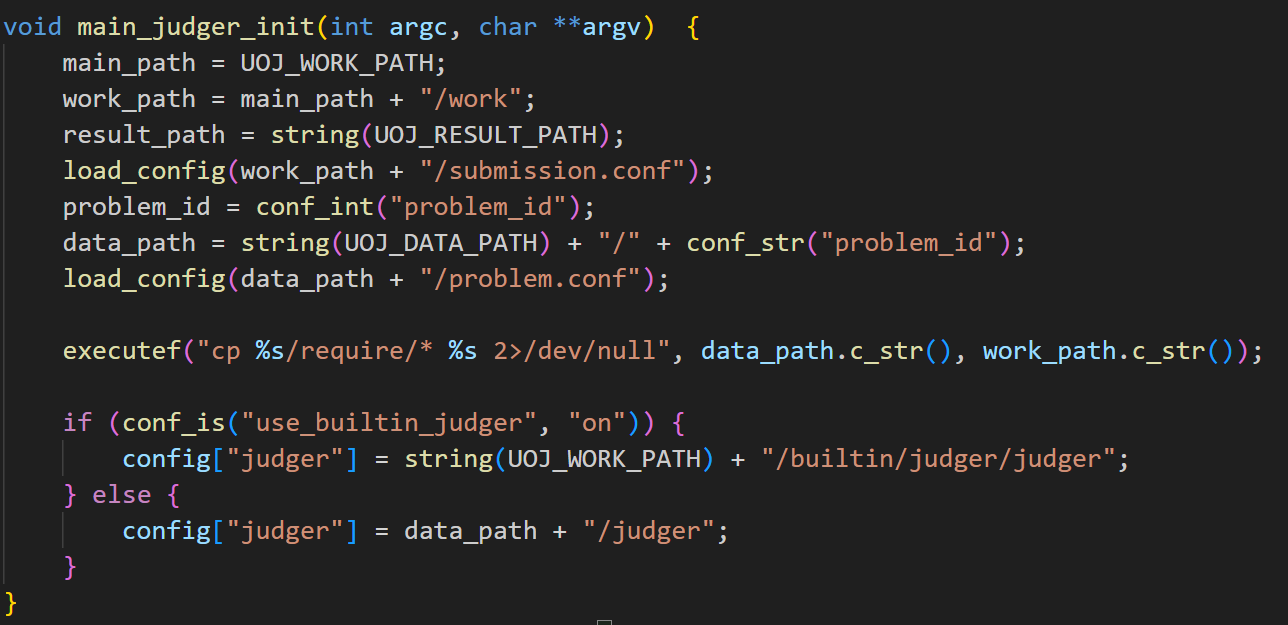
当有评测任务来到时,补全地址,使用系统调用将 data 拷到 work 目录:
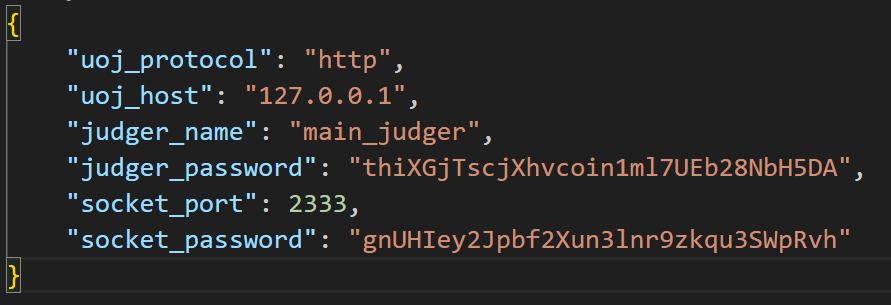
也可以添加多台评测机,做到分布式评测。具体修改 config.json
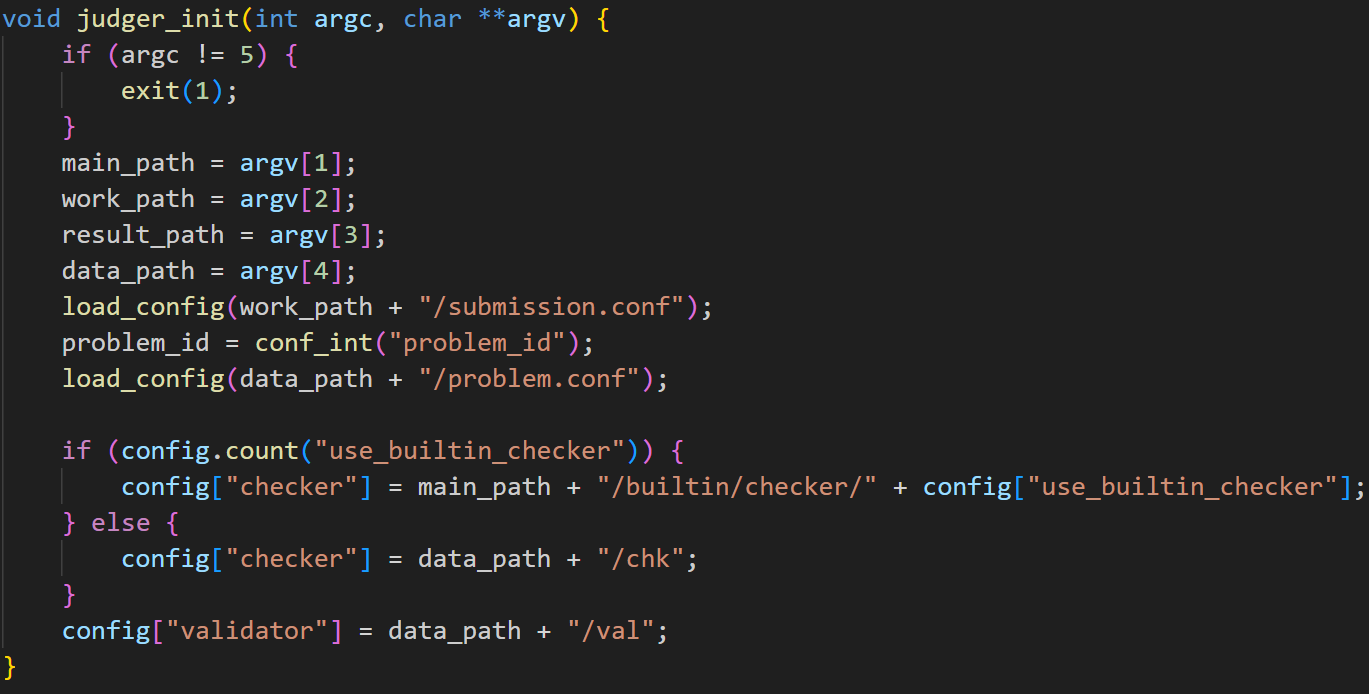
评测使用了 testlib.h 支持
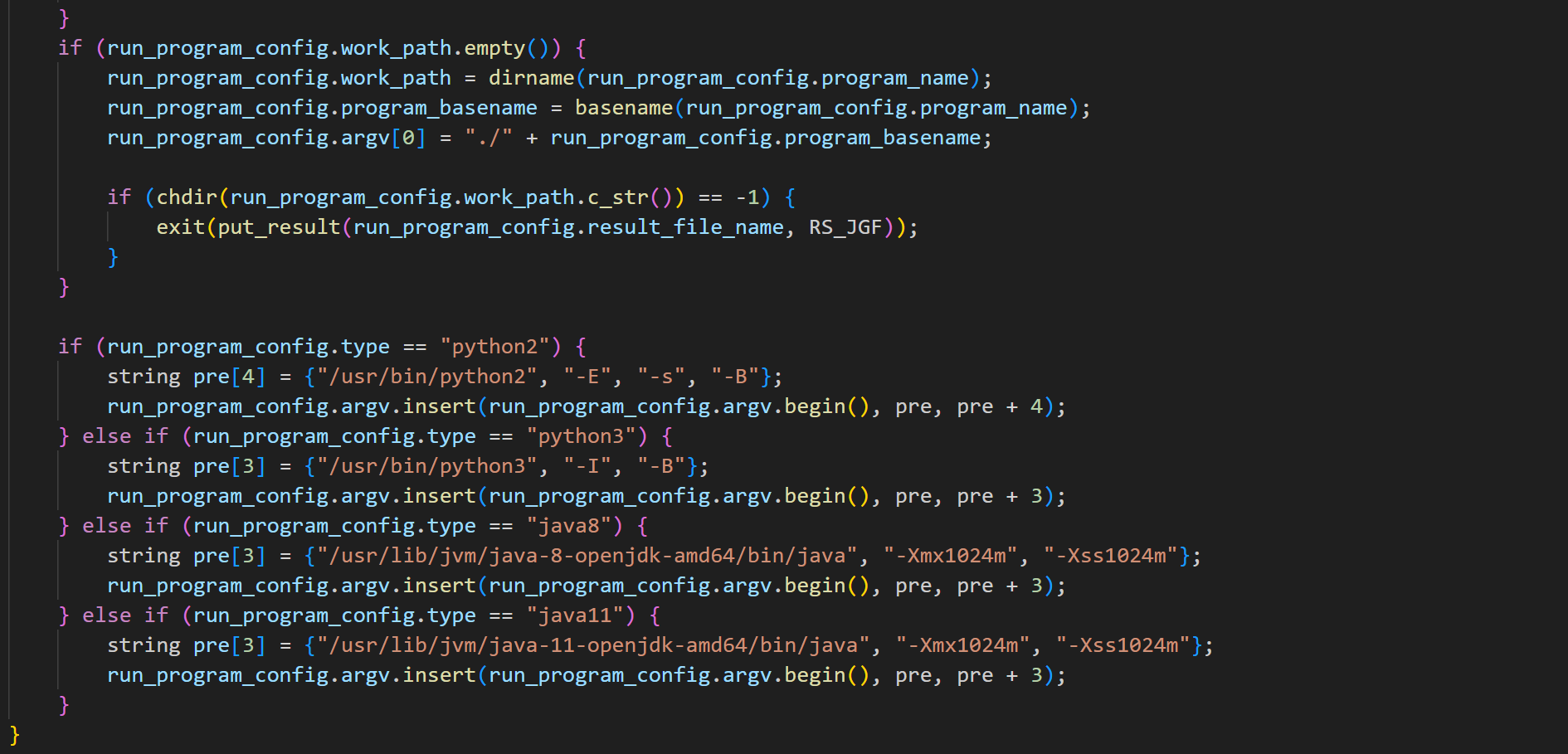
run 目录下的 formatter.cpp 用于将测试数据格式化,防止行末回车等问题产生的影响,run_program.cpp 则是一个简易的沙箱实现,具体内容我单开一节介绍
