mysql兼容emoji表情存取
emoji介绍
Emoji (絵文字,词义来自日语えもじ,e-moji,moji在日语中的含义是字符)是一套起源于日本的12x12像素表情符号,由栗田穣崇(Shigetaka Kurit)创作,最早在日本网络及手机用户中流行,自苹果公司发布的iOS 5输入法中加入了emoji后,这种表情符号开始席卷全球,目前emoji已被大多数现代计算机系统所兼容的Unicode编码采纳,普遍应用于各种手机短信和社交网络中。近期,更是有不少网友用emoji图案玩猜字游戏,享受这种表情文化带来的乐趣。
关于emoji的发音:很多人第一眼见到emoji便会下意识将其误读作“一磨叽”,其实不然,emoji音译过来大概读作“诶磨叽”,当中“e”的发音颇似字母abc的a的发音。
最初日本的三大电信运营商各自有不同的字符定义,分别是DoCoMo、KDDI和Softbank。随着iOS内置了Softbank的版本,emoji在全球范围内风靡(iOS5版本以前)。而Google又自己定义了一套emoji字符。iOS5以后,apple采用了unicode定义的emoji字符(iOS5版本以后)。
unicode定义的emoji是四个字符,softbank为3个字符,emoji的四个字符从存储到展示对应没有做过考虑的系统来说,简直就是灾难。
面临问题:
插入Emoji表情,保存到数据库时报错:
SQLException: Incorrect string value: '\xF0\x9F\x98\x84' for column 'review' at row 1
UTF-8编码有可能是两个、三个、四个字节。Emoji表情是4个字节,而Mysql的utf8编码最多3个字节,所以数据插不进去。
解决方案:过滤解决
把emoji直接过滤掉,简单方便有效。虽然损失了几个emoji字符,但强过不至于导致整条记录丢失。
public static String removeNonBmpUnicode(String str) { if (str == null) { return null; } str = str.replaceAll("[^\\u0000-\\uFFFF]", ""); return str; }
这种方案能预防能解决问题,并且还能是程序更加健壮,但是从用户体验上来说并不好,用户发的emoji表情丢了,看下面的解决方案。
解决方案:将Mysql的编码从utf8转换成utf8mb4。
从 MySQL 5.5.3 开始,MySQL 支持一种 utf8mb4 的字符集,这个字符集能够支持 4 字节的 UTF8 编码的字符。 utf8mb4 字符集能够完美地向下兼容 utf8 字符串。在数据存储方面,当一个普通中文字符存入数据库时仍然占用 3 个字节,在存入一个 Unified Emoji 表情的时候,它会自动占用 4 个字节。所以在输入输出时都不会存在乱码的问题了。
要使用 MySQL 的这个特性,首先需要把 MySQL 升级到 5.5.3 以上的版本。
其次,需要修改数据结构中的字符集为 utf8mb4 ,如 utf8mb4_general_ci 。
最后修改数据库连接字符串默认字符集为utf8mb4。
由于 utf8mb4 是 utf8 的超集,从 utf8 升级到 utf8mb4 不会有任何问题,直接升级即可;如果从别的字符集如 gb2312 或者 gbk 转化而来,一定要先备份数据库。
详细步骤如下:
1修改mysql数据库字符集(以windows系统为例)
运行services.msc,找到mysql服务,右键查看属性,在可执行文件路径中找到mysql配置文件位置并打开my.ini配置文件。
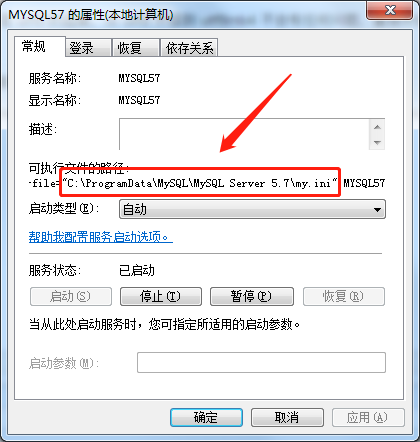
共有两处修改
[mysql] --->> default-character-set=utf8mb4
[mysqld] --->> character-set-server=utf8mb4
如下图

2修改数据库连接字符串Charset=utf8mb4
<add name="Default" connectionString="Data Source=****;port=****;Initial Catalog=****;uid=****;password=****;Charset=utf8mb4;Allow User Variables=True" providerName="MySql.Data.MySqlClient" />
3修改完成
这种方式可能带来的问题:
存储:在数据表中,对于变长的字段(如VARCHAR2,TEXT),utf8mb4最大可存储的字符可能少于utf8系列的collation;在索引中,对于文本类型的字段,utf8mb4可索引的字符少于utf8系列的collations。如InnoDB的索引最多使用767字节。如果使用utf8mb4,每一个字符都会预留4字节做索引,而utf8则预留3字节。故此前者是191个字符,后者是255个字符。。
性能:由于以上原因,加上字符集大,utf8mb4的性能可能比utf8系列的collations低,可以参考stackoverfolow上的一个测试结果:http://stackoverflow.com/questions/766809/whats-the-difference-between-utf8-general-ci-and-utf8-unicode-ci,差异不是特别大。
运维:如果一个大的环境内,如果其他的数据库都是utf8模式,把其中某个库设置为utf8mb4模式,在后续交接运维可能会造成问题,遗留下坑。
上下游:数据库支持unicode的emoji存储,上下游不一定支持。比如mysql客户端驱动(低版本的jdbc就不行)可能不支持utf8mb4,或者DDL的中间件不支持utf8mb4。web端处理utf8mb4字符展示,这些都有可能影响emoji的存储活着展示。
参考资料:https://blog.csdn.net/ugg/article/details/44225723

 浙公网安备 33010602011771号
浙公网安备 33010602011771号