

环境:windows10 ,Python 3.5.2
安装教程到处都是,不做赘述,爬虫实现股票分析(一)只讲解了怎么去东方财富网爬取下来6开头股票的信息(包括历史信息)
知识点:正则表达式,python简单语法,东方财富网相关结构
实测实现代码:
#导入需要使用到的模块
import urllib
import urllib.request
import re
import os
#爬虫抓取网页函数
def getHtml(url):
html = urllib.request.urlopen(url).read()
html = html.decode('gbk')
return html
#获取所有的股票编号,正则表达式带()时,返回值只包含括号里内容,即股票编号数组
def getStackCode(html):
s = r'<li><a target="_blank" href="http://quote.eastmoney.com/\S\S(.*?).html">'
pat = re.compile(s)
code = pat.findall(html)
return code
Url = 'http://quote.eastmoney.com/stocklist.html'#东方财富网股票网址
filepath = 'D:\\data\\python\\stock\\'#定义数据文件保存路径
#进行抓取
code = getStackCode(getHtml(Url))
#获取所有以6开头的股票代码的集合
CodeList = []
for item in code:
if item[0]=='6':
CodeList.append(item)
#将网页上文件下载并保存到本地csv文件,注意日期
for code in CodeList:
print('正在获取股票%s数据'%code)
url = 'http://quotes.money.163.com/service/chddata.html?code=0'+code+\
'&end=20190228&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath+code+'.csv')
注意点:
1.findall 使用正则表达式,并且正则表达式带()时,返回值只包含括号里内容,即股票编号数组
2.一定要import urllib.request,只import urllib不行
3.filepath = 'D:\\data\\python\\stock\\' 的 filepath 目录要存在,不然就用下面的形式:
if not os.path.exists(file_path):
os.mkdir(file_path)
最终执行就可以实现股票的历史信息了,大概如下:
具体内容如下:
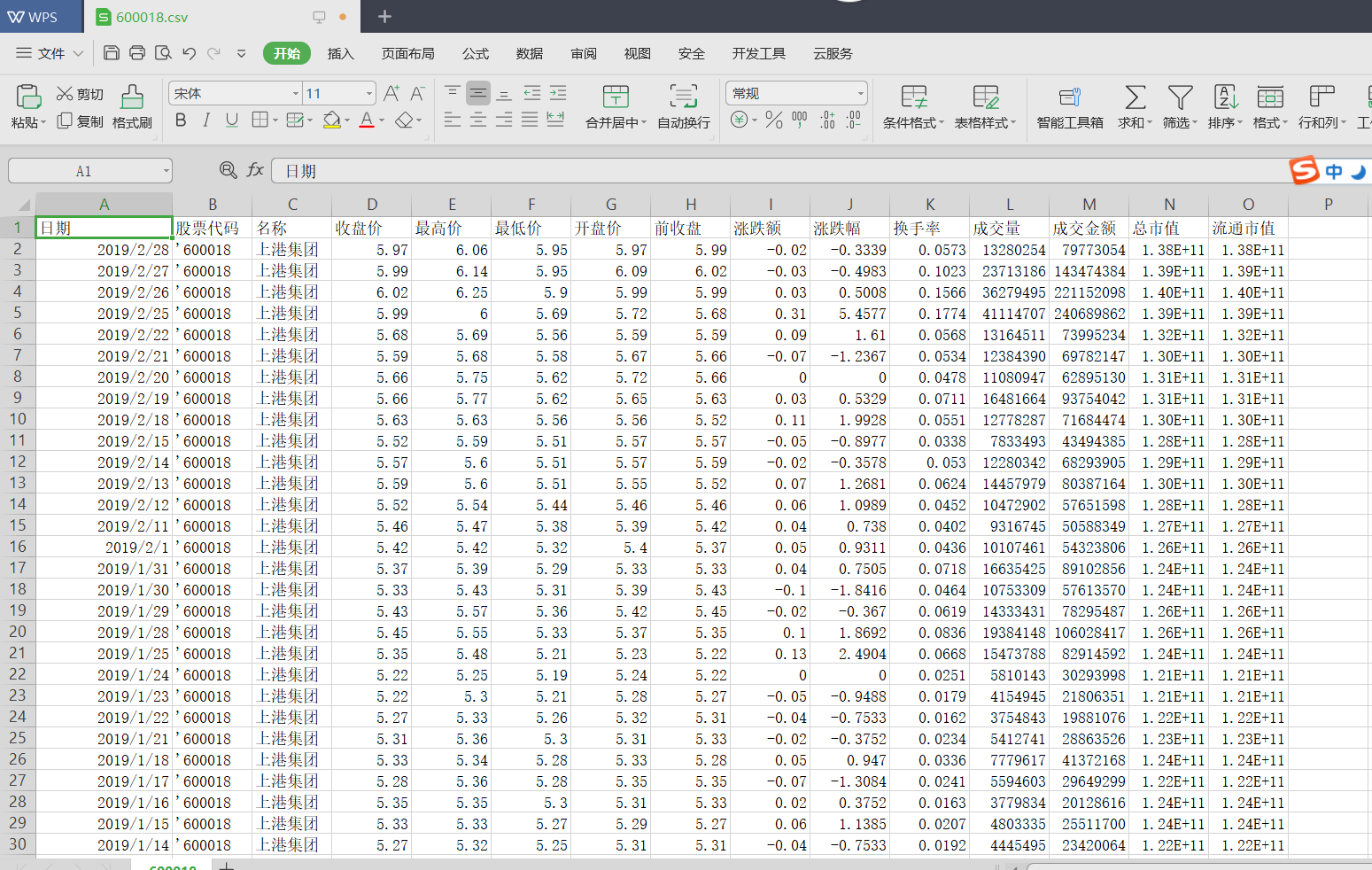
是不是很神奇,短短几行代码实现如此强大的功能,是不是有了很强的学习动力