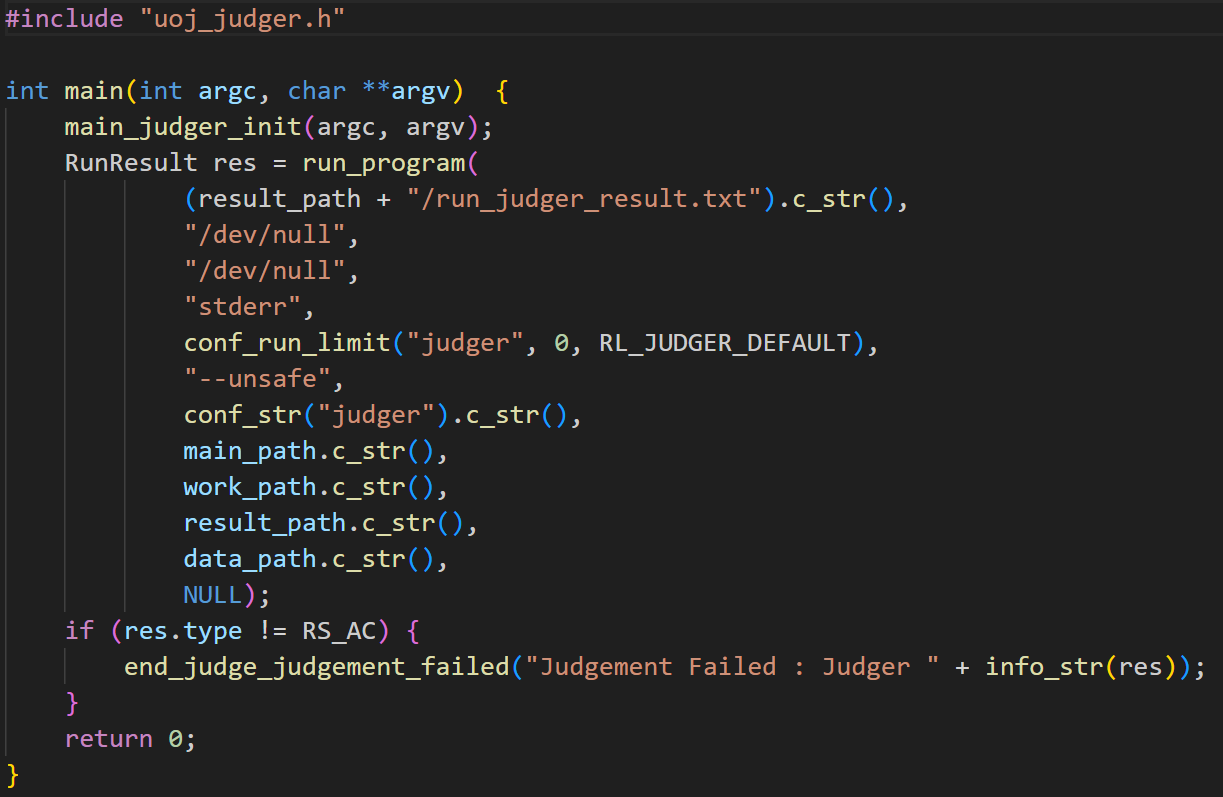
uoj_judger.h 是一个评测系统(judger)的部分实现
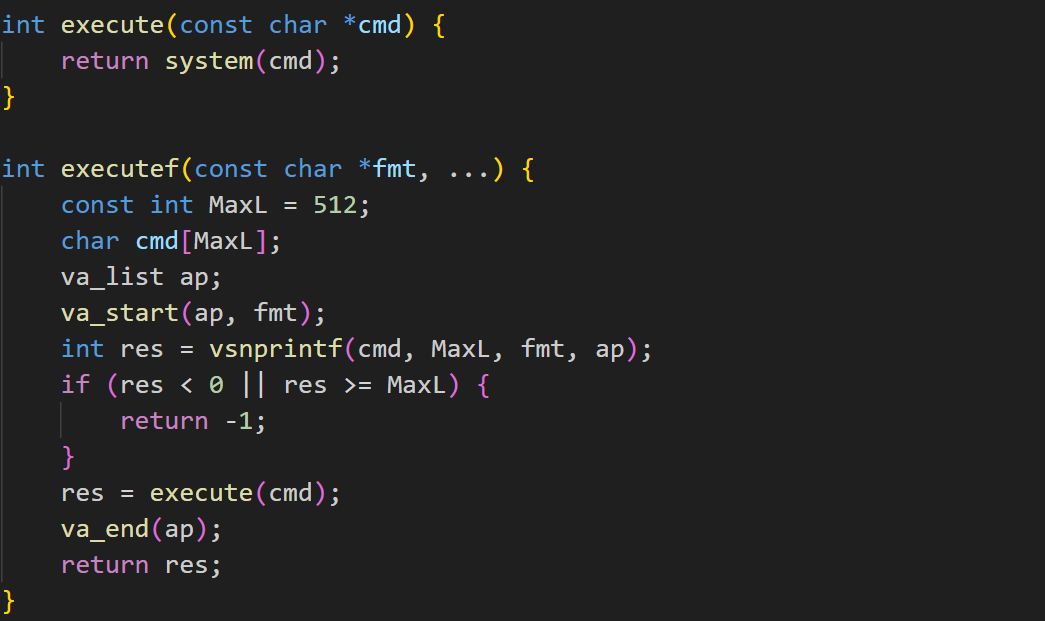
分为多个部分,execute 用于执行代码,
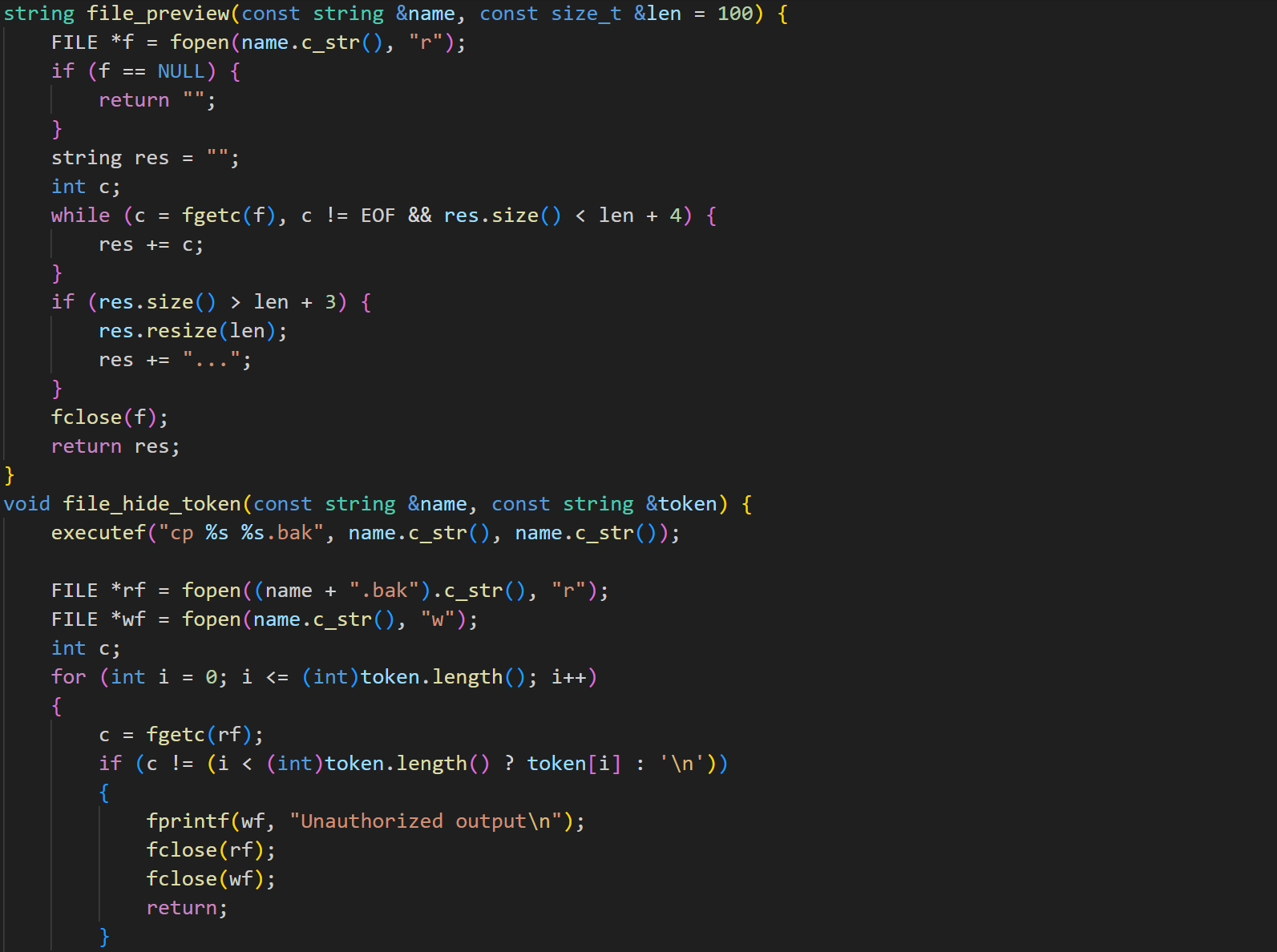
file 用于预览和隐藏文件
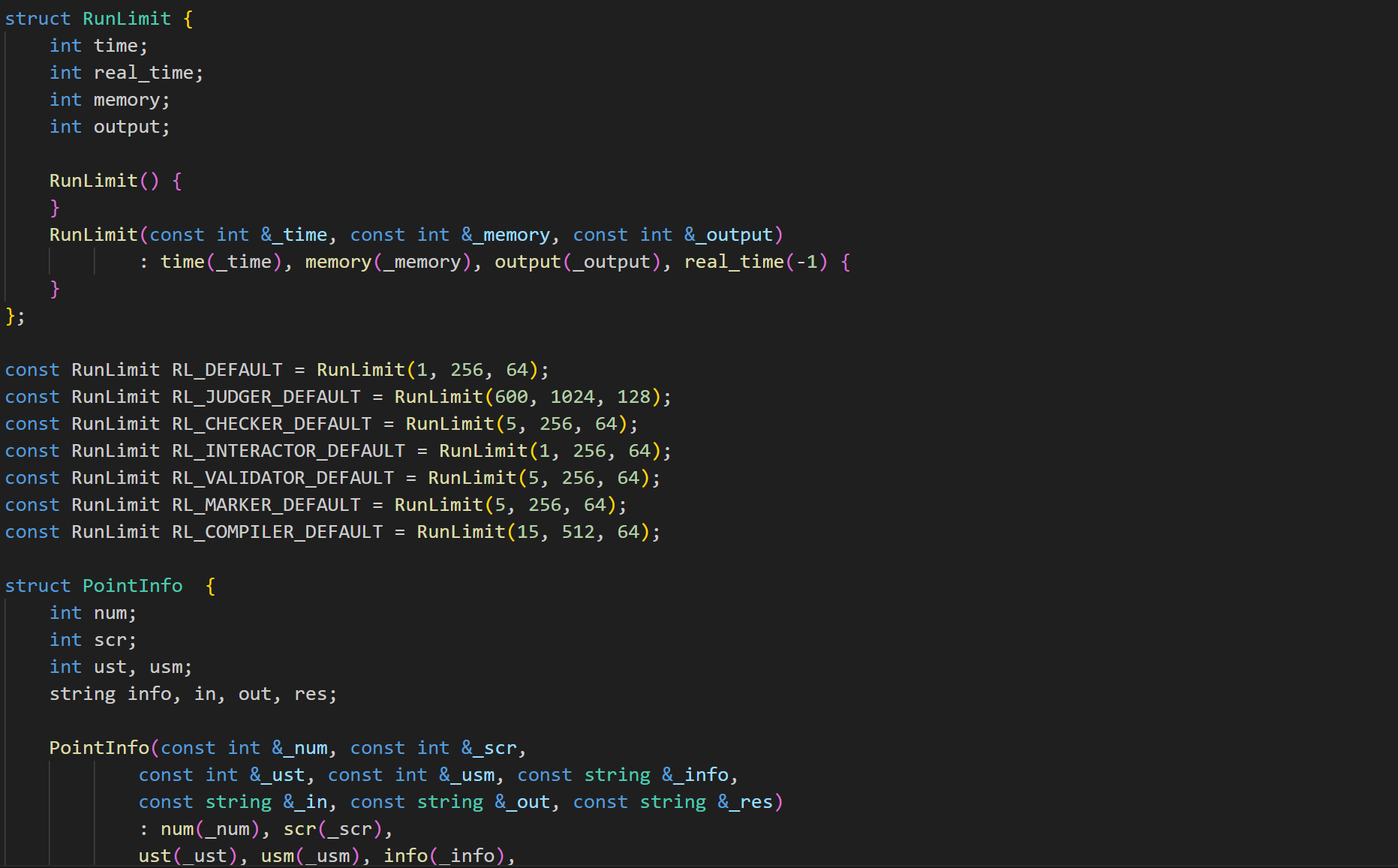
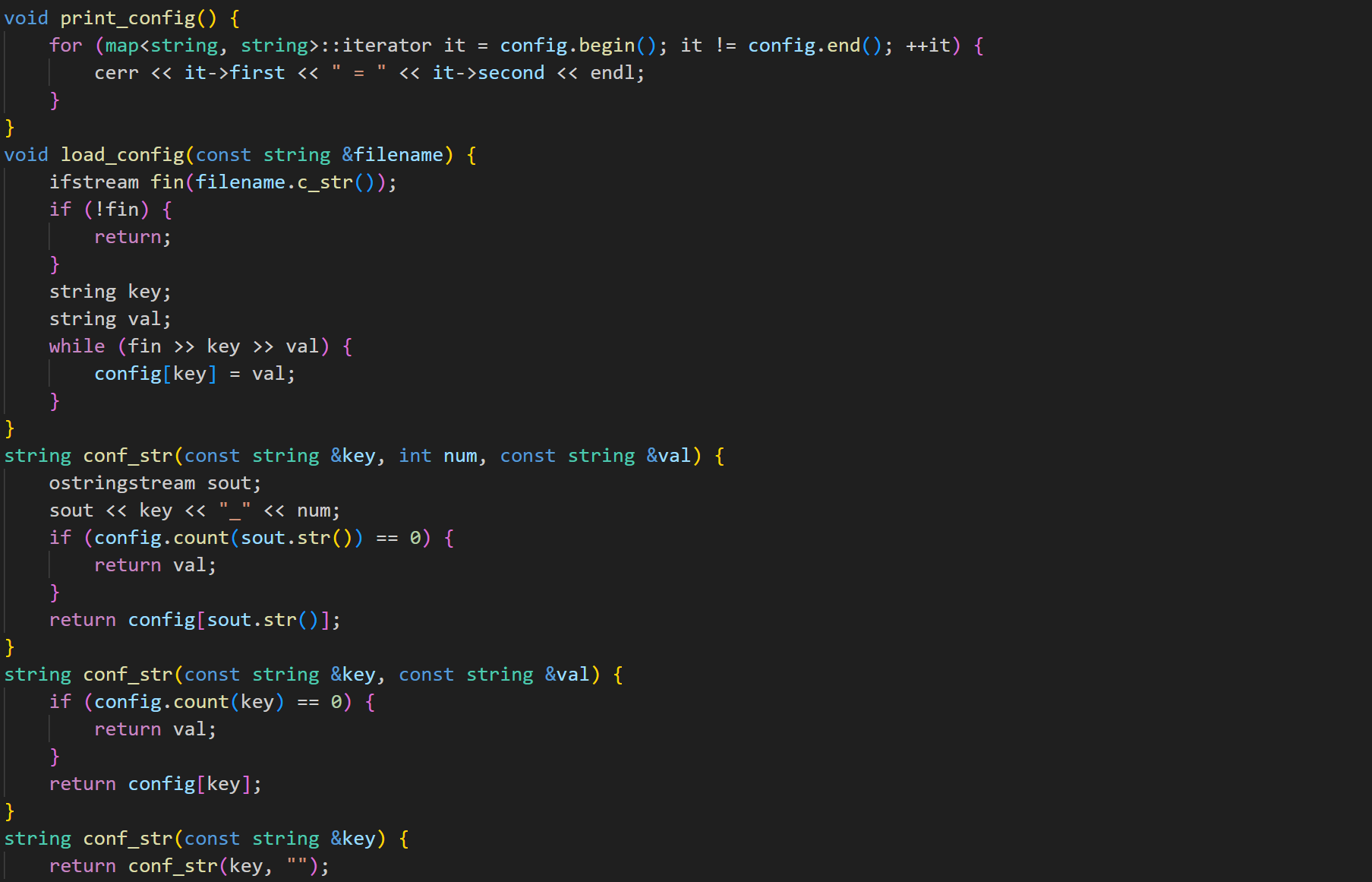
parameter 部分,用于修改参数:
配置部分:
执行部分:
该部分逻辑较为复杂,大致思路仍然是设置需要的参数和限制、约束条件,然后使用系统调用来执行用户提交的代码。
特别需要注意,交互题在这部分限制下会麻烦很多
沙箱
测评器运行时,不可避免地会需要涉及到运行选手程序的操作。但直接运行是十分危险的,因为选手有可能会提交恶意代码。
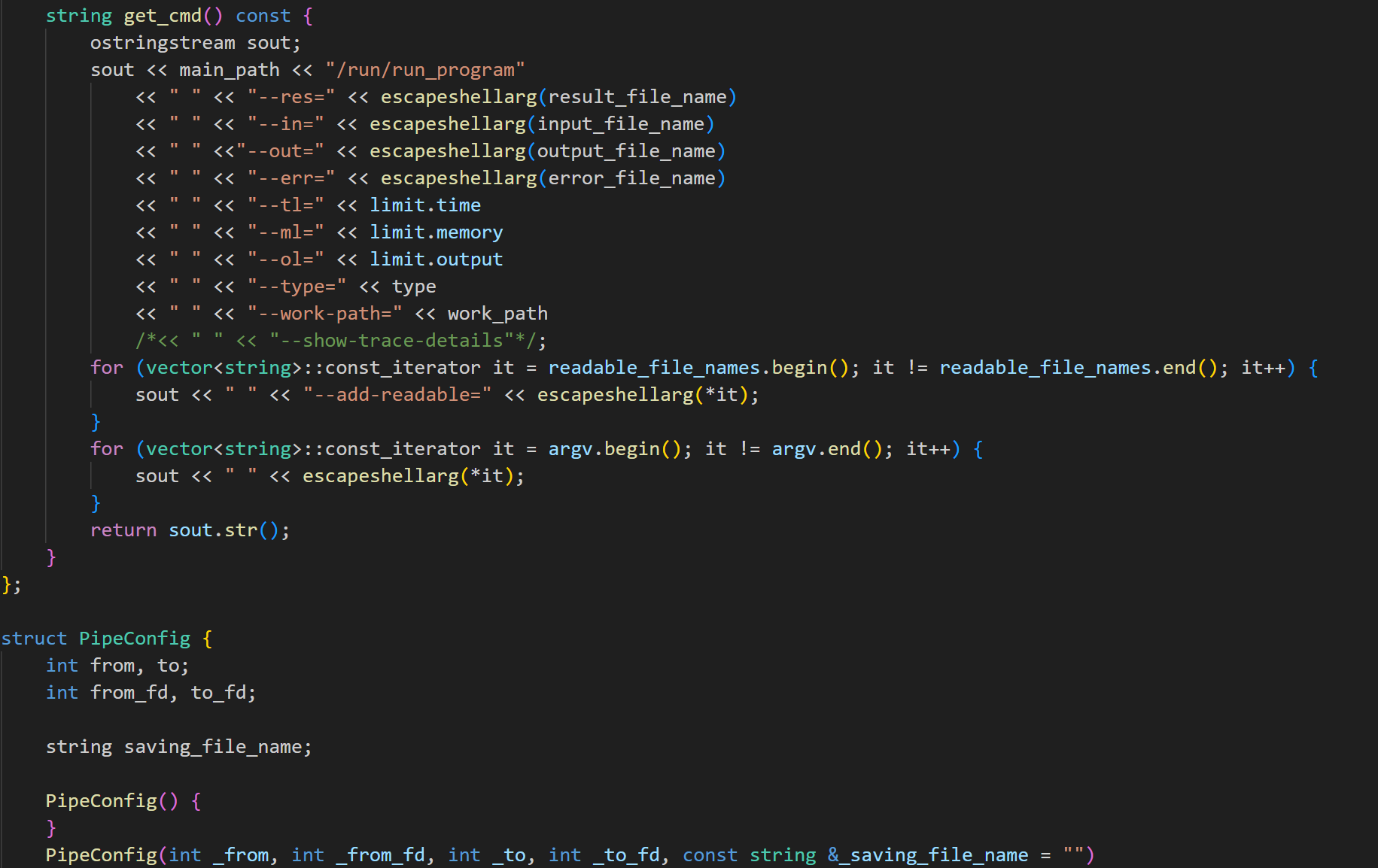
所以,本系统自己实现了一个基于 seccomp 和 ptrace 技术的沙箱,能够运行选手程序并在该程序做出可疑行为时果断杀死。沙箱位置在 run/run_program。每当测评器想要运行选手程序时,都会交由沙箱代为执行。该程序通过解析命令行参数,设置运行环境和资源限制,安全地执行指定的程序,并记录和输出其运行结果,可以确保被测程序在安全、受控的环境下运行。
