

关于XFS文件系统概述
前言: 目前XFS已成为Linux主流的文件系统,所以有必要了解下其数据结构和原理。
XFS文件系统
XFS是一个日志型的文件系统,能在断电以及操作系统崩溃的情况下保证数据的一致性。XFS最早是针对IRIX操作系统开发的,后来移植到linux上,目前CentOS 7已将XFS作为默认的文件系统。使用XFS已成为了潮流,所以很有必要了解下其数据结构和原理。
XFS官方说明文档参考:https://xfs.org/docs/xfsdocs-xml-dev/XFS_Filesystem_Structure//tmp/en-US/html/index.html
接下来将介绍XFS的一些概念,包括分配组、超级块、inode等等,过程中会结合xfs_db(xfs提供的输出文件系统信息的工具)打印一些信息,了解当前XFS的实时数据。
分配组(Allocation Group)
XFS将空间分为若干个分配组,每个分配组大小相等(最后一个可能不等)。分配组包含有超级块、inode管理和剩余空间管理等,所以分配组可以认为是一个单独的文件系统。正是分配组这样的设计,使得XFS拥有了并行IO的能力。在单个分区上使用XFS体现不了这种并行IO能力,但是如果文件系统跨越多个物理硬件比如ceph,并行IO将大大提高吞吐量利用率。
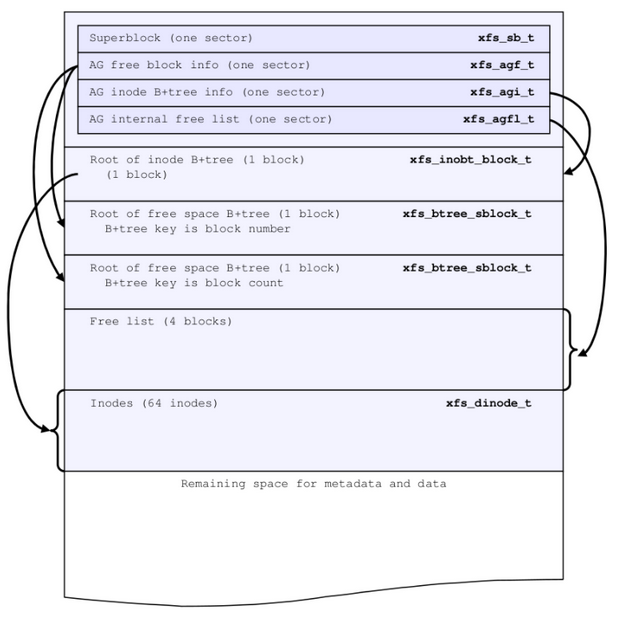
上图为分配组的结构图,重点关注前面4个扇区,从上到下分别为超级块、空闲块信息、inode信息和内部空闲列表。
超级块(superblock)
超级块位于分配组的第一个扇区,包含了分配组和文件系统的全部元数据信息,由于结构体比较大,这里就不作列举,可去官方文档中查看https://xfs.org/docs/xfsdocs-xml-dev/XFS_Filesystem_Structure//tmp/en-US/html/Allocation_Groups.html
xfs_db查看超级块内容,执行xfs_db -r /dev/xxx(xxx为XFS所在的分区),输入sb再输入p即可,如下图所示(鉴于篇幅未尽列出输出):
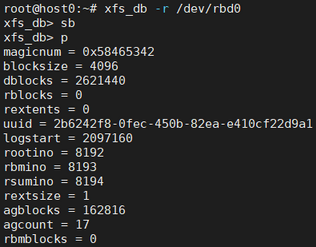
超级块有几个核心的元数据为:
blocksize:块大小,一般为4KB;
dblocks:一个分配组含有的块数目;
agcount:整个文件系统含有的分配组数目;
sectsize:扇区大小,一般为512B;
inodesize:inode节点大小,一般为512B;
icount:整个文件系统目前已经分配的inode数目;
ifree:整个文件系统空闲的inode数目,由于XFS不是格式化的时候预分配所有的inode,而是根据使用情况动态构造inode,所以该值为动态值。
空闲块信息(AG free block info)
位于分配组的第二个扇区,主要描述两个空闲空间B+树和剩余空间信息,结构体如下:
typedef struct xfs_agf {
__be32 agf_magicnum;
__be32 agf_versionnum;
__be32 agf_seqno;
__be32 agf_length;
__be32 agf_roots[XFS_BTNUM_AGF];
__be32 agf_spare0;
__be32 agf_levels[XFS_BTNUM_AGF];
__be32 agf_spare1;
__be32 agf_flfirst;
__be32 agf_fllast;
__be32 agf_flcount;
__be32 agf_freeblks;
__be32 agf_longest;
__be32 agf_btreeblks;
} xfs_agf_t;
核心成员如下:
agf_roots:XFS_BTNUM_AGF为2,指明了2棵空闲空间B+树在哪个block,通过查找这两棵树找到合适的空闲block;
agf_levels:树高;
agf_freeblks:分配组目前空闲block数目
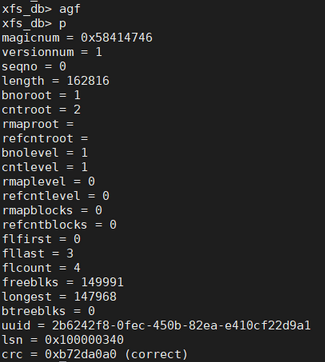
xfs_db输入agf可查看空闲块信息,如下图所示:
空闲空间B+树
空闲块信息包含了两颗空闲空间B+树,分别以block序号和block数目为关键字,满足两种不同的需求。
B+树贯彻了整个XFS,对其有所了解才能更好的理解XFS的运作,网上有很多关于B+树的资料,请自行查阅,这里只描述一些核心概念:
属于多叉平衡排序树;
有m个关键字的中间节点有m个子节点;
m个子节点的关键字集合包含父节点的关键字,B+树有点像跳表;
中间节点只含有关键字不含数据,叶子节点含有所有的关键字和数据;
叶子节点含有左右节点指针,所有叶子节点实际上是一条有序链表。
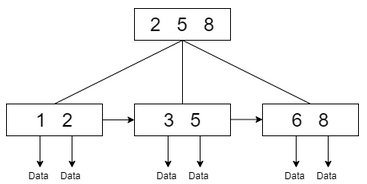
