从JDK8升级到JDK17:探索JAVA的新特性和改进
升级到JDK17的必要性
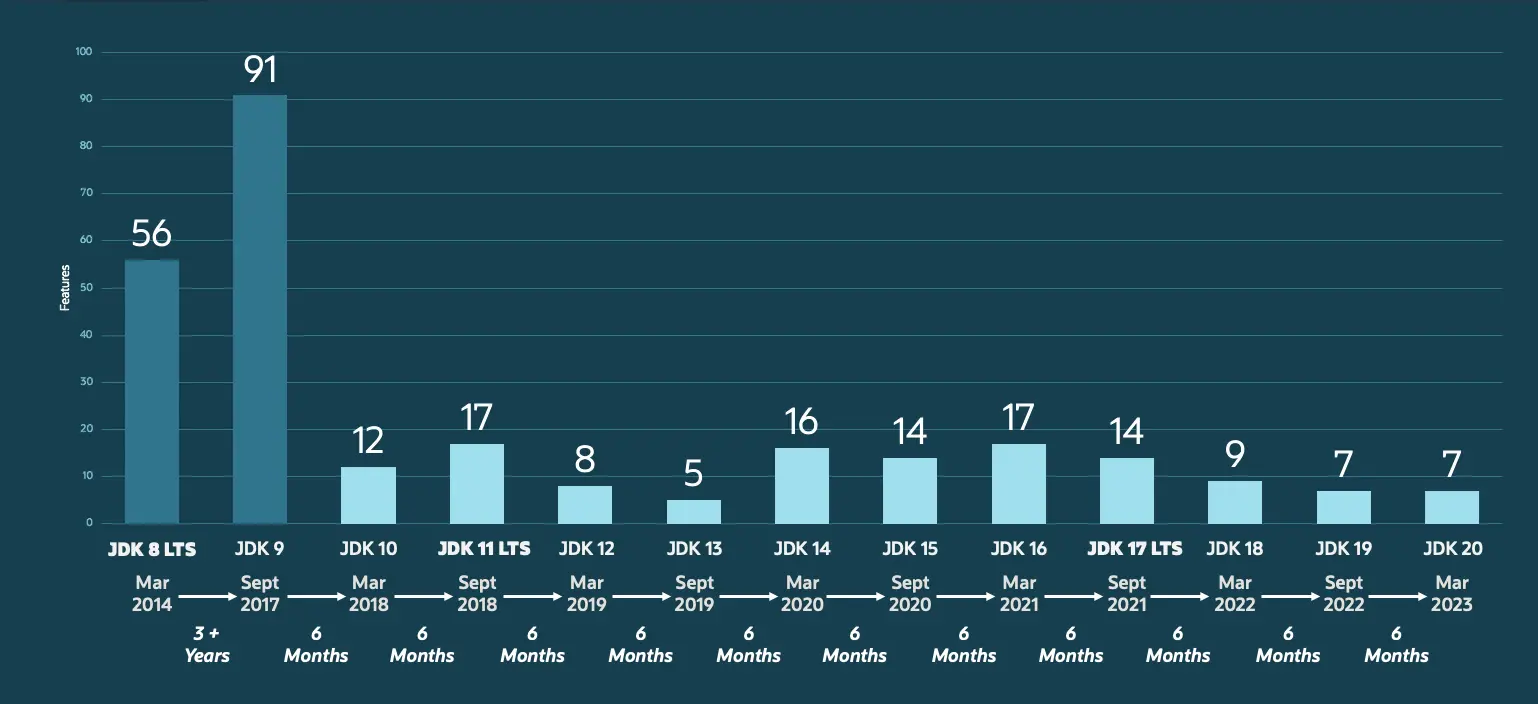
JDK8提供了很多实用且常用的特性,例如lambda表达式等,再加上超长的支持时间(JDK8支持到2030年,比JDK11的2026年和JDK17的2029年都要长)。而从JDK9往后,JDK的发布周期也缩短为6个月,也间接导致每个版本的新特性相对较少,大家的对新特性的提升感知不强,所以升级欲望不是很强烈,所以就出现了“你发任你发,我用JAVA8”的现象
但是随着时间的推移,相关技术发展迭代,我们也有了不得不升级的理由:
- JDK17性能提升:无需对代码做任何优化,只需升级且让适配JDK17,你的程序就会因JDK底层技术的更新而获得相应的性能提升
- JDK8之后语法新特性:JDK9到JDK17新特性能够使我们开发的代码更加简洁和健壮
- JDK17是商业免费的LTS版本:LTS(
long-term support)长期支持 - 生态框架版本升级:例如
Spring6.0&Spring Boot3.0支持的最小版本是JDK17
新语言特性
本地变量类型var
**类型推断**是很多编程语言都具有的特性,编译器可以在我们不指定具体变量类型的时候**根据上下文推断**出该变量的实际类型。类型推断可以使我们的程序更加灵活更加简洁
首先我们先来看一下JDK8和之前的版本中类型推断的用处:
// JDK7引入的Diamond操作符
List<Integer> roleTypes = new ArrayList<>();
// JDK8引入的lambda表达式
List<Integer> filterList = roleTypes.stream().filter(roleType -> roleType.equals(1))
.toList();
// 泛型方法调用,编译器可以根据参数的类型推断出泛型的类型
public <T> T identity(T value) {
return value;
}
String result = identity("Hello, Java!");
var关键字的使用:如何在代码中使用var来减少冗余的类型声明
在JDK10以及更高的版本中,我们可以使用var标识符来声明初始化之后的局部变量,例如下面这段代码:
URL url = new URL("http://www.oracle.com/");
URLConnection conn = url.openConnection();
Reader reader = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
在JDK10之后我们可以这样写:
var url = new URL("http://www.oracle.com/");
var conn = url.openConnection();
var reader = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
var可用于以下类型的变量:
- 设置了初始值的局部变量
var list = new ArrayList<String>(); // infers ArrayList<String>
var stream = list.stream(); // infers Stream<String>
for (var counter = 0; counter < 10; counter++) {...} // infers int
var name; // 提示:Cannot infer type: 'var' on variable without initializer
- 增强for循环索引
List<String> list = Arrays.asList("a", "b", "c");
for (var element : list) {...} // infers String
总结
- 因为
var类型变量是在编译时期进行的类型推断,所以var不会影响性能 var关键字提高了代码的简洁性,但是降低了代码的可读性和可维护性。所以我们在使用var关键字的时候要严格遵守命名规范和将局部变量的作用域尽可能最小化
record类:简化数据类的创建和使用record类
record:记录,档案
record类的定义是用来表示不可变数据的透明载体
我们先看一下record类的定义格式:
public record RecordDemo(String name, Integer age) {
}
对RecordDemo.class进行反编译得到以下结果:
public final class RecordDemo extends Record {
private final String name;
private final Integer age;
public RecordDemo(String name, Integer age) {
this.name = name;
this.age = age;
}
/**
* 先拼接[+类名称, 之后循环拼接field 名称=值, 最后以]结尾
*/
public final String toString() {
// Byte code:
// 0: aload_0
// 1: <illegal opcode> toString : (Lcom/d17emo/demo/RecordDemo;)Ljava/lang/String;
// 6: areturn
// Line number table:
// Java source line number -> byte code offset
// #3 -> 0
// Local variable table:
// start length slot name descriptor
// 0 7 0 this Lcom/d17emo/demo/RecordDemo;
}
/**
* 对于每一个field, 使用对应的hashCode()方法取出哈希值拼接到一起
*/
public final int hashCode() {
// Byte code:
// 0: aload_0
// 1: <illegal opcode> hashCode : (Lcom/d17emo/demo/RecordDemo;)I
// 6: ireturn
// Line number table:
// Java source line number -> byte code offset
// #3 -> 0
// Local variable table:
// start length slot name descriptor
// 0 7 0 this Lcom/d17emo/demo/RecordDemo;
}
/**
* 通过生成的对应getter方法获取属性值进行比较
* 引用类型通过Obejcts.equals()方法比较,基本类型通过==进行比较
*/
public final boolean equals(Object o) {
// Byte code:
// 0: aload_0
// 1: aload_1
// 2: <illegal opcode> equals : (Lcom/d17emo/demo/RecordDemo;Ljava/lang/Object;)Z
// 7: ireturn