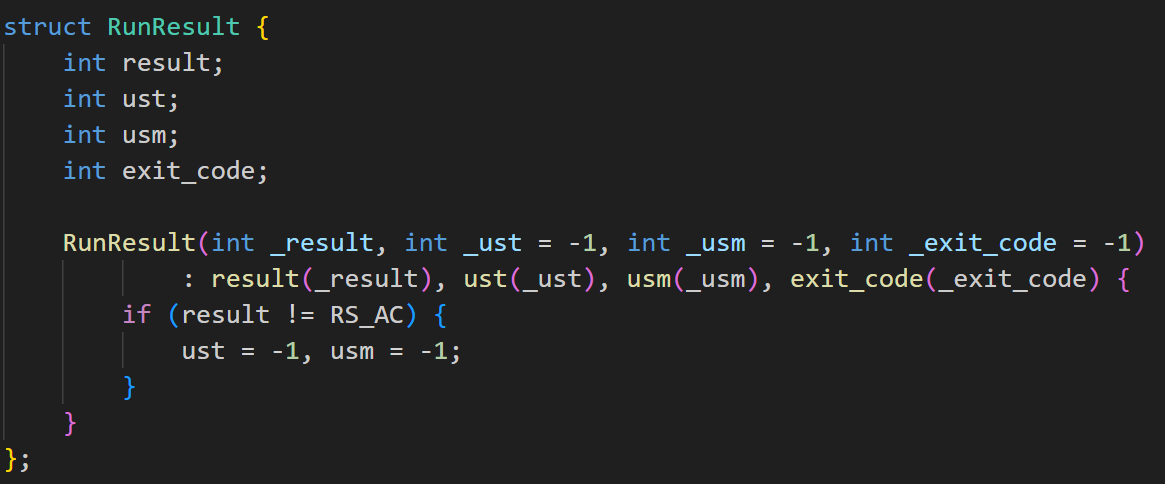
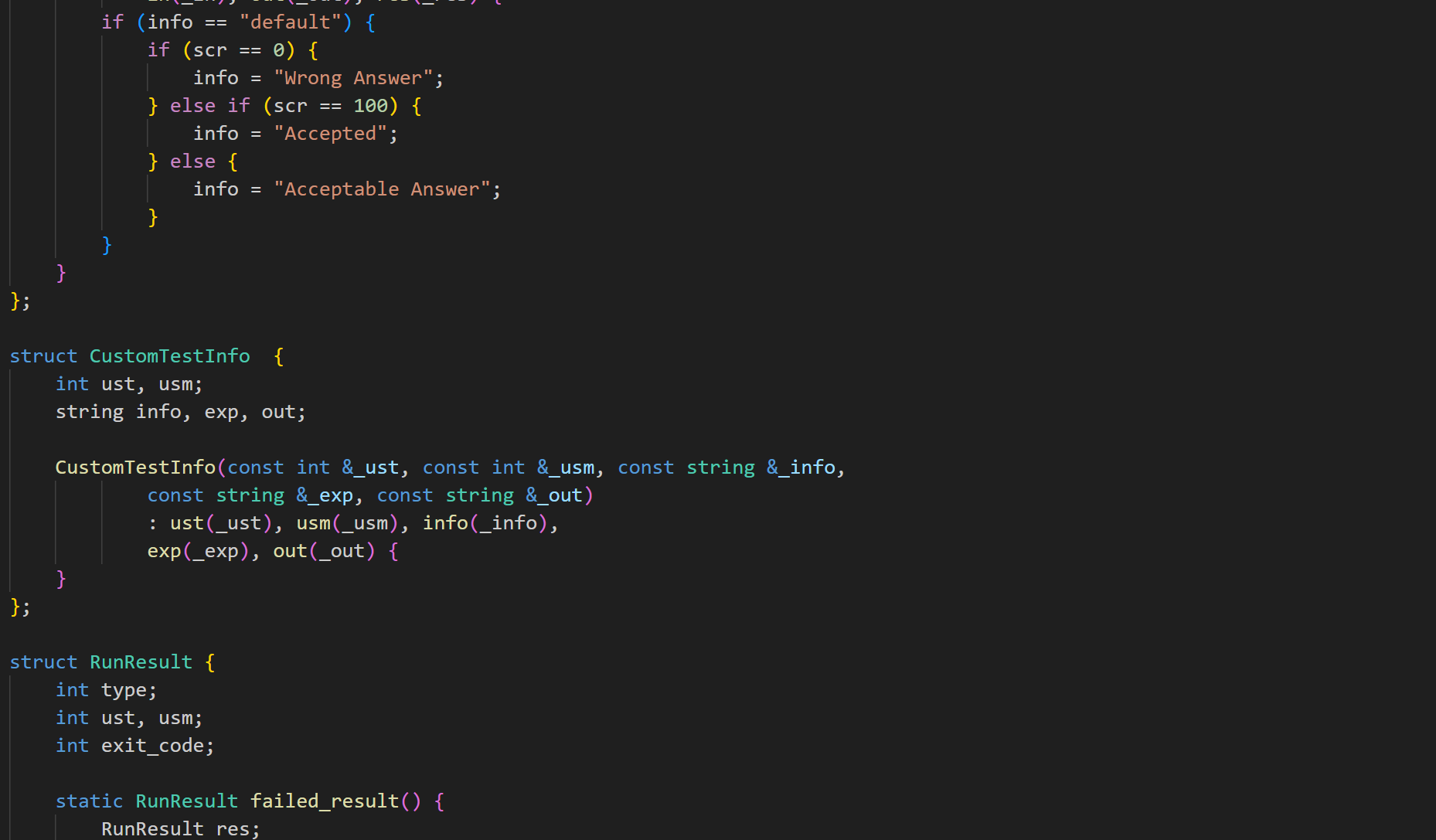
存储程序运行结果,包括:
- result: 运行结果状态。
- ust: 用户态运行时间。
- usm: 内存使用情况。
- exit_code: 程序退出代码。
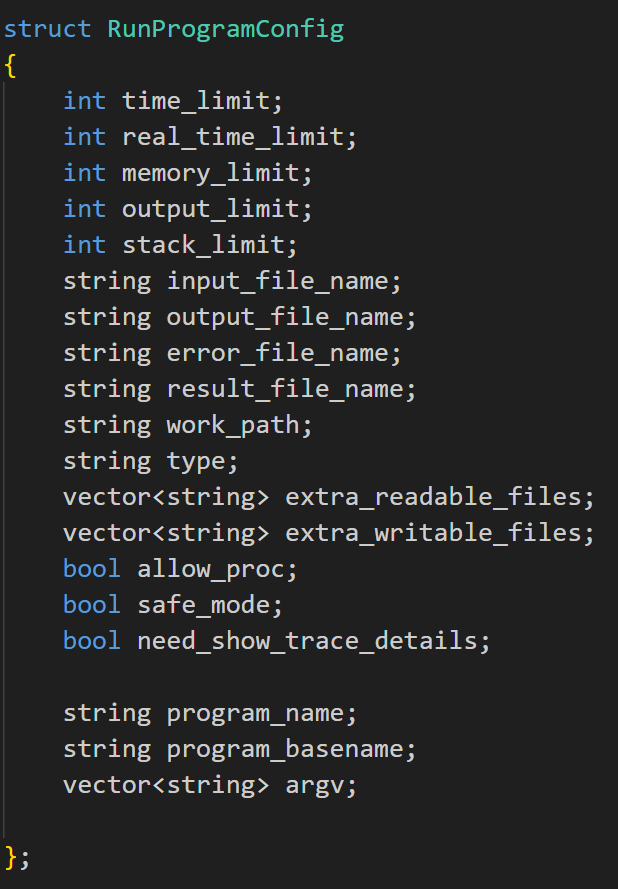
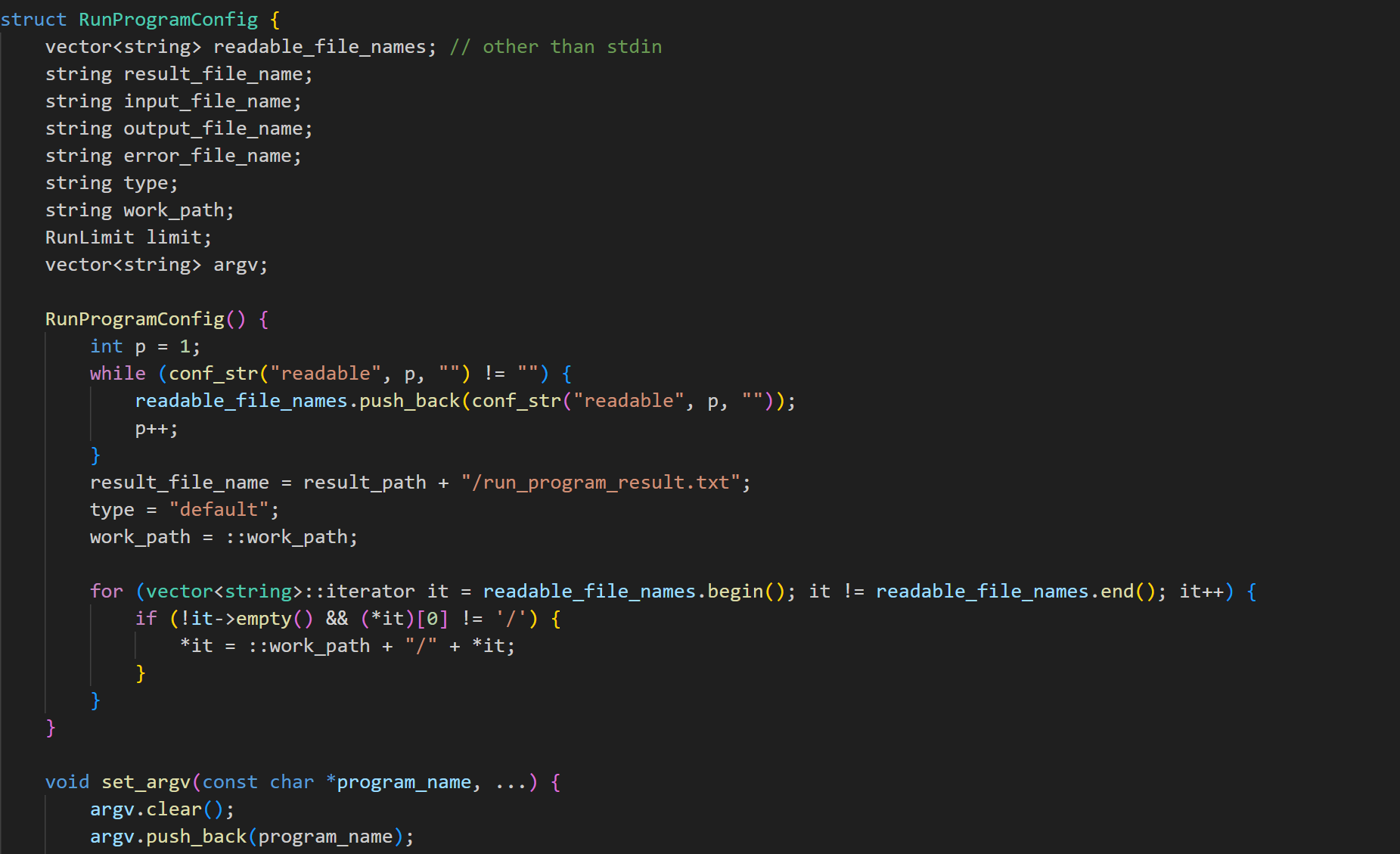
存储运行程序的配置参数,包括:
-
时间、内存、输出、堆栈限制。
-
输入、输出、错误文件名。
-
工作路径、程序类型、可读/可写文件列表。