B+树在基于磁盘查找的软件中应用广泛,如数据库,文件系统也一样,这些软件都要读取磁盘数据再查找,所以一次读取尽量多的关键字尤为重要,B+树的单节点多关键字可满足该需求。
接下来将通过xfs_db去探索这两棵树的内容,从agf的打印信息可看到bnoroot=1和cntroot=2,它们分别是以block序号和block数目为关键字的B+树的根节点所在的block序号。
跟踪以block序号为关键字的B+树操作如下:
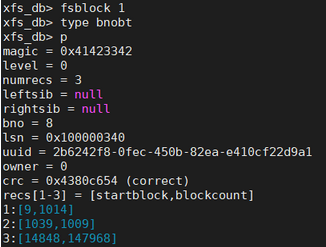
由于agf中level为1,所以该B+树没有中间节点,直接就是叶子节点,包含有空闲block数据,图中的recs数组便是,可见目前有3大块空闲空间。
跟踪以block数目为关键字的B+树操作如下:
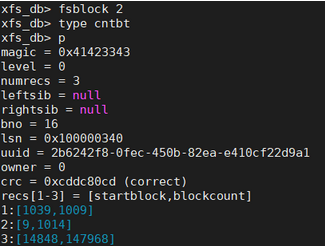
Inode B+树信息
位于分配组的第三个扇区,主要描述inode B+树的根block、已构造的inode个数以及空闲个数,数据结构如下:
typedef struct xfs_agi {
__be32 agi_magicnum;
__be32 agi_versionnum;
__be32 agi_seqno
__be32 agi_length;
__be32 agi_count;
__be32 agi_root;
__be32 agi_level;
__be32 agi_freecount;
__be32 agi_newino;
__be32 agi_dirino;
__be32 agi_unlinked[64];
} xfs_agi_t;
核心成员如下:
agi_root:inode B+树的根block;
agi_level:树高;
agi_count:已构造的inode数目;
agi_freecount:空闲的inode数目。
xfs_db输入agi可读取到Inode B+树信息,如下图所示:
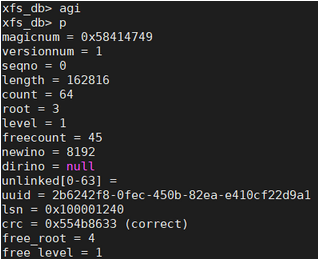
由上图可知B+树的根block为root=3,跟踪该block便可找到具体的inode数据。
Inode信息
每一个文件或目录都对应一个inode,用于描述文件的基本信息,除了目录或链接,inode不携带文件数据。
inode分为3部分,如下;

xfs_dinode_core_t:固定信息,描述文件类型、属性、访问时间等;
data fork:存放数据位置信息;
extended attribute fork:存放扩展数据位置信息;
Inode Core
描述文件的基本信息,数据结构定义如下:
typedef struct xfs_dinode_core {
__uint16_t di_magic; /* inode magic # = XFS_DINODE_MAGIC */
__uint16_t di_mode; /* mode and type of file */
__int8_t di_version; /* inode version */
__int8_t di_format; /* format of di_c data */
__uint16_t di_onlink; /* old number of links to file */
__uint32_t di_uid; /* owner's user id */
__uint32_t di_gid; /* owner's group id */
__uint32_t di_nlink; /* number of links to file */
__uint16_t di_projid; /* owner's project id */
__uint8_t di_pad[8]; /* unused, zeroed space */
__uint16_t di_flushiter; /* incremented on flush */
xfs_timestamp_t di_atime; /* time last accessed */
xfs_timestamp_t di_mtime; /* time last modified */
xfs_timestamp_t di_ctime; /* time created/inode modified */
xfs_fsize_t di_size; /* number of bytes in file */
xfs_drfsbno_t di_nblocks; /* # of direct & btree blocks used */
xfs_extlen_t di_extsize; /* basic/minimum extent size for file */
xfs_extnum_t di_nextents; /* number of extents in data fork */