// Line number table:
// Java source line number -> byte code offset
// #3 -> 0
// Local variable table:
// start length slot name descriptor
// 0 8 0 this Lcom/d17emo/demo/RecordDemo;
// 0 8 1 o Ljava/lang/Object;
}
public String name() {
return this.name;
}
public Integer age() {
return this.age;
}
}
不可变数据
record类为了不可变数据这一原则做了以下的限制:
record类不支持继承,它的父类已经被隐式的设置为Record类,但是可以实现接口record类被转换为final修饰的普通类,不支持子类,也不能是抽象类record类的成员变量都被final修饰,一旦初始化就不能够修改record类不能声明native方法
透明载体
通过反编译我们可以看到record类帮我们内置了很多方法的缺省实现:
- 构造方法:提供了全部成员变量的构造方法
**toString()**方法:先拼接[+类名称, 之后循环拼接field 名称=值, 最后以]结尾**hashcode()**方法:对于每一个field, 使用对应的hashCode()方法取出哈希值拼接到一起**equals()**方法:通过生成的对应getter方法获取属性值进行比较,引用类型通过Obejcts.equals()方法比较,基本类型通过==进行比较- 成员变量的读取方法:方法名为变量名称
这些缺省方法的具体实现逻辑推理可以参考:https://cloud.tencent.com/developer/article/1813369
透明载体的意思就是我们即可以使用缺省实现,也可以通过override重写这些方法
而如果我们需要在构造方法中进行一些校验的话,例如年龄必须大于0,那么record类的构造方法写法为:
public RecordDemo {
if (age <= 0) {
throw new IllegalArgumentException("年龄必须大于0");
}
}
可以看到,上面的构造方法既没有参数也没有在构造方法中对成员变量进行赋值,因为record类中的成员变量没有提供相关的set方法,为了确保在初始化的时候会对所有的成员变量进行赋值,所以自动帮我们在构造方法中加上对应的处理,所以我们编译之后构造方法就变成了下面这样:
public RecordDemo(String name, Integer age) {
if (age.intValue() <= 0)
throw new IllegalArgumentException(");
this.name = name;
this.age = age;
}
上面的构造函数写法public RecordDemo{...}被称为Compact Constructor(紧凑型构造),它的目的仅仅是让我们编写校验逻辑
与Lombok比较
Lombok更加灵活,配置是否可变、getter/setter、构造函数等方法更加灵活,使用场景更加丰富record由于是JDK原生支持的方式,所以适配性更好也更加简洁
Instanceof Pattern Matching:提供更强大的模式匹配功能
instanceof关键字主要用来判断指定对象是否是某个类的实例。通常情况下我们方法定义的是一个接口类型或者父类,我们可以根据instanceof判断传入的对象具体属于哪个子类,方便我们做出对应的处理。
下面是JDK8我们代码中的处理:
public void consumeMessage(PersonChangeMessage msg) {
PersonStatusChangeModel model = msg.getModel();
if (model instanceof PersonAddedModel) {
// 机构增加单人
PersonAddedModel personAddedModel = (PersonAddedModel) model;
// {...}对应处理
} else if (model instanceof PersonsAddedModel) {
// 机构增加多人
PersonsAddedModel personsAddedModel = (PersonsAddedModel) model;
// {...}对应处理
} else if (model instanceof PersonRemovedModel) {
// 机构删除单人
PersonRemovedModel personRemovedModel = (PersonRemovedModel) model;
// {...}对应处理
} else if (model instanceof PersonsRemovedModel) {
// 机构删除多人
PersonsRemovedModel personsRemovedModel = (PersonsRemovedModel) model;
// {...}对应处理
}
}
旧语法的使用过程分为三步:
model instanceof PersonAddedModel判断对象是否属于当前类型(PersonAddedModel) model将对象强制类型转换为当前类型PersonAddedModel personAddedModel声明一个新的变量接受转换后的对象
这样不仅代码冗余臃肿,且容易出错
而在JDK16之后使用新instanceof语法可以将以上代码改写为下面:
public void consumeMessage(PersonChangeMessage msg) {
PersonStatusChangeModel model = msg.getModel();
if (model instanceof PersonAddedModel personAddedModel) {
// 机构增加单人
// {...}对应处理
} else if (model instanceof PersonsAddedModel personsAddedModel) {
// 机构增加多人
// {...}对应处理
} else if (model instanceof PersonRemovedModel personRemovedModel) {
// 机构删除单人
// {...}对应处理
} else if (model instanceof PersonsRemovedModel personsRemovedModel) {
// 机构删除多人
// {...}对应处理
}
}
而新语法将这三步融合为一步,即在instanceof判断类型之后增加了变量名称,这样如果instanceof的结果为true,对象将会被强转为当前类型的对象并赋值给我们后面跟的变量名,这样不仅代码更加简洁增强可读性,同时也降低了出错的概率
模式变量的作用范围
instanceof后面跟的变量的作用范围很好理解,就是当instanceof返回为true后的判断条件和对应的代码块。我们可以判断一下下面四个代码块能够通过编译器检查:
if (person instanceof Student student && student.getAge() < 18){ // right
student.study();
