

注意力机制分为:通道注意力机制, 空间注意力机制, 通道_空间注意力机制, 自注意力机制
参考:
https://blog.csdn.net/weixin_44791964/article/details/121371986
通道注意力机制
SENet
其重点是获得输入进来的特征层中每一个通道的权值。
其具体实现方式就是:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
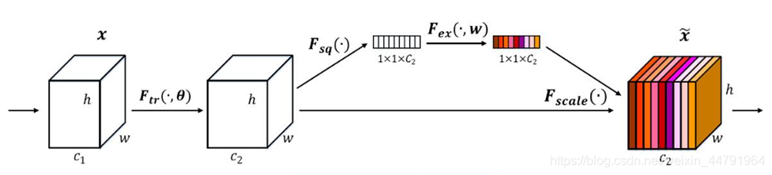
核心思想:将全局平均池化作为通道要学习的注意力分数
import torch
import torch.nn as nn
import math
class se_block(nn.Module):
def __init__(self, channel, ratio=16):
super(se_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
ECANet
ECANet可以看作是SENet的改进版
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
1D卷积就不单单只考虑一个通道的分数了, 而是考虑1D卷积核大小的通道个数。1D卷积见:一维卷积tensorflow2版本的Conv1D以及PyTorch的nn.Conv1d用法 - 知乎 (zhihu.com)

def __init__(self, channel, b=1, gamma=2):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
空间注意力机制
像素级空间注意力
核心:通过像素注意力块对高关联通道特征图上所有像素进行打分, 主要是通过卷积层,将通道映射到1个通道,实现像素注意力打分

通道_空间注意力机制
CBAMNet
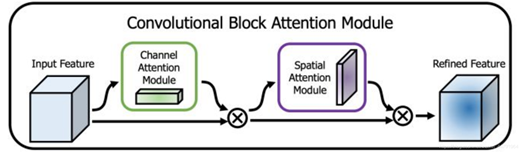
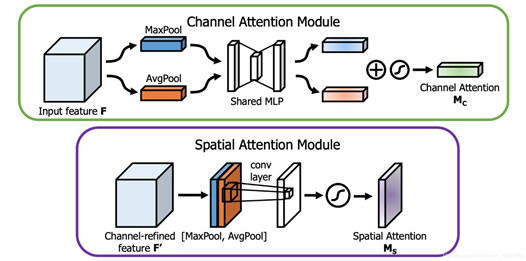
核心思想:通道注意力机制将全局平均池化和全局最大池化作为通道要学习的注意力分数
空间注意力机制:在通道上求每一个像素点的平均值和最大值作为空间注意力
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
avg_out = torch.mean(x, dim=1, keepdim=True) # 通道上求每一个像素点的平均
max_out, _ = torch.max(x, dim=1, keepdim=True) # 通道上求每一个像素点的最大值
x = torch.cat([avg_out, max_out], dim=1)
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
x = x * self.channelattention(x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号