-
是否允许使用进程、是否启用安全模式、是否显示详细跟踪信息。
-
time_limit, real_time_limit, memory_limit, output_limit, stack_limit 等选项一方面是题目要求,另一方面也对资源占用做了约束,避免程序占用过多的 CPU 资源从而导致错误。
-
文件方面,通过 extra_readable_files 和 extra_writable_files 选项,指定程序允许读取和写入的文件。
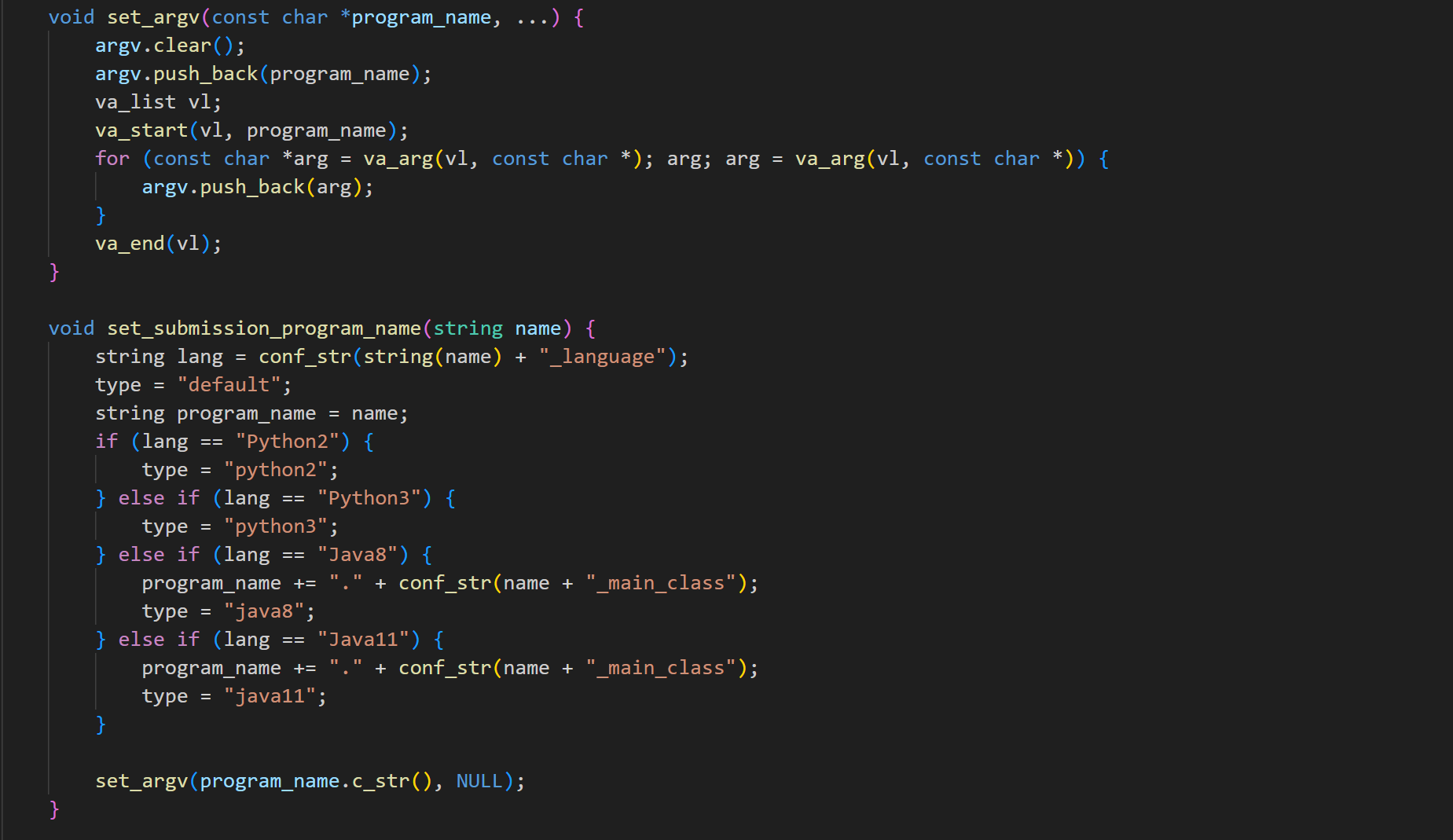
-
safe_mode 选项(默认启用)会检查和限制危险的系统调用,防止程序执行潜在的危险操作(例如修改系统文件、网络操作)。防止了程序随意访问系统中的其他文件。
