在游戏中充分利用可编程的GPU
我充分意识到GPU海量的吞吐和强悍的浮点计算能力,将极高提高程序性能,也能让充分发挥显卡的价值,GPU作为电脑上2个可编程的高性能芯片之一,长期以来都没得到普通程序员应有的重视,主要因为其编程麻烦,资料工具欠缺。这里我将叙述我的游戏编程中尽可能多的使用GPU做事的一些经验,主要是想表达一种合理使用计算机资源的一种思想吧。
我对DX10和SM3.0都不熟悉,所以更有用的GS数据输出,甚至于更强大的CUDA都不在本文叙述范围之内,这里更多讨论SM2.0和DX9,相信大部分朋友都应该具备实践的条件。专业的GPGPU都利用科学计算作为实例,我觉得不妥,还是简单点好,在这里我说说如何将公告板的所有几何计算都放到GPU里去。
公告板对于图形程序员都再熟悉不过,就是让几何体(通常是四边形)总是面对相机,其实就是一个旋转过程,最简单的就是雪花,草丛等等,在这里我要讲一个稍微复杂点的例子,比如魔兽中的锁链魔法,或者天空中的分形闪电,其实这些都是链接在2个点之间的一条或多条几何体面片,一段可能是一个四边形,也可能是多个四边形,如下图:
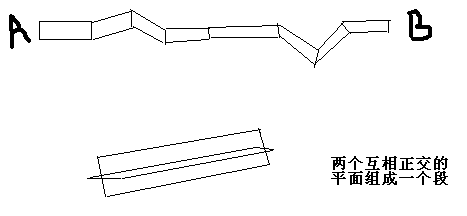
如果一段不是一个面片就用不着旋转了,所以我们主要说上面那种情况。法师对一个或多个目标发送带链接的魔法,其实就是在目标之间生成链接的面片,并且面片上进行相关的纹理动画,当目标之间方位不断改变时还要进行几何变换等操作。原理很简单,就是让所有面片都能面对观众,这样在特定方向观看时才不会有严重失真的表现,我们主要看如何把所有计算都塞到GPU中去。

首先我们必须在CPU中生成所有需要的顶点,因为没有GS的GPU不能生成顶点。比如我们要从A点生成一条几何条带到B点,我们生成8个中间点,共10个点。通过相邻的2个点,我们可以求出2个点的中间点,Pmid= (Pi + Pi+1) / 2,我们为第一个段生成4个顶点,后续的段因为共用前一个段的后2个顶点,所以后面的每段只需要2个顶点,每个顶点的几何坐标设置为本段的中间点坐标Pmid,这样每个段的顶点都是窝在一起的,我们需要在VS里将其扩展成四边形,但我们需要信息,当前顶点该如何扩展,如下图:
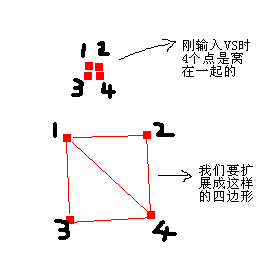
我们可以用UV坐标做标识,UV坐标y分量为0的都向后扩展,y分量!=0的都向前扩展,而x==0的向左,x==1的向右。因为一般的锁链上的纹理都是U向CLAMP,V向WRAP的,所以UV正好给我们提供了如何扩展几何体的信息,但扩展多少呢?我们需要再利用一个数据流送入信息,我们就利用TEXCOORD1吧,X方向和Y方向扩展数量正好用2个FLOAT送入。之后是旋转,其实就是扩展,我们需要2个轴,一个是X方向的,一个是Y方向的,Y方向的其实就是LeashY = Pi+1 - Pi,至于原理就是公告板旋转,只是约束轴不同,而X方向LeashX = Cross( LeashY, (CameraPos - VertexPos) ),所以我们还需要一个流送入LeashY,而LeashX可以通过顶点原始坐标和LeashY在VS中计算出来,不用在CPU里做。所以唯一要在CPU里做的就是生成顶点和UV,而这2个计算量非常小,顶点真实坐标的计算,公告板的旋转等都放到VS里来了。现在我们看看VS大概是什么样子。
float3 g_CameraPos;
float4x4 g_WorldMatrix;
float4x4 g_ViewProjMatrix;
struct VS_INPUT
{
float3 VertexPos : POSITION0;
float2 UV0 : TEXCOORD0;
float3 LeashY : TEXCOORD1;
float2 Size : TEXCOORD2;
};
struct VS_OUTPUT
{
float3 ProjPos : POSITION0;
float2 UV0 : TEXCOORD0;
};
VS_OUTPUT VS_Main( VS_INPUT In )
{
VS_OUTPUT Out;
float4 VertexWorldPos = mul(float4(In.VertexPos, 1.f), g_WorldMatrix);
float3x3 WorldRotateMatrix;
WorldRotateMatrix[0] = float3(g_WorldMatrix[0][0], g_WorldMatrix[0][1], g_WorldMatrix[0][2]);
WorldRotateMatrix[1] = float3(g_WorldMatrix[1][0], g_WorldMatrix[1][1], g_WorldMatrix[1][2]);
WorldRotateMatrix[2] = float3(g_WorldMatrix[2][0], g_WorldMatrix[2][1], g_WorldMatrix[2][2]);
//注意旋转轴需要被旋转否则不对
float3 RotatedLeashY = normalize(mul(In.LeashY, WorldRotateMatrix ));
float3 LeashX = normalize(cross(g_CameraPos-VertexWorldPos, RotatedLeashY));
//开始旋转了
float3 DealedPos = float3(0,0,0);
float3 ExtendY = In.Size.y*RotatedLeashY;
float3 ExtendX = In.Size.x*LeashX;
if(In.UV0.y == 0 )
{
if(In.UV0.x == 0 )
{
DealedPos = -ExtendY-ExtendX;
} else {
DealedPos = -ExtendY+ExtendX;
}
} else {
if(In.UV0.x == 0 )
{
DealedPos = ExtendY-ExtendX;
} else {
DealedPos = ExtendY+ExtendX;
}
}
Out.ProjPos = mul(float4(VertexWorldPos.xyz+DealedPos, 1.0f), g_ViewProjMatrix);
Out.UV0 = In.UV0;
}
怎么样?CPU既不用计算顶点坐标,又不用旋转公告板,做一些改进后,甚至可以完成锁链的拉伸变形,完全不用CPU管。在可编程的GPU出现以前,很多计算工作是在CPU中完成,现在有了SM2.0和SM3.0都可以移植到GPU中来,大家多多发现吧。
最后再次向亲爱的咪宝道歉!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号