}
if (person instanceof Student student || student.getAge() < 18){ // error
student.study();
}
if (person instanceof Student student) { // right
student.study();
}
if (!(person instanceof Student student)) { //right
// ...
} else {
student.study();
}
Switch表达式:增强了Switch语句
表达式与语句
- 表达式:一个表达式(expression)是一个由变量、运算符和方法调用组成的构造,它的计算结果为单个值。如
a + b - 语句:语句相当于自然语言中的句子,一个语句(statement)形成一个完整的执行单元。在语句中我们可以调用方法或使用各种表达式,如
int result = a + b;
新旧switch语法对比
旧switch语句的写法:
int daysInMonth;
switch (month) {
case Calendar.JANUARY: // 旧switch语法每隔case后面都要跟要比较的值和:
case Calendar.MARCH: // 旧语法当我们多个case走相同的处理逻辑时通过不加break来实现
case Calendar.MAY:
case Calendar.JULY:
case Calendar.AUGUST:
case Calendar.OCTOBER:
case Calendar.DECEMBER:
daysInMonth = 31;
break; // 旧switch直到遇到break关键字才会跳出switch语句
case Calendar.APRIL:
case Calendar.JUNE:
case Calendar.SEPTEMBER:
case Calendar.NOVEMBER:
daysInMonth = 30;
break;
case Calendar.FEBRUARY:
if (((year % 4 == 0) && !(year % 100 == 0))
|| (year % 400 == 0)) {
daysInMonth = 29;
} else {
daysInMonth = 28;
}
break;
default:
throw new RuntimeException(
"Calendar in JDK does not work");
}
System.out.println(
"There are " + daysInMonth + " days in this month.");
新switch表达式的写法:
int daysInMonth = switch (month) {
case Calendar.JANUARY,
Calendar.MARCH,
Calendar.MAY,
Calendar.JULY,
Calendar.AUGUST,
Calendar.OCTOBER,
Calendar.DECEMBER -> 31;
case Calendar.APRIL,
Calendar.JUNE,
Calendar.SEPTEMBER,
Calendar.NOVEMBER -> 30;
case Calendar.FEBRUARY -> {
if (((year % 4 == 0) && !(year % 100 == 0))
|| (year % 400 == 0)) {
yield 29;
} else {
yield 28;
}
}
default -> throw new RuntimeException(
"Calendar in JDK does not work");
};
System.out.println(
"There are " + daysInMonth + " days in this month.");
通过对比上面两种写法我们可以看出:
- Switch Expressions(switch表达式):switch表达式允许在switch语句中使用lambda风格的语法进行模式匹配,并直接返回值。需要注意的是,switch表达式必须是详尽的,对于enum类型,如果所有的枚举都已经列举出来了,那么编译器会插入隐式的
default语句,否则,需要显示指定default - Arrow Syntax(箭头语法):使用
->代替之前的:作为标签和表达式之间的分隔符,且无须显式指定break - Multiple Labels(多重标签):可以在一个语句中使用多个标签,以
,分隔,避免了重复的代码块 - Yield Statement(yield 语句):对于复杂的操作可以使用
yield关键字来返回结果值,可以更方便的从switch表达式中返回结果
改进的switch表达式的语法比之前更加清晰和紧凑,它减少了重复的代码和避免了易错的break语句,使代码变得更简洁易读
文本块
文本块(Text Blocks)是JDK15引入的一项特性,它提供了一种更自然、易读的多行字符串表达形式,以避免在Java代码中编写多行字符串时容易产生的转义字符问题和格式化问题。文本块尝试消除转义字符和连接符等影响,使得文字对齐和必要的占位符更加清晰,从而简化多行字符串的代码书写
例如使用字符串输出HTML语句:
String stringBlock =
"<!DOCTYPE html>\n" +
"<html>\n" +
" <body>\n" +
" <h1>\"Hello World!\"</h1>\n" +
" </body>\n" +
"</html>\n";
而使用文本块我们可以简化为:
String textBlock = """
<!DOCTYPE html>
<html>
<body>
<h1>"Hello World!"</h1>
</body>
</html>
""";
System.out.println(
"Here is the text block:\n" + textBlock);
定义
文本块以开始分隔符开始,以结束分隔符结束,开始分隔符是由三个双引号字符"""和后面跟着的零个或多个空格以及行结束符组成的序列,结束分隔符是由"""组成的序列,结束分隔符之前的内容,包括换行符都属于文本块的内容。
需要注意的是开始分隔符必须单独一行,后面跟着的空格和换行符都属于开始分隔符,所以一个文本块至少有两行代码,即使是一个空文本块,开始分隔符和结束分隔符也不能写在同一行里
String textBlock = """
""";
编译
文本块会在编译时转换为字符串对象,所以文本块并不会改变字符串的基本性质和操作,它能够使用字符串支持的所有API和操作方法,例如String::length(),String::formatted()等
文本块的编译过程要经历三个步骤:
- 标准化行终止符:用
LF(\u000A)字符替换所有的行终止符。这样可以防止文本块的值受编辑它的平台的影响(Windows系统使用CR+LF作为结束,Unix系统使用LF作为结束) - 处理空格:删除所有内容行和结束分隔符共享的前置空格和内容行的尾部空格。具体见String::stripIndent()
- 处理转义字符:文本块使用与字符串和字符字面量相同的转义序列集。具体见String::translateEscapes()
新增转义字符