-
再通过 ptrace 系统调用,可以监控被执行程序的系统调用,拦截和限制危险的系统调用。例如,可以阻止程序执行 fork、exec 等创建新进程的调用。
-
再使用 setrlimit 系统调用设置资源限制,例如 CPU 时间、内存、文件大小等。
-
重定向标准输入输出和错误输出到指定文件,防止程序在标准输出/错误中输出大量数据影响系统。
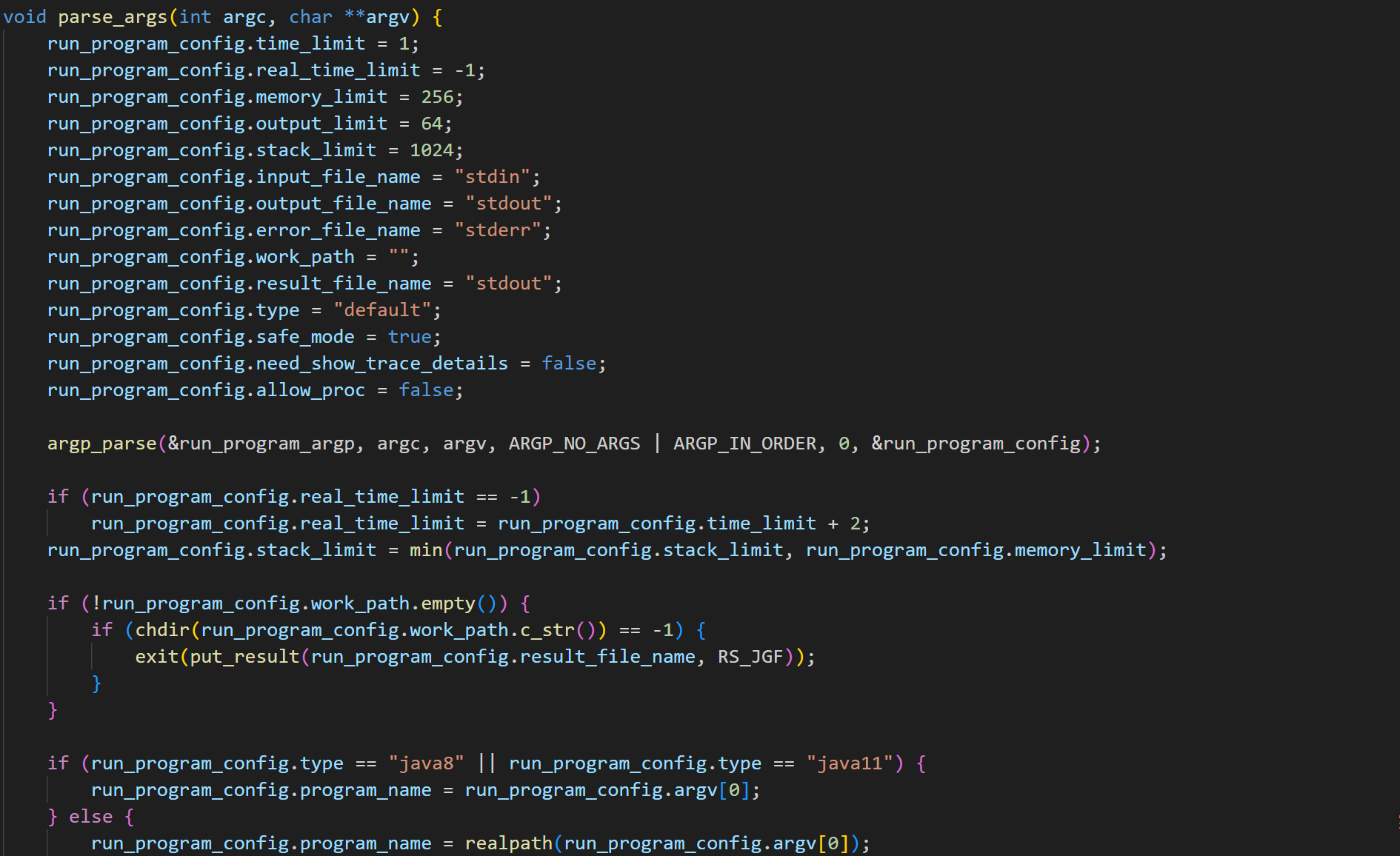
最后评测端的主函数很简洁:
CodeGeeX 的配置
https://modelscope.cn/models/codefuse-ai/CodeFuse-CodeGeeX2-6B