xfs_aextnum_t di_anextents; /* number of extents in attribute fork*/
__uint8_t di_forkoff; /* attr fork offs, <<3 for 64b align */
__int8_t di_aformat; /* format of attr fork's data */
__uint32_t di_dmevmask; /* DMIG event mask */
__uint16_t di_dmstate; /* DMIG state info */
__uint16_t di_flags; /* random flags, XFS_DIFLAG_... */
__uint32_t di_gen; /* generation number */
} xfs_dinode_core_t;
核心成员如下:
di_mode:指定文件类型和访问权限,具体解析参考https://www.xuebuyuan.com/1106749.html
di_format:指定data fork的数据格式,有以下类型:
typedef enum xfs_dinode_fmt {
XFS_DINODE_FMT_DEV, // 用于字符和块设备
XFS_DINODE_FMT_LOCAL, // 用于目录和链接,表明数据就存放在inode的data fork中
XFS_DINODE_FMT_EXTENTS, // data fork存放extent,extent指向具体的block,block存放数据
XFS_DINODE_FMT_BTREE, // data fork存放B+树根block
XFS_DINODE_FMT_UUID // 该值不再使用,忽略
} xfs_dinode_fmt_t;
di_uid:拥有者id;
di_gid:拥有者的组id;
di_atime、di_mtime、di_ctime:访问时间、修改时间、修改属性时间;
di_size:数据大小,比如文件的大小;
di_forkoff:实际值要乘以8,是data fork和extended attribute fork的分界线,以data fork为起始,初始值为0,代表没有extend attribute fork。
Inode number
Inode有个唯一表明身份的number,有两种格式:相对格式(32位)和绝对格式(64位)。

从上图可见,绝对格式比相对格式多了AG number部分,中间部分为block序号,右侧部分为inode在该block内的序号,可见根据inode number便可得到inode在磁盘的具体位置。sb_agblklog和sb_inoplog的值位于超级块中。
计算inode所在位置方法:
假设block序号为A,inode序号为B,AG number为C,每个分配组的block数目为D,Inode大小为E,block大小为F(这些值可以计算或通过超级块得到)
则inode所在的block序号 x = C D + A,则inode地址为 y = x F + E * B
data fork
不同文件类型的data fork形式有所不同,同样类型的文件根据大小也会有不同的数据结构,接下来将一一描述。
普通文件
普通文件的数据不会放在data fork中,视extent数目大小,有两种数据形式:
Extent List:每个extent指明存放数据的block地址,遍历该list便可得到全部文件数据;
B+tree Extent List:由于data fork的容量有限,如果extent数量太多,将采用B+树的形式存放extent,亦即采用额外的block存放extent。
目录
有四种形式的目录:
Shortform目录:目录下文件不多或者文件名短,也就是data fork能容纳下文件名和文件inode,则目录的数据放在data fork中;
Block目录:data fork存放不下目录的内容,采用额外的一个block存放;
Leaf目录:一个block存放不下目录的内容,把索引信息从block中抽离,索引信息用额外一个block存放;
Node目录:一个block存放不下索引信息,采用多个block存放索引信息;
B+树目录:data fork已经存放不下数据block extent,采用B+树方式存放block extent。
链接
有两种形式的链接:
Shortform链接:data fork能存放下链接的内容,内容即目标文件的路径;
Extent链接:采用额外的block存放链接的内容,extent存放block信息。
结束语
以上就是XFS文件系统的一些基本数据结构,了解了基本的数据结构使我们能更深入的了解和探索XFS系统,当系统出现问题时也可以更好地分析原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号