\s:空格转义字符,编译过程中是先删除尾部空格再处理转义字符,所以我们使用\s不仅可以增加一个空格,还可以使该转义字符前的空格全部保留\<line-terminator>:即如果转义符号出现在该行结尾,该行换行符将会被取消。这个转义字符可以将文本块中的上下两行连接为一行,这样可以使代码遵守编码规范提高可读性
Sealed Classes
在JDK17之前,我们如果不想一个类被继承和修改有两种方法:私有类和使用final修饰类,而私有类只能内部使用,final修饰符又完全限制了类的扩展性,所有类都不能继承被修饰的类,所以我们的类就只有两个选择,要么完全开放,要么完全封闭。JDK17引入sealed修饰符来解决这个问题
下面我们先来看以下sealed修饰符的用法:
sealed interface User permits Student, Teacher, Admin {}
final class Student implements User{}
sealed class Teacher implements User{}
no-sealed class Admin implements User{}
permits语句放在extends和implements语句之后声明
我们称sealed修饰的类为封闭类,permits后面跟着的类叫做许可类
许可类的声明需要满足下面三个条件:
- 许可类必须和封闭类处于同一模块或同一包空间里,即在编译的时候封闭类必须可以访问它的许可类
- 许可类必须是封闭类的直接扩展类
- 许可类必须声明是否继续保持封闭
- 声明为
final:关闭扩展性 - 声明为
sealed:受限制的扩展性 - 声明为
non-sealad:不受限制的扩展性
- 声明为
类的扩展性总结
限定类的扩展性方法有以下四种:
- 私有类
- 使用
final修饰符 - 使用
sealed修饰符 - 不限制扩展性
在我们日常的接口设计和编码实践中,为了保持类的扩展可控,应该尽量按照序号由低到高的优先级实现
库级别的改动
JPMS模块化
- JPMS(Java Platform Module System:模块化的本质是将一个大型项目拆分为若干个模块,每个模块都是独立的单元,且不同的模块之间可以互相调用和引用
class是字段和方法的集合,package是class的集合,module(替代了jar包)是package的集合- 每个
module都包含了一个module-info.class文件,这个文件内定义了module的相关信息以及和外部的关系
详细介绍可参考:http://www.flydean.com/jdk9-java-module-jpms/
库的改进
不可变集合的创建:介绍如何创建不可变集合以提高其安全性
JDK9中增加了List.of()、Set.of()、Map.of()和Map.ofentries()等方法来创建不可变集合
List.of();
List.of("Hello", "World");
List.of(1, 2, 3);
Set.of();
Set.of("Hello", "World");
Set.of(1, 2, 3);
Map.of();
Map.of("Hello", 1, "World", 2);
方法重载
/**
* Returns an unmodifiable list containing zero elements.
*
* See <a href="#unmodifiable">Unmodifiable Lists</a> for details.
*
* @param <E> the {@code List}'s element type
* @return an empty {@code List}
*
* @since 9
*/
@SuppressWarnings("unchecked")
static <E> List<E> of() {
return (List<E>) ImmutableCollections.EMPTY_LIST;
}
static <E> List<E> of(E e1) {
return new ImmutableCollections.List12<>(e1);
}
static <E> List<E> of(E e1, E e2) {
return new ImmutableCollections.List12<>(e1, e2);
}
static <E> List<E> of(E e1, E e2, E e3) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3);
}
@SafeVarargs
@SuppressWarnings("varargs")
static <E> List<E> of(E... elements) {
switch (elements.length) { // implicit null check of elements
case 0:
@SuppressWarnings("unchecked")
var list = (List<E>) ImmutableCollections.EMPTY_LIST;
return list;
case 1:
return new ImmutableCollections.List12<>(elements[0]);
case 2:
return new ImmutableCollections.List12<>(elements[0], elements[1]);
default:
return ImmutableCollections.listFromArray(elements);
}
}
可变参数特点:
- 使用可变参数的时候,实际上是先创建了一个数组,该数组的大小就是参数的个数,然后使用参数初始化数组再传递给被调用的方法
- 当存在于可变参数形成重载的固定参数方法的时候,会优先固定参数的方法执行
我们知道可变参数其实已经包括上面的这几种情况了,而且方法的实现都是一样的,这样岂不是重复了,在有具体参数匹配的情况下也不会走到可变参数,为什么不直接把指定参数的方法去掉呢?这里设计者给出了答案
JEP 269: Convenience Factory Methods for Collections
These will include varargs overloads, so that there is no fixed limit on the collection size. However, the collection instances so created may be tuned for smaller sizes. Special-case APIs (fixed-argument overloads) for up to ten of elements will be provided. While this introduces some clutter in the API, it avoids array allocation, initialization, and garbage collection overhead that is incurred by varargs calls. Significantly, the source code of the call site is the same regardless of whether a fixed-arg or varargs overload is called.