魔塔社区找到 CodeGeeX,绑定阿里云账户,申请免费实例资源

clone 项目

直接安装 requirements.txt,发现出现了版本问题,根据错误信息,问题出在 deepspeed 包的安装过程中,具体是由于 pydantic 的版本不兼容导致的。pydantic 的某些属性在版本 2.x 中发生了变化,而 deepspeed 可能依赖于旧版本的 pydantic。
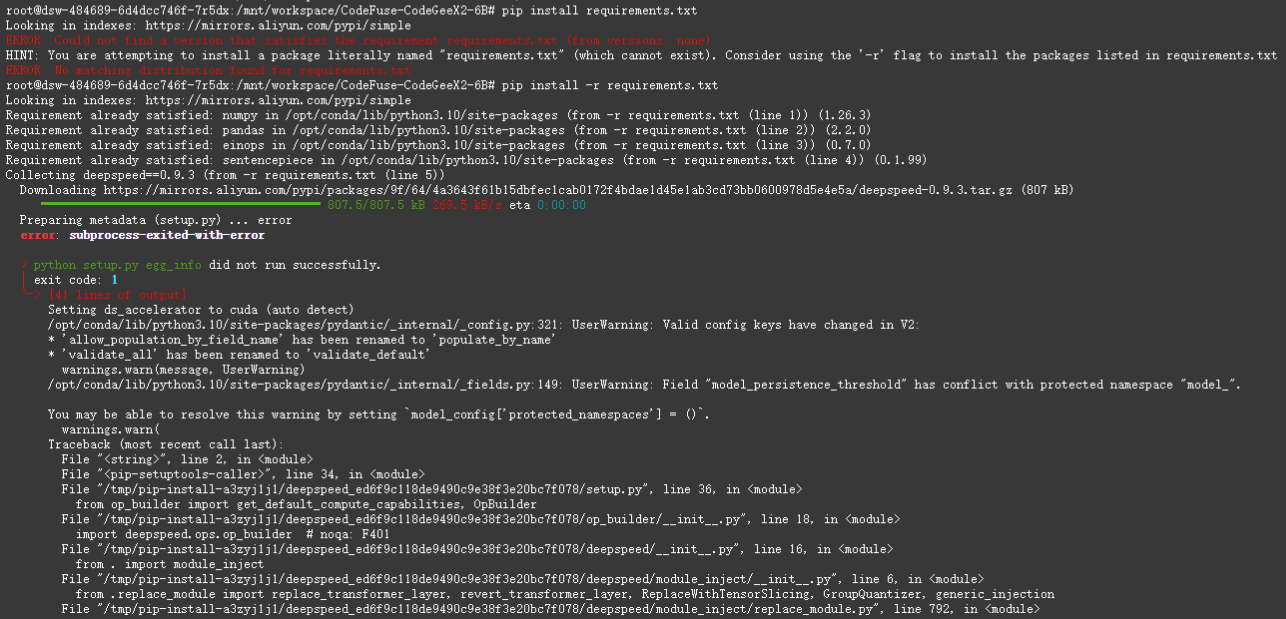
将 deepspeed 改为最新版本,执行 pip install deepspeed -U,解决问题
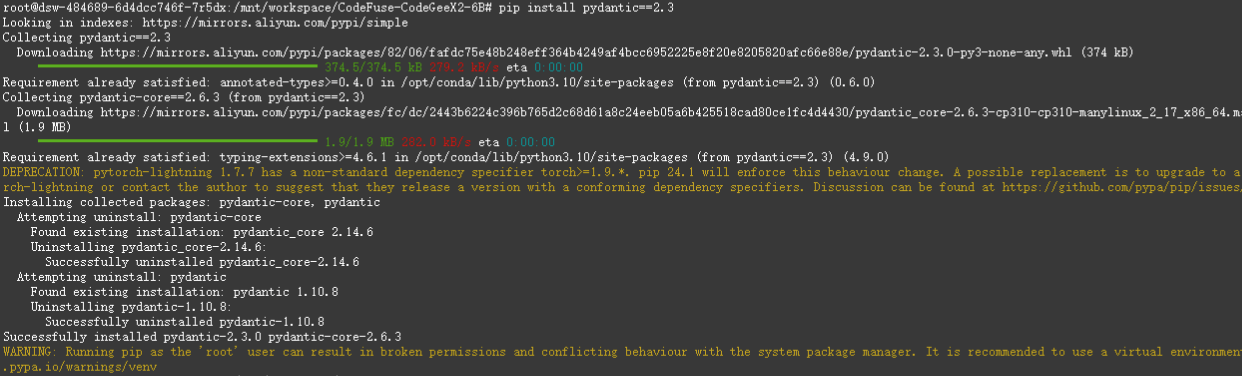
之后安装 requirements.txt,成功
