

通往高级JAVA开发的必经之路—JVM(二)
前言:
上一篇讲完了JVM的类加载机制,运行时数据区以及版本7与8之间的一些区别。这一篇主要讲讲JDK8的默认的垃圾回收机制(GC)。
开始之前先复习一下JVM的运行时数据区:
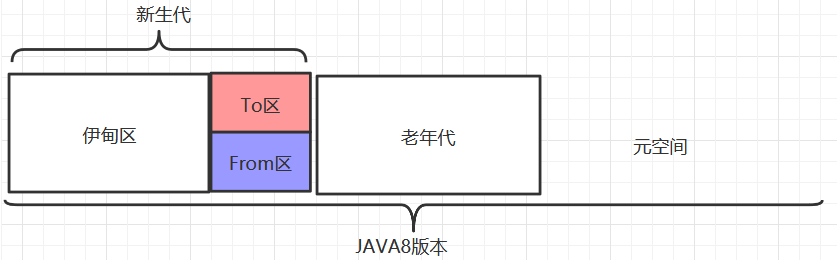
垃圾回收(GC)
概述:
在堆内存中存放着很多new出来的对象,这些对象有些可能非常重要,会一直存在直到系统停止,有些可能用完一次后就不会再用了,朝生夕灭。那么如何合理的分配内存,清理无用的对象。就是垃圾回收机制的作用了。
判断是否无用对象:
堆内存中存放着那么多的对象,JVM是如何识别对象是否有用的?这里就涉及到了JVM的垃圾判断的算法:
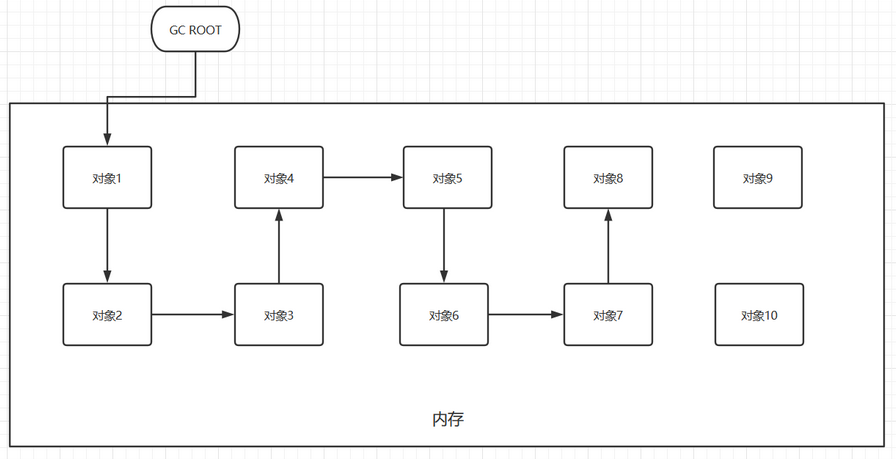
可达性算法:
简单来说就是,JVM会将一个对象作为GC ROOT节点,然后顺着这个节点开始一路引用和搜索,这一路被引用过的对象之间就会产生一条叫引用链的路径,通过对象是否有到达引用链的路径就可以判断对象是否可回收。图中没有引用链路径的对象9与对象10就被认为是可回收的无用对象。
引用计数法:
这个算法因为有无法解决循环引用这一缺陷,所以并不常用,但还是作为储备知识进行一下说明。
原理:给内存中的每一个对象分配一个引用计数器,每当有地方引用该对象时,引用计数器的值加1,当引用失效时,引用计数器的值减1,不管什么时候,只要引用计数器的值等于0了,说明该对象不可能再被使用了。
优点:实现原理简单,而且判定效率很高。理论上应该是一个不错的算法。
缺点:很难解决对象之间相互循环引用的问题,例如:对象A和对象B都有instance字段,并且A.instance=B,并且 B.instance=A,即使这两个对象再无任何其他引用,并且已经不可能再被访问,引用计数器的值也为0了,这两个对象也是不可能再被使用了,此时引用计数器算法也无法通知GC来回收这两个对象。
回收算法:
在使用了可达性算法后,JVM就能成功的判断哪些对象是可以进行回收的,那么JVM又是如何去进行垃圾回收的呢? 根据算法对内存采取的不同操作,可以将垃圾回收的算法分为三种:标记清除,标记复制,标记整理。
一、标记清除算法:
这个算法分为两个阶段,先将所有要进行回收的对象进行标记,然后统一清除所有带有标记的对象。
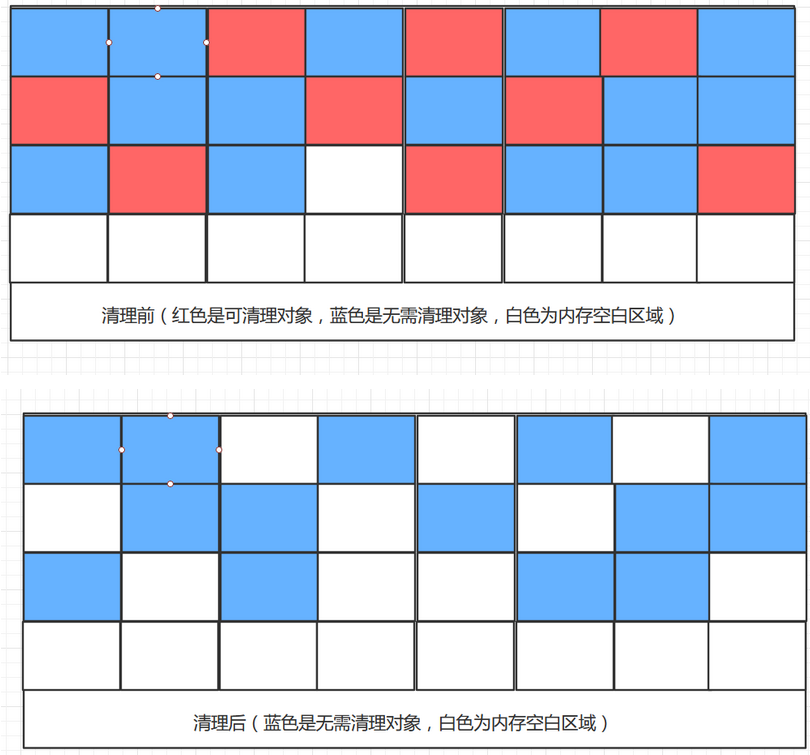
这个算法存在两个缺点:
1、通过上图可以看到进行清理后内存区域并不是连续的,而是产生了许多的内存碎片,然而大对象创建时所分配的内存空间又需要是连续的,这就会导致再一次触发垃圾回收。
2、执行的效率是没有保障的,如果上图中大部分的对象都是可回收的,那么JVM则需要进行大量的标记、清理。
二、标记复制算法:
为了解决标记清除算法的执行效率与内存碎片的缺点,在其基础上诞生了标记复制算法。标记复制算法会将内存直接划分为两个空间,运行空间、预留空间。所有new的对象会被放进运行空间,当运行空间不够用时再将运行空间中所有存活的对象复制进预留空间中,再将运行空间清空。此时两个空间的角色也发生了改变,之前的预留空间成为了现在的运行空间,而之前的运行空间则变成了预留空间待下一次复制时使用。
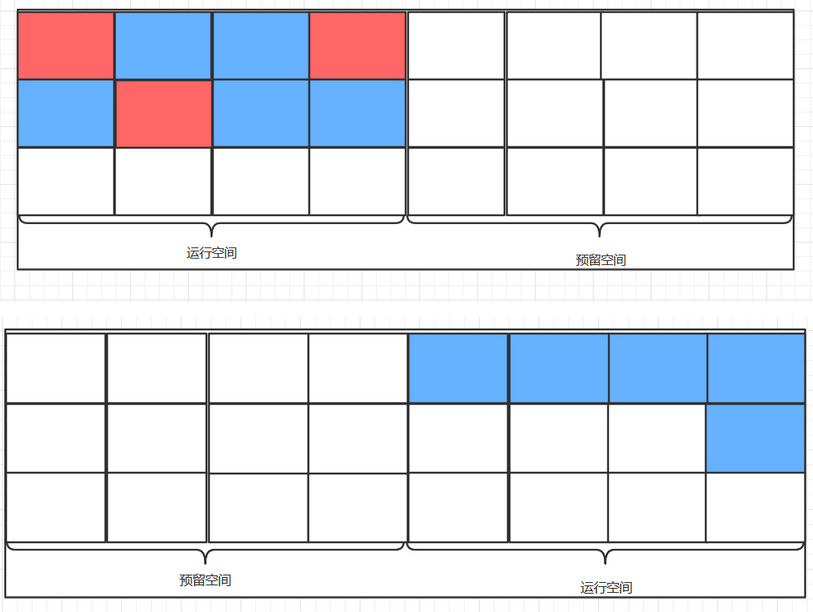
标记复制算法在大量垃圾对象的情况下,只需复制少量的存活对象,并且不会产生内存碎片问题,新内存的分配只需要移动堆顶指针顺序分配即可,很好的兼顾了效率与内存碎片的问题。
但是标记复制算法同样存在着问题,直接预留一半内存区域的操作实在是有些浪费了,而且如果内存中存在大量不需要清理的对象,只有少部分的垃圾对象,JVM要执行多次的复制操作才能释放少量的内存空间,得不偿失。
三、标记整理算法
标记复制算法要浪费一半的内存空间,且存在大量无需回收的对象时效率会很低,针对这一情况又诞生了一种新的算法“标记整理算法”,标记整理算法在标记阶段与上面的两个算法一样,不同之处在于整理阶段,这个算法会将存活下来的对象往内存空间的一端移动,然后将存活对象以外的内存清理掉。
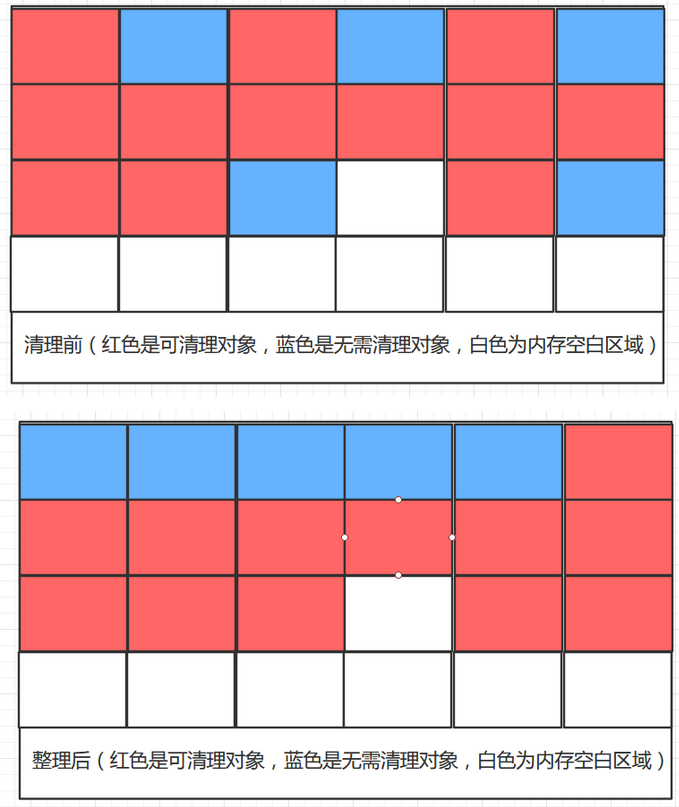

可以看到标记整理算法解决了内存碎片问题,也不存在空间浪费。可是当内存中无需清理的对象过多,且都是一些占用内存不大的小对象。而需要清理的对象少时,就需要进行大量的整理来移动这些无需清理的对象来换取少量的内存空间。
小结:
内存效率:复制算法>标记清除算法>标记整理算法
内存整齐度:复制算法=标记整理算法>标记清除算法
内存利用率:标记整理算法=标记清除算法>复制算法
没有最好的算法,只有最合适的算法。
四、分代收集算法
上面介绍了三种垃圾回收算法,但它们都存在各自的缺点。而当前流行的JVM中所采用的算法都是分代收集算法,这个算法并不是一种新型的算法,而且根据JVM内存中不同的区域来使用不同的垃圾回收算法。
例如在新生代中,每次垃圾收集时都有大量对象需要被回收,只有少量的对象会存活下来。在新生代中就很适合使用复制算法,因为存活的对象少,就不需要进行大量的复制操作,同时回收效率也很高。而在老年代中的对象存活率高,没有额外的空间进行分配担保,而采用标记-清除或者标记-整理算法更合适。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号