这些将包括可变参数重载,因此最终生成的集合大小没有固定限制。然而,这样创建集合实例可以调整为更小的尺寸。将提供最多十个元素的特殊情况 API(固定参数重载)。
虽然这会给 API 带来一些混乱,但它避免了由 可变参数 调用引起的数组分配、初始化和垃圾收集开销。
值得注意的是,无论调用的是固定参数重载还是可变参数重载,调用站点的源代码都是相同的。
Stream API的增强:新的Stream方法和操作
JDK9中Stream中增加了ofNullable``dropWhile``takeWhile``iterate等方法
- takeWhile:遍历返回元素,遇到不满足的结束
- dropWhile:遍历跳过元素,遇到不满足的结束
- ofNullable:支持创建全null的Stream,避免空指针
- iterate:可以重载迭代器
// takeWhile() 方法示例
List<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6)
.takeWhile(n -> n < 4)
.collect(Collectors.toList());
System.out.println("takeWhile 示例:" + numbers); // 输出:[1, 2, 3]
// dropWhile() 方法示例
List<Integer> numbers2 = Stream.of(1, 2, 3, 4, 5, 6)
.dropWhile(n -> n < 4)
.collect(Collectors.toList());
System.out.println("dropWhile 示例:" + numbers2); // 输出:[4, 5, 6]
// ofNullable() 方法示例
String name = null;
List<String> names = Stream.ofNullable(name)
.collect(Collectors.toList());
System.out.println("ofNullable 示例:" + names); // 输出:[]
// iterate() 方法的重载示例
List<Integer> evenNumbers = Stream.iterate(0, n -> n < 10, n -> n + 2)
.collect(Collectors.toList());
System.out.println("iterate 重载示例:" + evenNumbers); // 输出:[0, 2, 4, 6, 8]
Collectors中增加了filtering``flatMapping方法
HttpClient重写
- JDK11之前的Java原生HttpClient接口使用
HttpURLConnection connection = null;
InputStream is = null;
BufferedReader br = null;
String result = null;// 返回结果字符串
try {
// 创建远程url连接对象
URL url = new URL(httpurl);
// 通过远程url连接对象打开一个连接,强转成httpURLConnection类
connection = (HttpURLConnection) url.openConnection();
// 设置连接方式:get
connection.setRequestMethod("GET");
// 设置连接主机服务器的超时时间:15000毫秒
connection.setConnectTimeout(15000);
// 设置读取远程返回的数据时间:60000毫秒
connection.setReadTimeout(60000);
// 发送请求
connection.connect();
// 通过connection连接,获取输入流
if (connection.getResponseCode() == 200) {
is = connection.getInputStream();
// 封装输入流is,并指定字符集
br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
// 存放数据
StringBuffer sbf = new StringBuffer();
String temp = null;
while ((temp = br.readLine()) != null) {
sbf.append(temp);
sbf.append("\r\n");
}
result = sbf.toString();
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (null != br) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != is) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
connection.disconnect();// 关闭远程连接
}
return result;
}
- okHttp发送get请求
private static final OkHttpClient OKHTTP_CLIENT = new OkHttpClient.Builder()
.connectTimeout(120, TimeUnit.SECONDS)
.readTimeout(120,TimeUnit.SECONDS)
.writeTimeout(120,TimeUnit.SECONDS)
.build();
// 拼接参数
String requestUrl = reqUrl+stringBuilder;
// 发送请求
Request request = new Request.Builder()
.url(requestUrl)
.build();
try{
Response response = OKHTTP_CLIENT.newCall(request).execute();
return response.body().string();
}catch (Exception e){
throw new RuntimeException("HTTP GET同步请求失败 URL:"+reqUrl,e);
}
- JDK11之后新代码
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.hao123.com"))
.build();
// 同步
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
// 异步
client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println)
.join();
性能
其实第一章中的语法改进都或多或少的能够提升应用的性能,但是本小节我们探究以下平时在编码过程中感受不到的性能提升--垃圾收集器性能提升
现代垃圾收集器主要关注的性能指标有两个:
- 吞吐量(Throughput):吞吐量是指处理器处理应用程序用时占总用时的比例,例如吞吐量99/100是指在100s的程序运行期间,处理应用程序用时99s,GC用时1s
- 暂停时间(Pause Times):暂停时间是指在GC的过程中需要STW的时间,这段时间处理器完全用来执行GC线程。相应的有平均暂停时间和最大暂停时间等
- 资源占用情况:GC 使用的额外资源
简单来说就是吞吐量越大越好,暂停时间越短越好
不幸的是”高吞吐量”和”低暂停时间”是一对相互竞争的目标(矛盾)
- 因为如果选择以吞吐量优先,那么必然需要降低内存回收的执行频率,但是这样会导致 GC 需要更长的暂停时间来执行内存回收。
- 相反的,如果选择以低延迟优先为原则,那么为了降低每次执行内存回收时的暂停时间,也只能频繁地执行内存回收,但这又引起了年轻代内存的缩减和导致程序吞吐量的下降。
所以一个 GC 算法只可能针对两个目标之一(即只专注于较大吞吐量或最小暂停时间),或尝试找到一个二者的折衷。目前一般情况下都是在最大吞吐量优先的情况下,降低暂停时间
各版本GC的改动
- JDK9:将
G1设置为默认垃圾收集器G1收集器的目标是能够建立停顿时间模型(Pause Time Model)
- JDK10:
G1引入并行FULL GC算法降低延迟- 之前
G1的FULL GC是使用serial old GC的
- 之前
- JDK11:推出新一代垃圾收集器
ZGC(实验性)ZGC的目标是在尽可能不影响吞吐量的前提下,实现在任意堆大小下都可以把垃圾收集的停顿时间控制在十毫秒以内的低延迟
- JDK14:删除
CMS垃圾收集器,弃用ParallelScavenge + SerialOld GC的垃圾收集算法组合,并将ZGC垃圾收集移植到macOS和Windows平台 - JDK15:
ZGC转正,Shenandoah转正(openJDK中默认没有该收集器),但默认GC仍是G1 - JDK16:增强
ZGC,ZGC获得了 46个增强功能 和25个错误修复,控制STW时间不超过10毫秒
整体比较
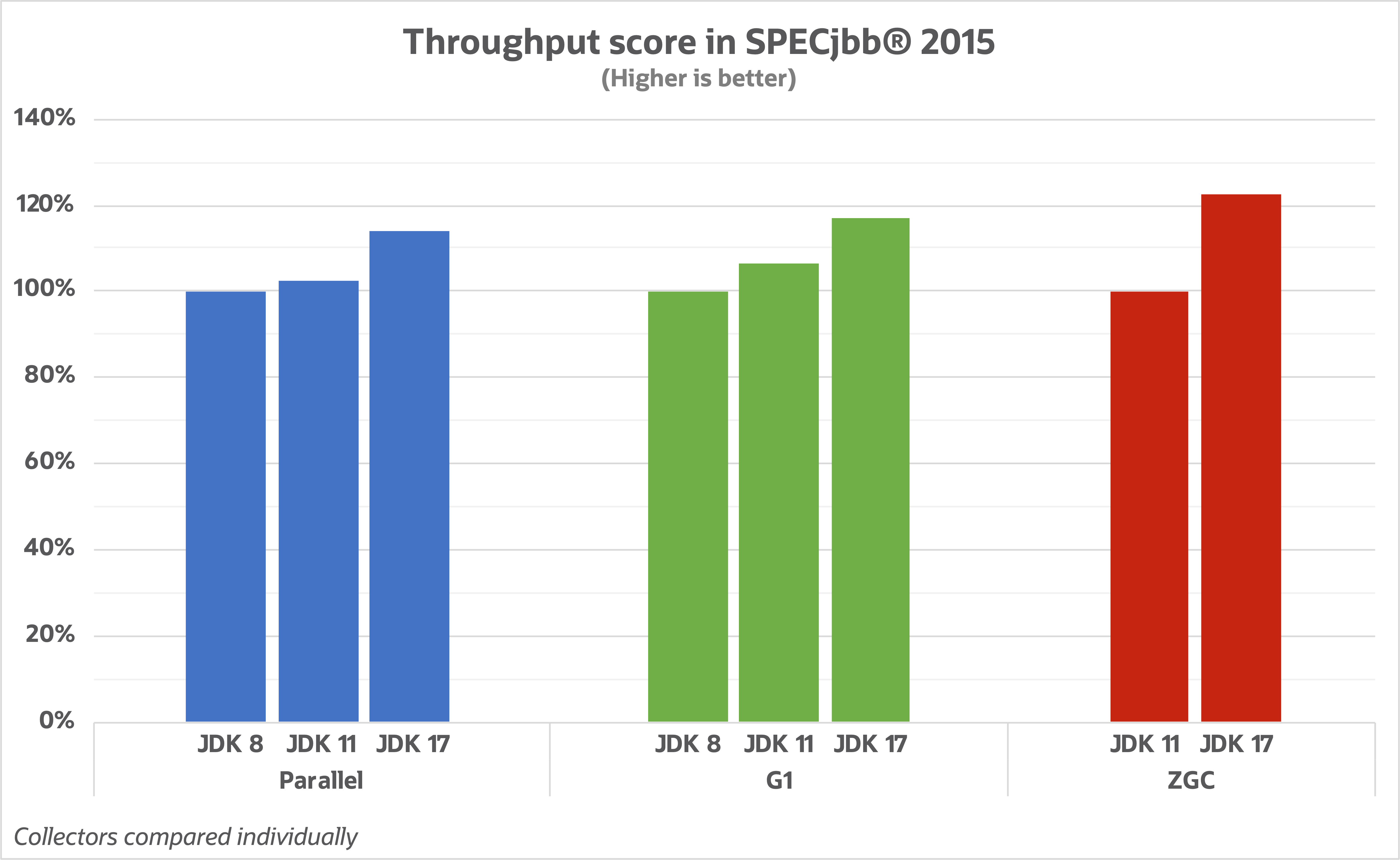
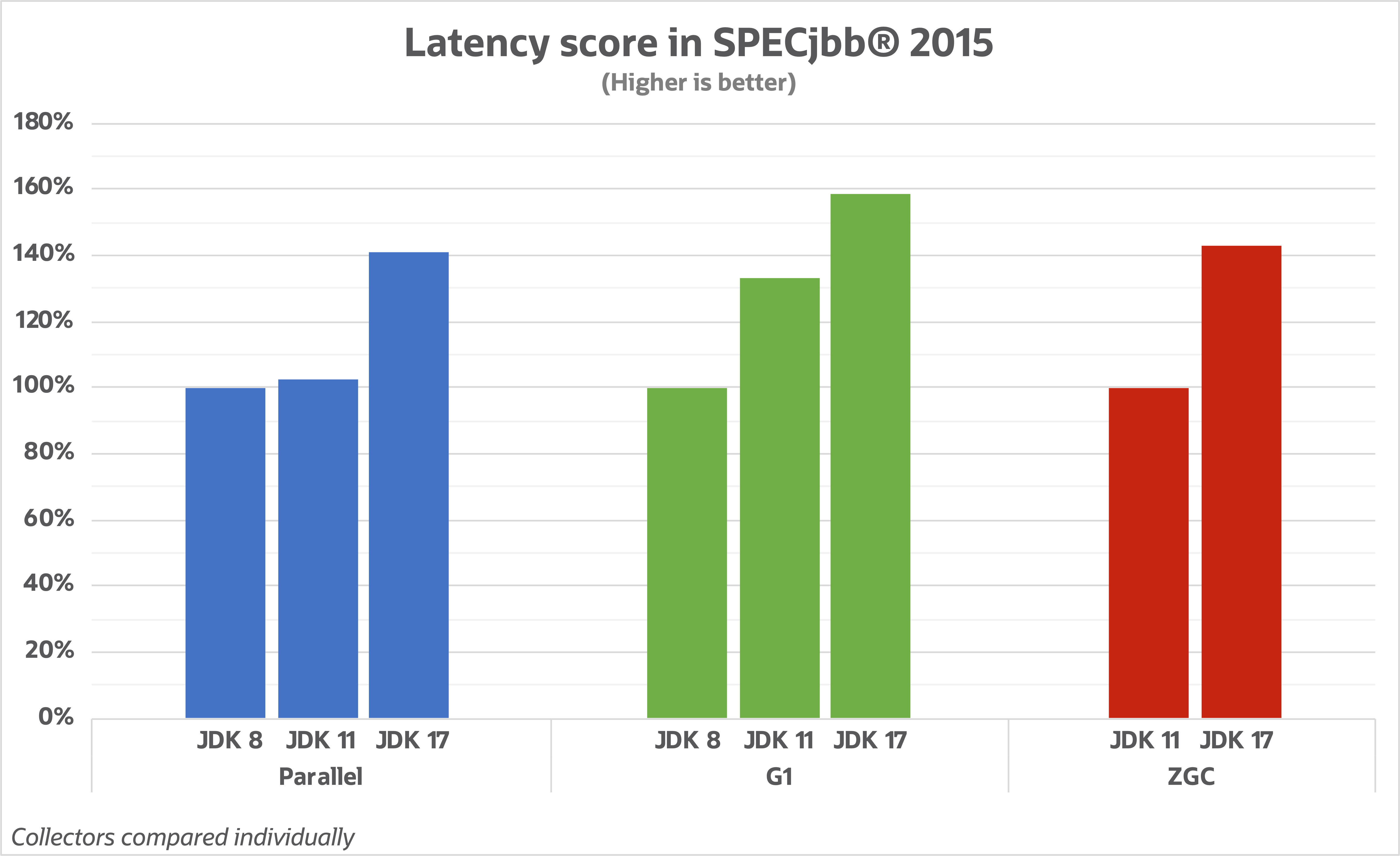
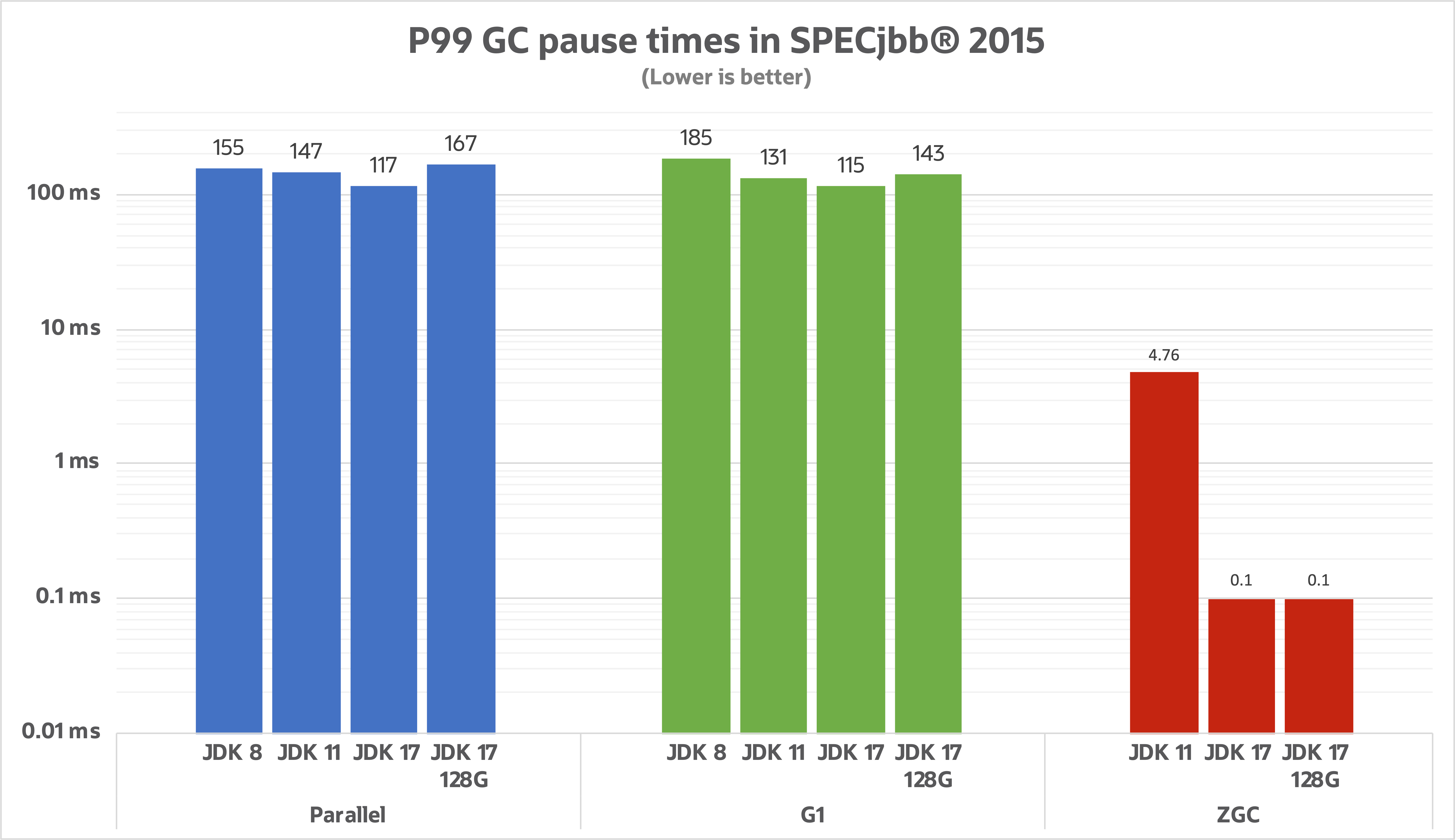
整体的进步我们可以看下面这几张图:
- 吞吐量
- 延迟
- 暂停时间
- 内存占用
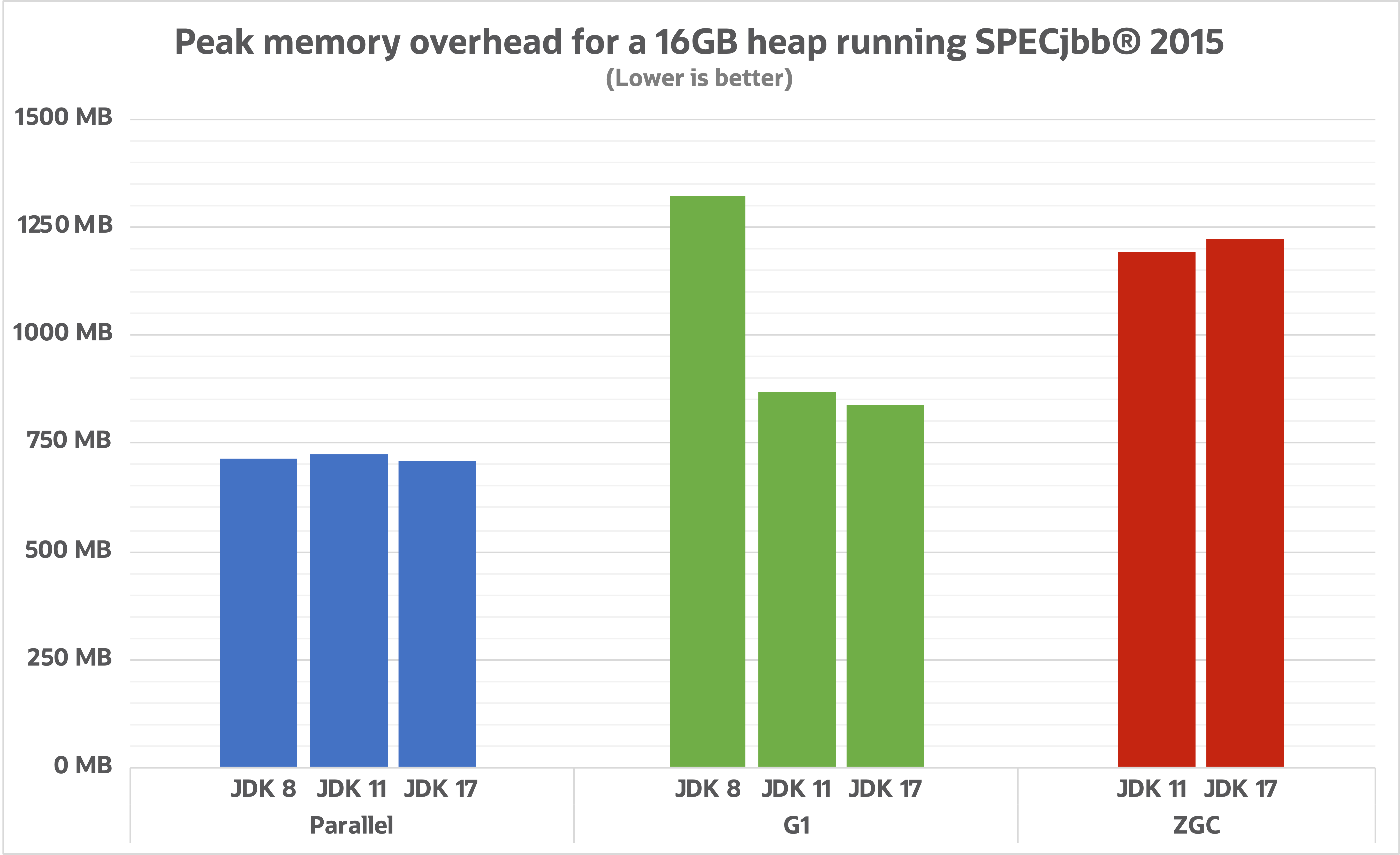
工具和开发环境改进
更清晰的NPE
空指针异常NullPointExceptions简称NPE,是运行时异常的一种,也是我们最常碰到的异常之一。
a.b.c.i == 99;
上面这段代码在JDK14之前如果出现空指针异常的提示是这样的
Exception in thread "main" java.lang.NullPointerException
at Prog.main(Prog.java:5)
但是在JDK14通过-XX:+ShowCodeDetailsInExceptionMessages参数开启详细的异常信息后提示是这样的:
Exception in thread "main" java.lang.NullPointerException:
Cannot read field "c" because "a.b" is null
at Prog.main(Prog.java:5)
JDK14改进NullPointExceptions异常的可读性,使开发人员能够更好的定位null变量的信息
在JDK17中该特性默认开启
JShell:介绍交互式Java编程工具的用法和优点
JShell是在jdk9引入的交互式编程环境工具,交互式即执行Java代码立即获得执行结果
在命令行中输入jshell后会打印出jshell的版本和欢迎语:
PS C:\Users\HYC\IdeaProjects\demo> jshell
| 欢迎使用 JShell -- 版本 17.0.8
| 要大致了解该版本, 请键入: /help intro
jshell>
然后就进入到jshell模式了,根据提示我们可以输入/help intro可以看到官方的介绍:
jshell> /help intro
|
| intro
| =====
|
| 使用 jshell 工具可以执行 Java 代码,从而立即获取结果。
| 您可以输入 Java 定义(变量、方法、类等等),例如:int x = 8
| 或 Java 表达式,例如:x + x
| 或 Java 语句或导入。
| 这些小块的 Java 代码称为“片段”。
|
| 这些 jshell 工具命令还可以让您了解和
| 控制您正在执行的操作,例如:/list
|
| 有关命令的列表,请执行:/help
使用/exit命令退出jshell模式
jshell> /exit
| 再见
PS C:\Users\HYC\IdeaProjects\demo>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号