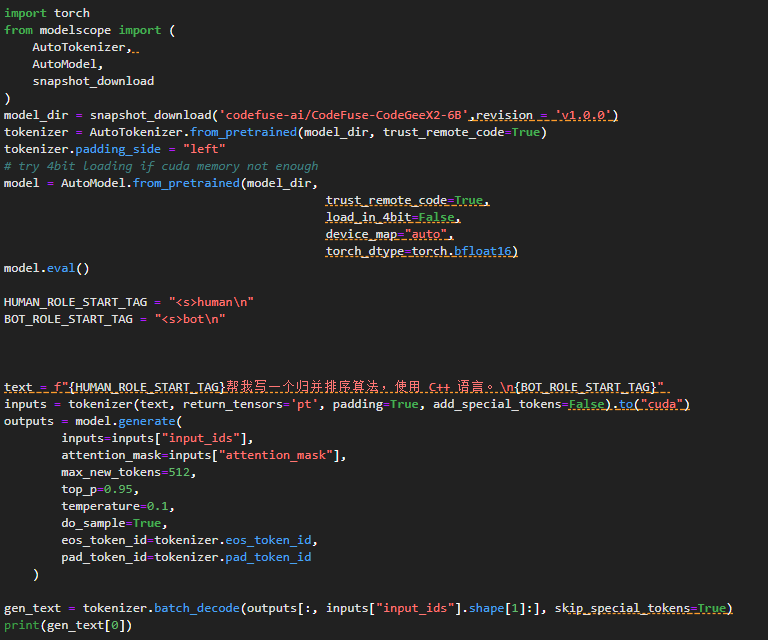
部署完成后进行测试,测试代码为让大模型书写归并排序:
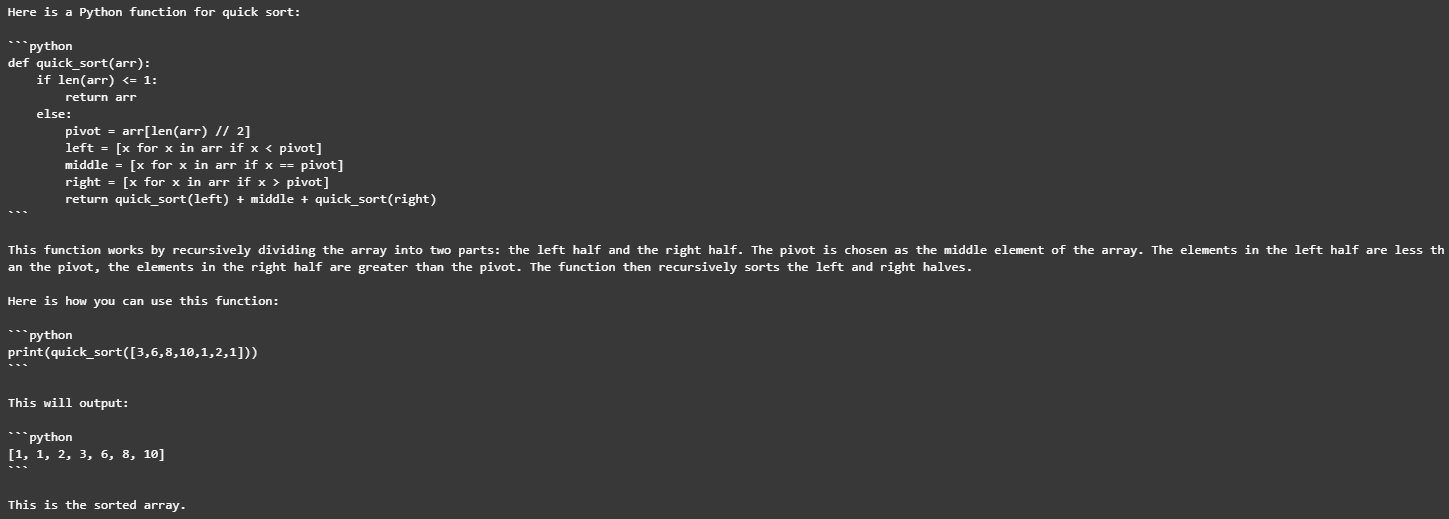
得到的结果:
部署
首先,由于 Modelscope 社区不能持久化存储代码,我们将项目迁移到了自行搭建的阿里云 DSW 服务器上,过程和截图略去。
对 DSW 服务器使用 ssh 连接,再进行端口映射
Promopt-Turning
然后,关于 Promopt-Turning 的学习阅读了文章 https://wjn1996.blog.csdn.net/article/details/120607050,以下是笔记和有效内容:

